{kind=link}
[ad_1]
March 5, 2024
TL;DR We summarize the findings in our latest paper, Schultzberg, Ankargren, and Frånberg (2024), the place we clarify how Spotify’s decision-making engine works and the way the outcomes of a number of metrics in an A/B check are mixed right into a single product choice. Metrics may be of various sorts, and we contemplate success metrics (superiority exams), guardrail metrics (non-inferiority exams), deterioration metrics (inferiority exams), and high quality metrics (numerous exams). We present that false constructive charges shouldn’t be adjusted for guardrail metrics. However, to acquire the meant energy, false detrimental charges should be corrected for the variety of guardrail metrics and the variety of different high quality exams used. We additionally current a call rule that features all 4 varieties of metrics and suggest a design and evaluation technique. Our strategy controls the dangers that incorrect selections could have on this choice rule underneath any data-generating course of. The choice rule additionally serves as an necessary device for standardizing decision-making throughout the corporate.
Product growth is a dangerous enterprise. If you don’t evolve your product shortly sufficient, rivals will outrun you. If you alter your product in methods customers don’t respect, you’ll lose them. Modern product growth is all about taking calculated dangers — some corporations have lots to realize and iterate shortly with better dangers, whereas others have extra to lose and need to iterate in a extra managed style with decrease dangers. Front and heart to any technique is danger — and the extent to which we are able to handle the dangers of doubtless unhealthy product selections.
Proposed modifications are examined by way of randomized experiments, minimizing the chance of incorrect selections and guiding well-informed product selections. Tools like experimental design and statistical evaluation are essential for danger administration. When we constructed the primary model of the choice engine in Spotify’s experimentation platform again in early 2020, we began from first rules. We studied how experimenters use the completely different sorts of metrics and exams that the experimentation platform supplies. We then formalized a call rule in response to that course of and derived the corresponding design and evaluation required to regulate the false constructive and false detrimental dangers of that call rule.
As our experimentation platform — Confidence — turns into publicly out there, we’re sharing the small print of our danger administration strategy in Schultzberg, Ankargren, and Frånberg (2024). In this publication, we emphasize the significance of aligning experimental design and evaluation with the choice rule to restrict incorrect product selections. We additionally present the choice rule Spotify makes use of and clarify how one can begin utilizing our decision-rules engine by way of Confidence.
By articulating the heuristics that govern your decision-making course of, you possibly can design and analyze the experiment in a means that respects the way you make selections ultimately. That’s not the one good thing about making use of choice guidelines, although. There are two different key perks of the decision-rule framework that stand out, significantly when contemplating an experimentation platform as a centralized device.
The first benefit is {that a} coherent and exhaustive means of routinely analyzing experiments is essential for standardizing product selections made out of A/B exams. A significant factor within the growth of our new experimentation platform again in 2019 was the time-consuming, guide effort required to run analyses — we lacked a standardized, widespread strategy to analyzing our experiments. Fast-forward to our new platform, the place our evaluation is totally automated. Combined with our choice guidelines, we not solely obtain automation of experiment analyses, but in addition standardization of what we consider a profitable experiment appears like.
A second benefit is that as a result of the choice rule exhaustively maps all potential outcomes to a call, we can provide constructive steering on the product implication of the outcomes — with out having to dive into any particular metric outcomes. This supplies us with an unimaginable alternative to democratize the outcomes of the experiments. Anyone, no matter curiosity or expertise with statistical outcomes, can get a studying on the experiment. Experimentation is, and must be, a crew sport. This reduces the necessity for knowledge science experience to accurately interpret experiment outcomes.
