{kind=link}

October 21, 2024

With the fields of machine studying (ML) and generative AI (GenAI) persevering with to quickly evolve and broaden, it has develop into more and more necessary for innovators on this subject to anchor their mannequin improvement on high-quality knowledge.
As one of many foundational groups at Spotify centered on understanding and enriching the core content material in our catalogs, we leverage ML in a lot of our merchandise. For instance, we use ML to detect content material relations so a brand new observe or album will probably be mechanically positioned on the appropriate Artist Page. We additionally use it to investigate podcast audio, video, and metadata to determine platform coverage violations. To energy such experiences, we have to construct a number of ML fashions that cowl whole content material catalogs — lots of of tens of millions of tracks and podcast episodes. To implement ML at this scale, we wanted a method to gather high-quality annotations to coach and consider our fashions. We needed to enhance the information assortment course of to be extra environment friendly and linked and to incorporate the appropriate context for engineers and area consultants to function extra successfully.
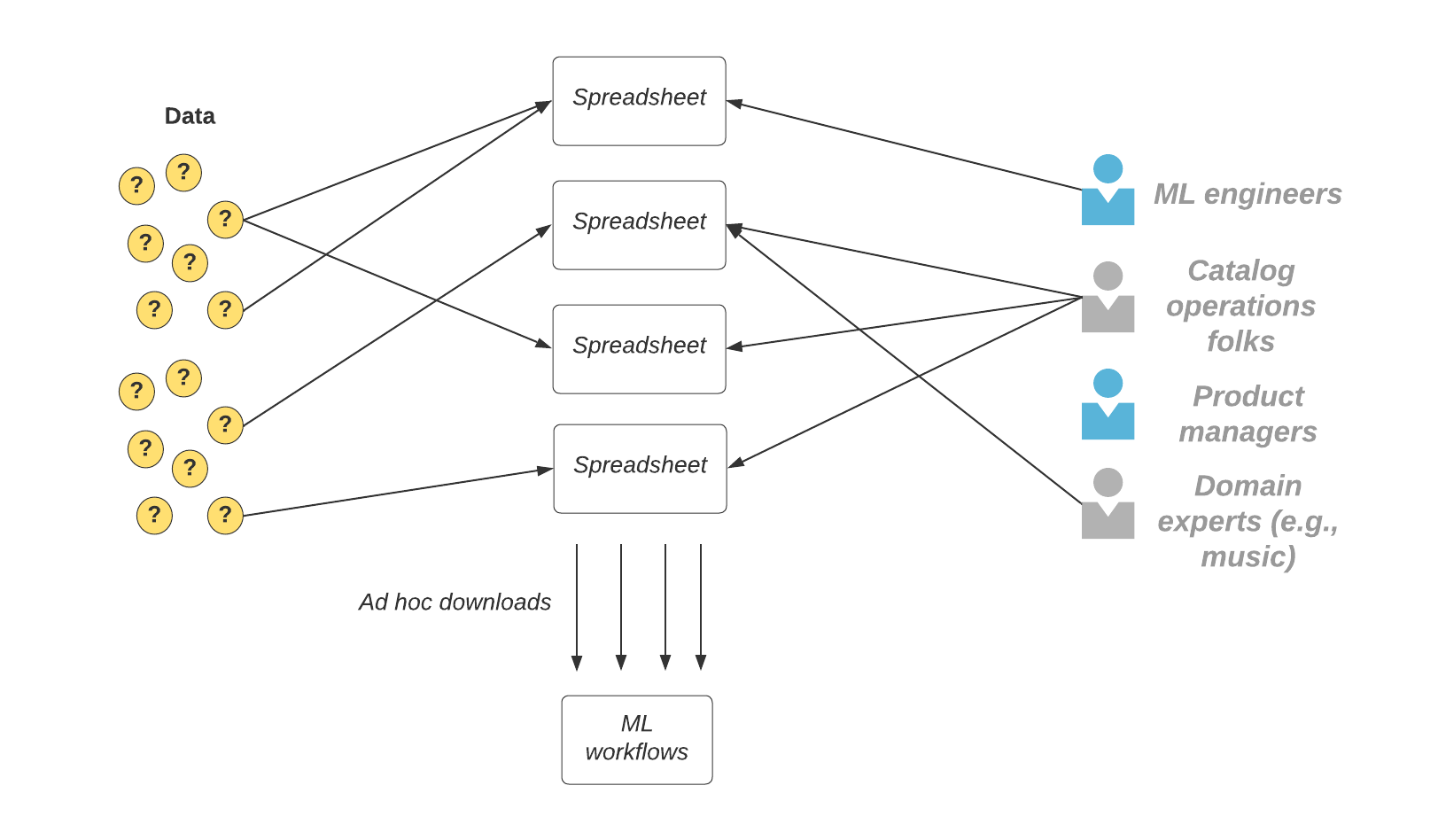
To deal with this, we needed to consider the end-to-end workflow. We took a simple ML classification undertaking, recognized the handbook steps to generate annotations, and aimed to automate them. We developed scripts to pattern predictions, served knowledge for operator assessment, and built-in the outcomes with mannequin coaching and analysis workflows. We elevated the corpus of annotations by 10 instances and did so with 3 times the advance in annotator productiveness.
