{kind=link}
[ad_1]
February 1, 2023

As the sphere of machine studying (ML) continues to evolve and its impression on society and numerous points of our lives grows, it’s turning into more and more vital for practitioners and innovators to think about a broader vary of views when constructing ML fashions and functions. This want is driving the necessity for a extra versatile and scalable ML infrastructure.
At Spotify, we strongly imagine in a various and collaborative strategy to constructing ML functions. Gone are the times when ML was the area of solely a small group of researchers and engineers. We need to democratize our ML efforts such that contributors of all backgrounds, together with engineers, knowledge scientists, and researchers, can leverage their distinctive views, abilities, and experience to additional ML at Spotify. As a consequence, we anticipate to see a rise in well-represented ML developments at Spotify within the coming years — and the suitable infrastructure will play a vital position in supporting this progress.
Spotify based its machine studying (ML) platform in 2018 to offer a gold customary for dependable and accountable manufacturing ML. As an ML platform crew, we purpose to empower our customers to spend much less time sustaining bespoke ML infrastructure and extra time specializing in fixing enterprise issues by novel mannequin growth.
Our centralized infrastructure now serves over half of our inside ML practitioners and ML groups. Internal analysis has proven, nevertheless, that our platform instruments aren’t at the moment completely fitted to all dimensions of ML practitioners. While nearly all of our ML engineers use our centralized tooling, fewer knowledge and analysis scientists do. We imagine fixing the next consumer wants may help all dimensions of ML innovators at Spotify:
- Broadening manufacturing assist for ML frameworks past TensorFlow to assist novel ML options for Spotify
- Providing a extra user-friendly manner for customers to entry GPU and distributed compute
- Accelerating the consumer journey for ML analysis and prototyping
- Providing options to productionize extra superior ML paradigms, reminiscent of reinforcement studying (RL) and graph neural networks (GNN) workflows
Spotify’s ML infrastructure as we speak
Our objective for Spotify’s ML Platform has all the time been to create a seamless consumer expertise for ML practitioners who need to take an ML software from growth to manufacturing. In early 2020, our ML Platform expanded to cowl the ML manufacturing workflow for Spotify’s ML practitioners with 4 core product choices:
- ML Home, a spot the place ML engineers can retailer ML venture info and entry metadata associated to the ML software lifecycle
- Jukebox, our answer for powering function engineering based mostly on TensorFlow Transform
- Spotify Kubeflow, our managed model of the open-source Kubeflow Pipelines platform with TensorFlow Extended (TFX) because the ML workflow standardization
- Salem, our customary for mannequin serving and on-device ML functions
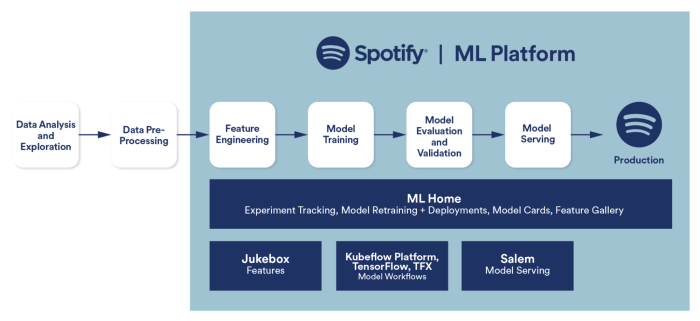
Lifecycle of an ML venture at Spotify
ML at Spotify resembles a funnel. At the widest finish, we’ve a giant quantity of ML actions undertaken by knowledge and analysis scientists to rapidly show high-potential concepts. Their duties, instruments, and strategies are numerous and heterogeneous and tough to standardize — actually, it’s suboptimal to standardize their strategies at this level within the lifecycle. As the funnel narrows and high-potential concepts show out, knowledge engineers and ML engineers take over. Standardizing their duties and instruments is an optimization each from a consumer expertise standpoint and from a enterprise perspective; ML engineers can spend much less time constructing redundant tooling, and our enterprise advantages from having confirmed, dependable, and progressive ML concepts launched to manufacturing sooner.