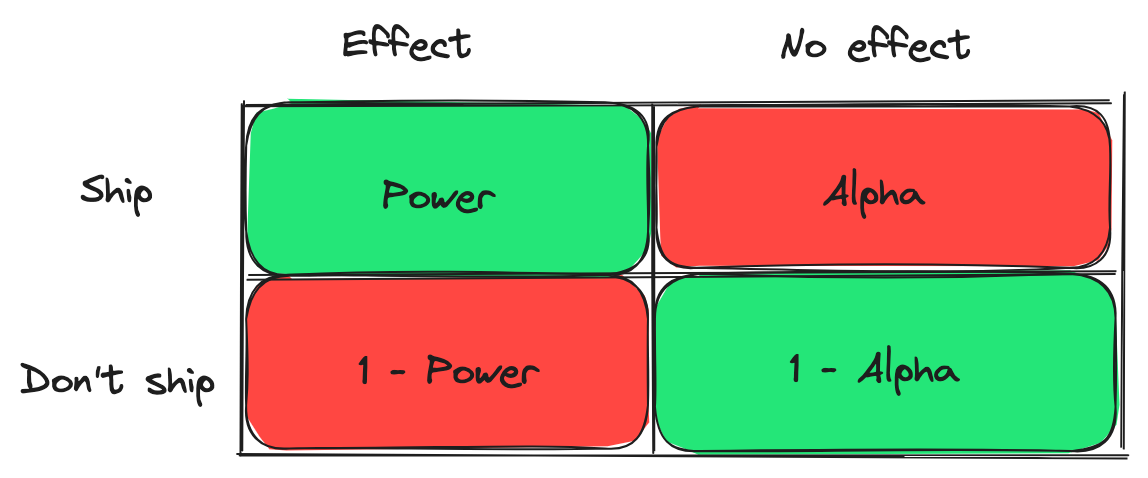
Before venturing into extra element on how we incorporate the choice rule into the design and evaluation of our experiments, we’ll first current a quick refresher on our danger administration technique for product selections. You could not consider null speculation significance testing as a danger administration device, however that’s exactly what it’s. We plan an experiment to regulate the chance of a false-positive or false-negative outcome. We usually use alpha (α) to indicate the meant danger for a false-positive outcome, and beta (β) for the chance of a false-negative outcome, the place 1 – β is the meant energy.
Our objective is as follows:
- To restrict the speed at which we ship modifications that appear to enhance the consumer expertise when, in actual fact, they don’t
- To restrict the speed at which we don’t ship modifications as a result of they don’t appear to have the meant impact when, in actual fact, they do
Over a program of many experiments, we are able to be sure that the charges at which we make the proper and incorrect selections are bounded. The secret is to energy the experiments and to stay to the preplanned evaluation. The following picture illustrates this.
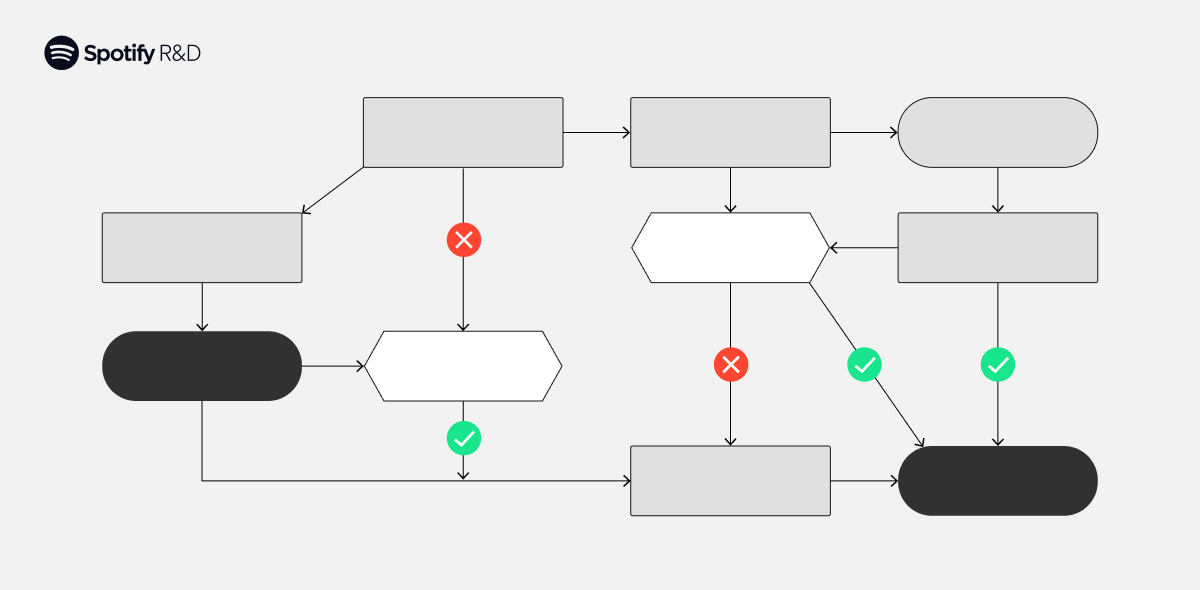
Going from the person outcomes of a number of metrics to a product choice is tough. For instance, it’s widespread that an experiment positively impacts some metrics whereas others stay unchanged. Or positively impacts sure metrics whereas others deteriorate. In conditions like these, the decision-making course of usually turns into advert hoc and varies broadly throughout experiments, forgoing the scientific mindset that went into establishing the experiment within the first place. Unless you explicitly outline how you propose to map the outcomes of all metrics in an experiment to your delivery choice, you’ll hardly ever reach controlling the chance of what really issues — the charges at which you make the proper selections about your product. Luckily, by way of a structured and well-crafted experimental strategy, we are able to be taught what’s impactful whereas sustaining sturdy statistical danger ensures.
To successfully handle the chance, the choice rule should be specific, and the experiment should be designed and analyzed with the rule in thoughts. For instance, in experiments with a number of metrics, a standard approach to preserve false-positive danger at an experiment stage is a number of testing correction, which is second nature for a lot of experimenters. However, it’s hardly ever acknowledged that these corrections are intimately tied to an implicit choice rule the place you’ll ship if any metric strikes. Clearly, this rule is inadequate when, for instance, metrics transfer in conflicting instructions.