Taking that as a promising signal, we additional experimented with this workflow for different ML duties. Once we confirmed the advantages of our strategy, we determined to speculate on this answer in earnest. Our subsequent goal was to outline the technique to construct a platform that might scale to tens of millions of annotations.
We centered our technique round three most important pillars:
- Scaling human experience.
- Implementing annotation tooling capabilities.
- Establishing foundational infrastructure and integration.
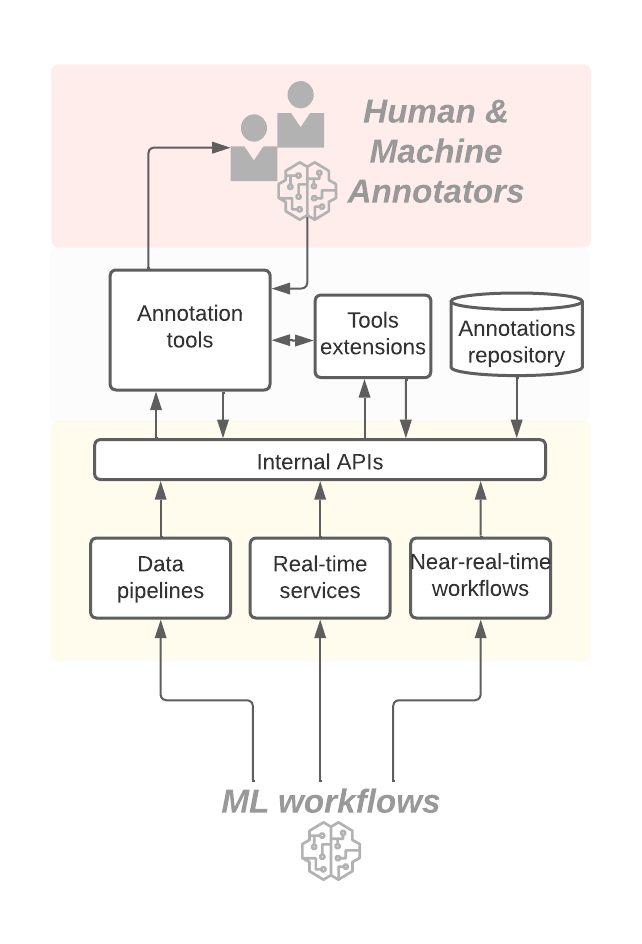
1. Scaling human experience.
In order to scale operations, it was crucial that we outlined processes to centralize and manage our annotation sources.