We constructed our platform for ML engineers first as a result of their use circumstances and desires have been simpler to standardize. But that focus got here at a value: it meant much less flexibility for innovation on the earlier phases of the lifecycle.
In 2022, our crew got down to refresh the two-to-three-year technique and imaginative and prescient for Spotify’s ML Platform. A giant element of that technique was to raised serve the wants of innovators centered on the sooner phases of the ML lifecycle and allow a seamless transition from growth to manufacturing.
The subsequent evolution of Spotify’s ML infrastructure
At Spotify, ML practitioners all share the same ML consumer journey. They need to begin their ML initiatives by prototyping on their native machines or in a pocket book, and so they want entry to massive computing sources like dozens of CPUs or GPUs. They like to simply create and scale end-to-end ML workflows in Python, entry a various set of contemporary ML libraries, and seamlessly combine with the remainder of the Spotify engineering ecosystem with minimal code adjustments and infrastructure data.

To higher meet the wants of our customers and enhance productiveness throughout your complete ML lifecycle, we’d like versatile infrastructure that meets nearly all of our customers the place they already are. We want a platform that helps day-one Spotifiers really feel productive — no matter in the event that they’re an information scientist in customer support testing concepts quick or an ML engineer on a complicated personalization crew focused on hardening manufacturing workflows. Our present platform expertise is closely weighted in direction of a single consumer journey: an ML engineer utilizing TensorFlow/TFX for supervised studying manufacturing functions. To higher assist our goal market of a broader vary of constituents, we have to decrease the barrier to entry and embrace extra numerous ML tooling whereas sustaining scalability and efficiency in end-to-end ML workflows.
Introducing Ray
After in depth prototyping and investigation, we imagine Ray addresses these wants.
Ray is an open-source, unified framework for scaling AI and Python functions. It’s tailor-made for ML growth with its wealthy ML ecosystem integration. It simply scales compute-heavy workloads reminiscent of function preprocessing, deep studying, hyperparameter tuning, and batch predictions — all with minimal code adjustments. Ray is extensively adopted throughout the ML trade. OpenAI cofounder and CTO Greg Brockman stated at Ray Summit 2022, “We’re using [Ray] to train our largest models. So it has been very, very helpful for us in terms of just being able to scale up to a pretty unprecedented scale and to not go crazy.” With Ray, ML builders now not must utterly change their code and framework of selection to realize scale for manufacturing functions, easing the transition from native growth to a distributed computing surroundings.
Incorporating Ray into the Spotify ecosystem
We constructed a centralized Spotify-Ray platform as a result of we would like our ML practitioners to resolve ML issues and never need to commit their time to managing Ray or underlying infrastructure. The platform consists of server-side infrastructure, client-side SDK and CLI, and integrations with the remainder of the Spotify ecosystem. We designed it to cater to the wants of all forms of ML practitioners, not solely ML engineers. We optimized for accessibility, flexibility, availability, and efficiency.

Accessibility
We wished customers to have an incredible onboarding expertise with a gradual studying curve. We optimized for progressive disclosure of complexity, offering wise defaults for frequent use circumstances and versatile abstractions over underlying Ray and Kubernetes complexity that accommodate each new customers and “power users” alike. This lets ML practitioners deal with their enterprise logic immediately. With a single CLI command, customers can create their very own Ray cluster with preinstalled ML instruments, ready-to-run pocket book tutorials, VS Code server for in-browser enhancing, and SSH entry.
$ sp-ray create cluster my-cluster
-n ray-playground
--with-tutorials
--vscode-server
--gpus-per-worker 1
Created cluster my-cluster in namespace ray-playground
Uploaded tutorial notebooks
sp-ray model 0.3.0
server ray model 2.2.0
server python model 3.8.13
service account ...
head IP 1.2.3.4
server ray://1.2.3.4:10001
dashboard http://1.2.3.4:8265
pocket book server http://1.2.3.4:8081
OpenVSCode server http://1.2.3.4:3000
staff 1
head group
replicas 1
CPUs 15
GPUs 0
reminiscence 48Gi
employee teams
employee
replicas 1
CPUs 15
GPUs 1
GPU kind t4
reminiscence 48Gi
Users can checklist, describe, scale, customise, and delete Ray clusters too.