Aspects that ought to go into a call rule
At Spotify, we embrace 4 varieties of metrics and exams in our default product-shipping choice suggestions:
- Success metrics. Metrics that we goal to enhance, examined with superiority exams.
- Guardrail metrics. Metrics that we don’t count on to enhance, however we wish proof that they’re not deteriorating by greater than a sure margin. Tested with non-inferiority exams.
- Deterioration metrics. Metrics that shouldn’t deteriorate, examined with inferiority exams. Can additionally embrace success and guardrail metrics.
- Quality metrics and exams. Metrics and exams that validate the standard of the experiment itself, like exams for pattern ratio mismatch and pre-exposure bias.
Success and guardrail metrics goal to gather proof that the change results in a fascinating consequence and with out unanticipated unwanted side effects. The deterioration and high quality metrics assist validate the integrity of the experiment by figuring out damaged experiences, bugs, and misconfigured implementations.
Based on the outcomes of the exams for these metrics, we advocate a call. The choice rule used at Spotify and in Confidence is as follows.
Ship if and provided that:
- The therapy is considerably superior to regulate on a minimum of one success metric.
- The therapy is considerably non-inferior to regulate on all guardrail metrics.
- No success, guardrail, or deterioration metrics present proof of degradation.
- No high quality check considerably invalidates the standard of the experiment.
In different phrases, the experiment should present no indications of a scarcity of high quality or dangerous unwanted side effects. Moreover, the product change should make sense from a enterprise perspective. The check should show that each one guardrail metrics are non-inferior and that there’s a minimum of one metric that improves. We consider this choice rule is a pure bar for a profitable experiment. The important takeaway, nevertheless, is that no matter your most well-liked choice rule is, you have to contemplate it within the design and the evaluation of your experiments. If you don’t, all bets are off for the chance administration of your product growth. Of course, there’ll at all times be conditions the place this choice rule isn’t acceptable — for instance, when the choice relies partly on exterior components that may’t be modeled within the experiment. However, we discover that for the majority of experiments, this can be a pragmatic means of modeling decision-making and controlling its danger.