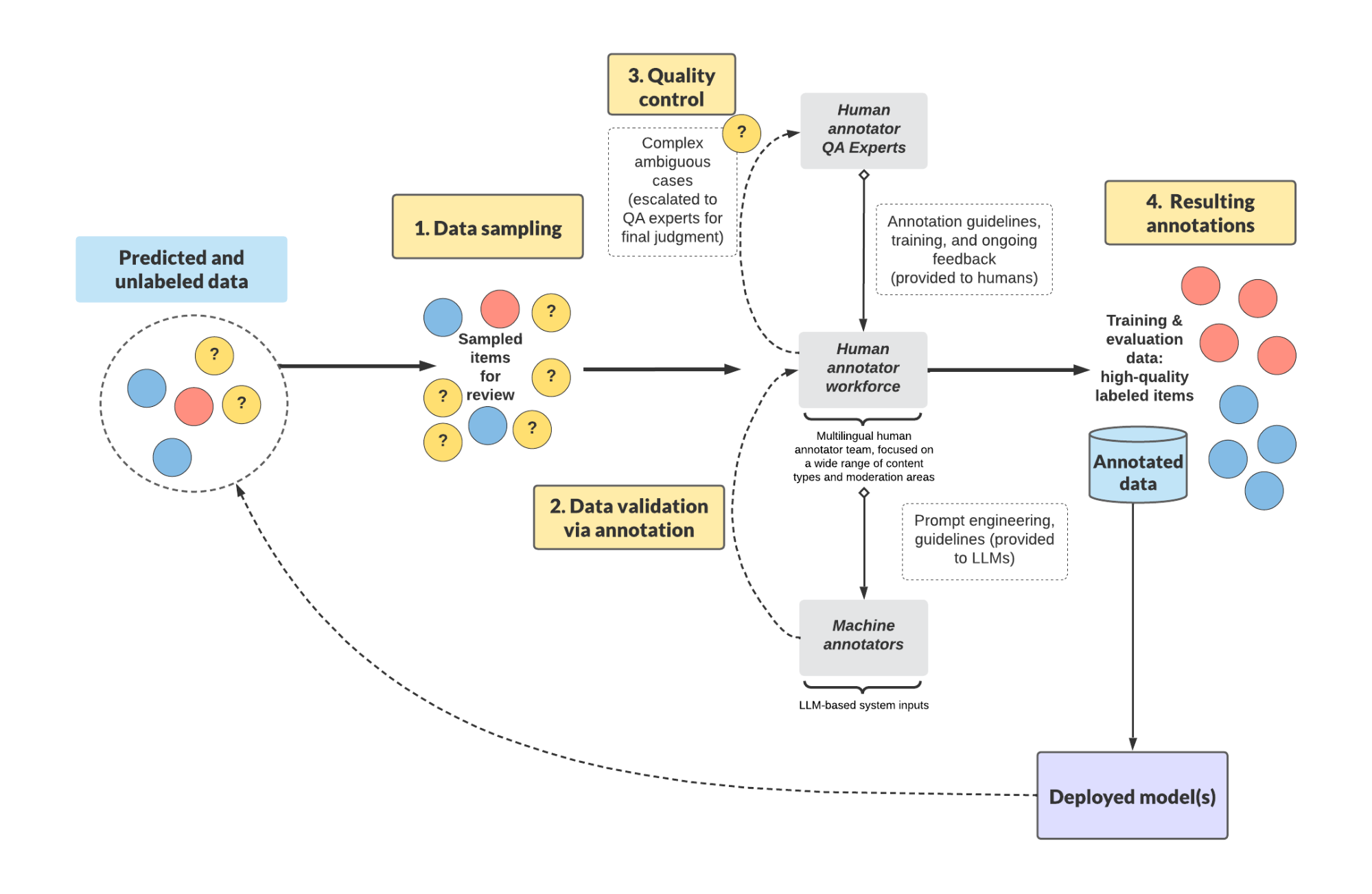
We established large-scale professional human workforces in a number of domains to handle our rising use instances, with a number of ranges of consultants, together with the next:
- Core annotator workforces: These workforces are area consultants, who present first-pass assessment of all annotation instances.
- Quality analysts: Quality analysts are top-level area consultants, who act because the escalation level for all ambiguous or complicated instances recognized by the core annotator workforce.
- Project managers: This contains people who join engineering and product groups to the workforce, set up and preserve coaching supplies, and manage suggestions on knowledge assortment methods.
Beyond human experience, we additionally constructed a configurable, LLM-based system that runs in parallel to the human consultants. It has allowed us to considerably develop our corpus of high-quality annotation knowledge with low effort and price.