$ sp-ray get cluster -n ray-playground
NAME CREATED WORKERS
my-cluster 2 seconds in the past 1
# present helpful, human-readable cluster data
$ sp-ray describe cluster -n ray-playground my-cluster
sp-ray model 0.3.0
server ray model 2.2.0
server python model 3.8.13
service account ...
head IP 1.2.3.4
server ray://1.2.3.4:10001
dashboard http://1.2.3.4:8265
pocket book server http://1.2.3.4:8081
OpenVSCode server http://1.2.3.4:3000
staff 1
head group
replicas 1
CPUs 15
GPUs 0
reminiscence 48Gi
employee teams
employee
replicas 1
CPUs 15
GPUs 1
GPU kind t4
reminiscence 48Gi
# simple to customise primary choices
$ sp-ray create cluster my-cluster
--cpus-in-head 4
--memory-in-head 10Gi
--gpus-per-worker 1
--worker-gpu-type a100
# scale employee teams
$ sp-ray scale cluster -n ray-playground my-cluster
--worker-group group1 --replicas N
# permit K8s YAML for superior config like a number of employee teams
$ sp-ray create cluster -n ray-playground my-cluster
--file ray-cluster.yaml
$ sp-ray delete cluster -n ray-playground my-clusterUnder the hood, we use Google Kubernetes Engine (GKE) and the open-source KubeRay operator. Our CLI creates a customized Kubernetes Ray cluster useful resource that tells KubeRay to create a brand new Ray cluster. Users begin with a shared, playground namespace to study and experiment with minimal setup. Once they’re prepared, they create their namespace. Our multi-tenancy crew administration course of grants permissions, configures sources, and manages contributors. It generates all Kubernetes sources based mostly on a crew configuration file and deploys them to the cluster to arrange the namespace.

In addition to the CLI, we created a Python SDK with equal options. The SDK lets customers programmatically handle their Ray clusters.
import time
from datetime import datetime
from typing import Final
from spotify_ray.logger import LOGGER
from spotify_ray.fashions.ray_cluster import RayCluster
CLUSTER_NAME: Final[str] = f"sp-ray-test-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
NAMESPACE: Final[str] = "hyperkube"
NUM_WORKERS: Final[int] = 1
def foremost():
# Create new cluster
cluster = RayCluster.create_cluster(
identify=CLUSTER_NAME,
namespace=NAMESPACE,
cpus_in_head=1,
memory_in_head="2Gi",
cpus_per_worker=1,
memory_per_worker="2Gi",
worker_replicas=NUM_WORKERS,
await_ready=True, # makes the operate block till cluster is prepared
)
LOGGER.data(f"Cluster head IP: ${cluster.head_ip}")
LOGGER.data("Cluster has ${cluster.num_workers} staff")
cluster.scale_worker_group(worker_group="employee", replicas=2)
time.sleep(60)
# Get an current cluster
cluster = RayCluster.get_cluster(identify=CLUSTER_NAME, namespace=NAMESPACE)
cluster.delete()
if __name__ == "__main__":
foremost()Flexibility
Users can simply make use of state-of-the-art ML libraries and choose computing sources to assist their workloads for analysis and prototyping. As a results of utilizing Ray, our platform helps all the main ML frameworks like PyTorch, TensorFlow, and XGBoost. Computing useful resource configuration is abstracted in a unified and user-friendly manner. If customers don’t need the default computing sources, they will simply customise them. For instance, they will request a particular kind and variety of GPUs.
Availability
We construct on prime of managed GKE’s availability as an alternative of managing Kubernetes clusters ourselves. We isolate workloads by giving every Ray employee its personal GKE node, and we isolate groups by giving every their very own Kubernetes namespace.
Performance
We leverage GKE’s picture streaming function to hurry up picture pulls. We’ve decreased the time it takes to drag massive GPU-based container photographs from a number of minutes to only a few seconds.