Next, we’ll briefly talk about the principle statistical points of bounding the error charges of the choice rule. For an in depth description, see Schultzberg, Ankargren, and Frånberg (2024). We begin by constructing instinct for among the key components of the design and evaluation for the entire choice rule.
You shouldn’t appropriate the false-positive charge for guardrails…
Most folks working with A/B testing know the significance of a number of testing correction to keep away from inflating the false-positive charge. However, the rationale for these corrections modifications as quickly as we contain guardrail metrics, the place we need to guard towards deterioration by proving non-inferiority. In this case, we wish the therapy to be considerably non-inferior to regulate for all guardrail metrics. There are not a number of possibilities in a means that motivates the usage of a number of testing corrections.
For an experiment with solely success and guardrail metrics, the related a part of the choice rule is to ship if the next are true:
- The therapy is considerably superior to regulate on a minimum of one success metric.
- The therapy is considerably non-inferior to regulate on all guardrail metrics.
Under this rule, you solely want to regulate the false-positive charge for the variety of success metrics, as a result of that’s the one group of metrics wherein you may have a number of possibilities. This implies that we use
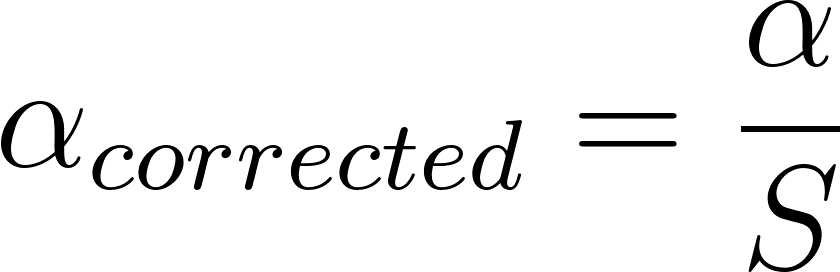
for fulfillment metrics and for guardrail metrics.
In Schultzberg, Ankargren, and Frånberg (2024), we additionally talk about the impact of degradation and high quality exams intimately. In quick, they solely have an effect on the bounds of the false-negative charge, which leads us to the subsequent part.
But it’s best to alter the ability stage to your guardrails