2. Implementing annotation tooling capabilities.
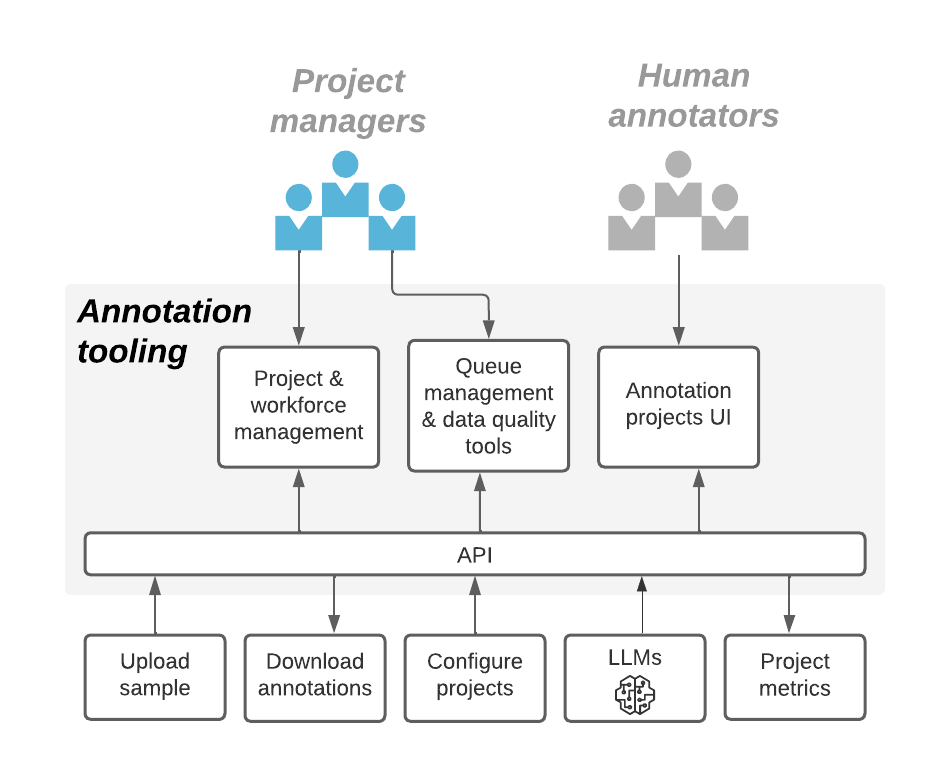
Although we began with a easy classification annotation undertaking (the annotation process being answering a query), we quickly realized that we had extra complicated use instances — corresponding to annotating audio/video segments, pure language processing, and so on. — which led to the event of customized interfaces, so we may simply spin up new initiatives.
In addition, we invested in instruments to handle backend work, corresponding to undertaking administration, entry management, and distribution of annotations throughout a number of consultants. This enabled us to deploy and run dozens of annotation initiatives in parallel, all whereas guaranteeing that consultants remained productive throughout a number of initiatives.
Another focus space was undertaking metrics — corresponding to undertaking completion price, knowledge volumes, annotations per annotator, and so on. These metrics helped undertaking managers and ML groups observe their initiatives. We additionally examined the annotation knowledge itself. For a few of our use instances, there have been nuances within the annotation process — for instance, detecting music that was overlaid in a podcast episode audio snippet. In these instances, completely different consultants could have completely different solutions and opinions, so we began to compute an general “agreement” metric. Any knowledge factors with no clear decision have been mechanically escalated to our high quality analysts. This ensures that our fashions obtain the best confidence annotation for coaching and analysis.