A Ray-based path to manufacturing
In the identify of constructing a minimal viable model of Spotify-Ray, we selected to prioritize early-stage prototyping and experimentation — the “mouth” of the funnel, in different phrases. However, we see promise in Ray because the spine of a strong path to manufacturing for ML practitioners at Spotify. With Spotify-Ray’s native Flyte integration and high-level APIs within the works to streamline and speed up canonical MLOps duties, e.g., knowledge loading, artifact logging, experiment monitoring, and pipeline orchestration, we imagine Ray can considerably shorten the time-to-production for ML functions at Spotify. We’re excited to work along with our inside ML practitioners to realize this imaginative and prescient.

Use case: Graph studying for content material suggestions
In a current analysis venture, Spotify’s Tech Research crew, a beforehand underinvested ML Platform finish consumer, experimented with utilizing graph studying applied sciences for suggestions. Unlike previous analysis initiatives which are sometimes prototyped with advert hoc tooling after which applied for manufacturing situations, the graph studying implementation wanted to be production-ready to rapidly assess GNN for Spotify’s enterprise use circumstances. Our ML researchers wanted infrastructure that was versatile and straightforward to productionize rapidly. This prompted Tech Research to make use of graph studying on Spotify-Ray to generate content material suggestions.
Following promising offline outcomes on inside datasets, the Tech Research crew ran an A/B take a look at to know how GNN-based algorithms modified our house web page’s “Shows you might like” suggestions. Conducting these A/B checks was difficult because the GNN workflows are completely different from typical ML workflows. Tech Research adopted Spotify-Ray for his or her infrastructural wants to beat these challenges and applied a set of parts to coach and deploy GNN fashions at scale.
- Data creation (graph development)
Constructing graphs for real-world functions is an iterative course of and requires instruments that may simply remodel massive quantities of information with easy Python capabilities. We leveraged Ray Datasets to create the graph from our knowledge warehouse. Ray Datasets present versatile APIs to carry out frequent transformations reminiscent of mapping on distributed knowledge.
- Feature preprocessing
The graph constructed within the earlier step consisted of nodes and edges together with corresponding options. We leveraged Ray AIR’s default preprocessors and prolonged their base API to carry out function transformations reminiscent of standardization, categorical transforms, bucketing, and so on. - Graph studying
We feed the graph and preprocessed options right into a graph studying algorithm applied in PyG. Ray trainers simply prolong to completely different ML frameworks like PyG and permit us to seamlessly distribute our coaching. - Inference at scale and analysis
Finally, we applied customized predictors for batch prediction and evaluators utilizing Ray Datasets.
Using the above parts, this crew constructed an end-to-end pipeline for producing present suggestions utilizing GNN-based fashions and efficiently launched an A/B take a look at in lower than three months, a feat that was extraordinarily difficult for Tech Research up to now given the prior supported ML infrastructure. The A/B take a look at resulted in important metric enhancements and improved consumer expertise on our house web page’s “Shows you might like.”
Spotify’s ML practitioners’ demand for PyTorch has grown significantly, notably for rising use circumstances within the NLP and GNN areas. We plan to make use of Ray to assist and scale PyTorch to fulfill this rising demand and assist our numerous customers really feel productive, irrespective of their position on the crew.
While bringing in a brand new framework carries the chance of fragmentation, with higher foundational constructing blocks in place, we will work towards making a extra versatile, consultant, and accountable ML platform expertise that comprehensively unleashes ML innovation at Spotify.
Our work bringing Ray into the Spotify ecosystem wouldn’t have been doable with out the implausible work of the ML Workflows crew at Spotify, our teammates from ML Platform, and beneficiant collaboration with the Anyscale crew. Thank you to the people whose work made unleashing ML innovation at Spotify doable: Jonathan Jin, Mike Seid, Joshua Baer, Richard Liaw, Dmitri Gekhtman, Abdullah Mobeen, Maria Cipollone, Olga Ianiuk, Sara Leary, Grace Glenn, Omar Delarosa, Maisha Lopa, Shawn Lin, Andrew Martin, and Union.ai for his or her assist on Flyte integration.
PyTorch, the PyTorch brand, and any associated marks are emblems of The Linux Foundation.
TensorFlow, the TensorFlow brand, and any associated marks are emblems of Google Inc.
Tags: machine studying
[ad_2]