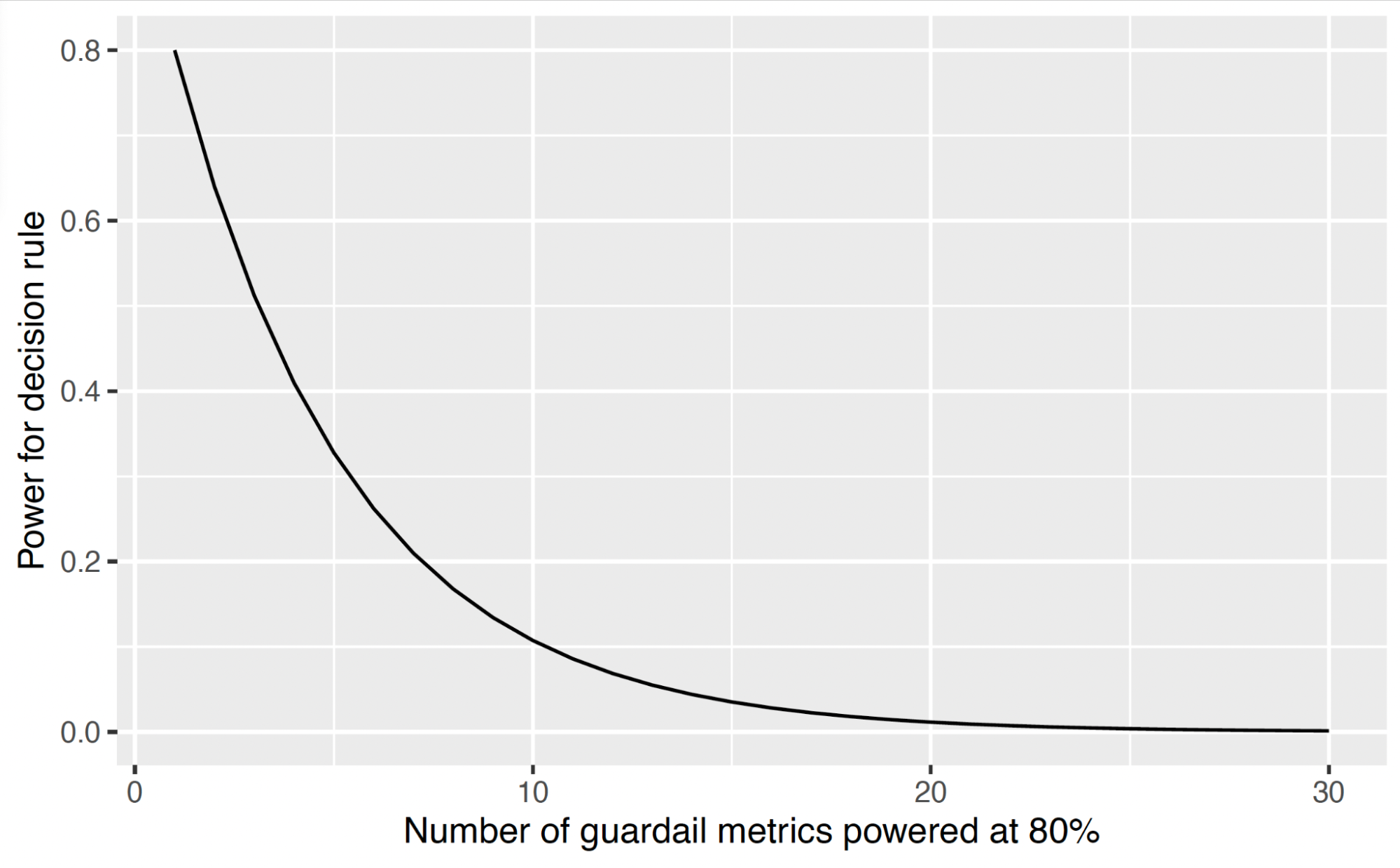
Power corrections (or beta corrections) are surprisingly absent from the net experimentation literature, particularly contemplating the widespread consciousness of the fallacies of underpowered experiments. Given the necessity for the therapy to be non-inferior on all of the guardrail metrics and superior on a minimum of one success metric, these occasions have to have a simultaneous likelihood of a minimum of . As an instance, suppose that the guardrail metrics are impartial, and every metric is powered to fulfill
. In this situation, the likelihood that each one guardrail metrics are concurrently vital shortly approaches zero because the variety of guardrail metrics (
) will increase. Figure 2 shows this relation underneath independence between the guardrail metrics. Already, with 5 guardrail metrics, the simultaneous energy is means under 40%, and for 10 guardrail metrics, it’s round 11%.
In Schultzberg, Ankargren, and Frånberg (2024), we present that we are able to mitigate the lack of energy by correcting the extent we energy every metric for. If we energy every metric for
,
the place is the variety of guardrail metrics, the ability of the choice is a minimum of
.
Deterioration and high quality metrics provide you with fewer probabilities of discovering success
At Spotify, we embrace sure vital enterprise metrics as deterioration metrics in all experiments, which we check for inferiority. These inferiority exams are utilized to all metrics in an experiment to detect vital deterioration, indicating the therapy’s inferiority to the management. Deterioration exams are essential for figuring out regressions that would influence an experiment’s success. Inferiority exams for these metrics assist pinpoint vital regressions, complementing the prevailing superiority and non-inferiority exams within the choice rule.