3. Establishing foundational infrastructure and integration.
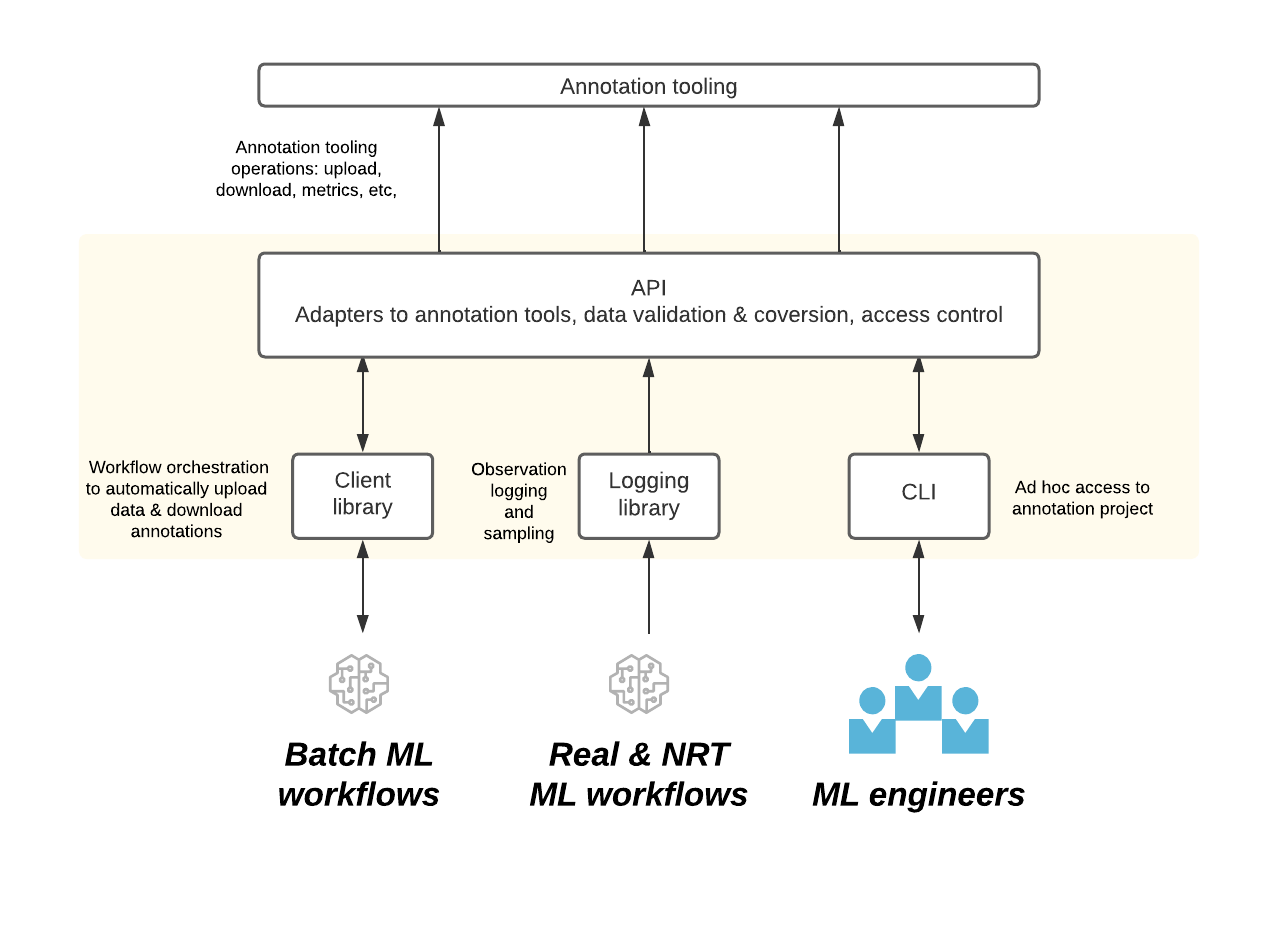
At Spotify’s scale, nobody device or software will fulfill all our wants — optionality is essential. When we designed integrations with annotation instruments, we have been intentional about constructing the appropriate abstractions. They should be versatile and adaptable to completely different instruments so we are able to leverage the appropriate device for the appropriate use case. Our knowledge fashions, APIs, and interfaces are generic and can be utilized with a number of kinds of annotation tooling.
We constructed bindings for direct integration with ML workflows at numerous phases from inception to manufacturing. For early/new ML improvement, we constructed CLIs and UIs for advert hoc initiatives. For manufacturing workflows, we constructed integrations with inside batch orchestration and workflow infrastructure.
The annotation platform now permits for flexibility, agility, and velocity inside our annotation areas. By democratizing high-quality annotations, we’ve been capable of considerably scale back the time it takes to develop new ML fashions and iterate on present techniques.
Putting an emphasis from the onset on each scaling our human area experience and machine capabilities was key. Scaling people with out scaling technical capabilities to help them would have introduced numerous challenges, and solely specializing in scaling technically would have resulted in misplaced alternatives.
It was a significant funding to maneuver from advert hoc initiatives to a full-scale platform answer to help ML and GenAI use instances. We proceed to iterate on and enhance the platform providing, incorporating the most recent developments within the business.
Acknowledgments
A particular due to Linden Vongsathorn and Marqia Williams for his or her help in launching this initiative and to the many individuals at Spotify at present who proceed to contribute to this necessary mission.
Tags: machine studying