Quality metrics, like exams for pattern ratio mismatch and pre-exposure bias, are integral to any superior experimentation device to validate the standard of the experiment. Incorporating deterioration and high quality metrics makes the choice rule extra conservative, including alternatives to cease the experiment. In the subsequent part, we present the way to alter the design to supply the meant energy for the choice rule.
First, let’s repeat our choice rule.
Ship if and provided that:
- The therapy is considerably superior to regulate on a minimum of one success metric.
- The therapy is considerably non-inferior to regulate on all guardrail metrics.
- No success, guardrail, or deterioration metrics present proof of degradation.
- No high quality check considerably invalidates the standard of the experiment.
Using what we’ve realized, we make use of the next danger technique and correction to acquire at most the meant false-positive charge, and a minimum of the meant energy. Let S and be the variety of success and guardrail metrics, respectively. All success and guardrail metrics are additionally examined for deterioration. Let D be the extra variety of metrics examined for deterioration, and let Q be the variety of exams for high quality.
Let and
be the meant false-positive and false-negative charges for the general product choice, and
be the meant false-positive charge for the deterioration and high quality exams. To be sure that the false-positive and false-negative dangers for the choice don’t exceed the meant ranges, use the next:
- For all deterioration and high quality exams, use
.
- For the prevalence exams for fulfillment metrics, use
.
- For the non-inferiority exams for guardrail metrics, use
.
- For all non-inferiority exams and superiority exams, use
.
Using the above corrections, the false-positive and false-negative charges received’t exceed the meant ranges for the choice underneath any covariance construction. See Schultzberg, Ankargren, and Frånberg (2024) for a proper proof.
For widespread empirical values of , similar to 1%, the impact of the deterioration and high quality exams on the beta correction is negligible. To simplify, we are able to omit their contribution to the correction and nonetheless obtain empirical false-positive and false-negative charges that don’t exceed our meant ranges underneath the correlation buildings we frequently see in observe.
In abstract:
- To restrict the dangers of incorrect product selections primarily based on experiment outcomes, it’s essential to have an specific choice rule that maps the outcomes from all statistical exams utilized in an A/B check to a product choice.
- Different choice guidelines require completely different experimental designs and statistical analyses to restrict the dangers of creating the unsuitable selections.
- Multiple testing corrections for false-positive charges are broadly accepted and used. We present that false-positive charges shouldn’t be corrected for guardrail metrics. Moreover, we introduce beta corrections, that are important for powering the product choice rule when your experiment contains guardrail metrics.
- Not having a one-to-one mapping between your choice rule on the one hand, and the experimental design and statistical evaluation on the opposite, usually implies that the dangers of creating the unsuitable selections aren’t what you suppose they’re.
Unless you match your design and evaluation with the way you’re making selections primarily based in your experiment outcomes, you aren’t controlling the dangers of creating the unsuitable choice as you propose. With Confidence, you possibly can shortly get began with analyses of experiments utilizing choice guidelines that can assist you automate, standardize, and democratize experiment leads to your group. Our buy-and-build precept makes it potential so that you can customise the way you analyze your experiments.
Get entry to Spotify’s choice engine by way of Confidence
By default, Confidence analyzes experiments utilizing the choice guidelines beforehand offered. Your analyses are at all times adjusted for a number of testing, however in response to the delivery choice as described within the part above. Confidence supplies every therapy with a delivery advice that summarizes the state of the experiment. It offers you a advice for what to do and reveals you the way every bit of the choice rule contributes to the present advice.Want to be taught extra about Confidence? Check out the Confidence weblog for extra posts on Confidence and its performance. Confidence is at the moment out there in personal beta. If you haven’t signed up already, enroll immediately, and we’ll be in contact.
Tags: experimentation
[ad_2]