{kind=link}
[ad_1]
by Binbing Hou, Stephanie Vezich Tamayo, Xiao Chen, Liang Tian, Troy Ristow, Haoyuan Wang, Snehal Chennuru, Pawan Dixit
This is the primary of the sequence of our work at Netflix on leveraging information insights and Machine Learning (ML) to enhance the operational automation across the efficiency and value effectivity of huge information jobs. Operational automation–together with however not restricted to, auto analysis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is vital to the success of contemporary information platforms. In this weblog publish, we current our mission on Auto Remediation, which integrates the at the moment used rule-based classifier with an ML service and goals to robotically remediate failed jobs with out human intervention. We have deployed Auto Remediation in manufacturing for dealing with reminiscence configuration errors and unclassified errors of Spark jobs and noticed its effectivity and effectiveness (e.g., robotically remediating 56% of reminiscence configuration errors and saving 50% of the financial prices attributable to all errors) and nice potential for additional enhancements.
At Netflix, tons of of hundreds of workflows and thousands and thousands of jobs are working per day throughout a number of layers of the large information platform. Given the in depth scope and complicated complexity inherent to such a distributed, large-scale system, even when the failed jobs account for a tiny portion of the overall workload, diagnosing and remediating job failures could cause appreciable operational burdens.
For environment friendly error dealing with, Netflix developed an error classification service, known as Pensive, which leverages a rule-based classifier for error classification. The rule-based classifier classifies job errors based mostly on a set of predefined guidelines and gives insights for schedulers to determine whether or not to retry the job and for engineers to diagnose and remediate the job failure.
However, because the system has elevated in scale and complexity, the rule-based classifier has been dealing with challenges because of its restricted help for operational automation, particularly for dealing with reminiscence configuration errors and unclassified errors. Therefore, the operational value will increase linearly with the variety of failed jobs. In some circumstances–for instance, diagnosing and remediating job failures attributable to Out-Of-Memory (OOM) errors–joint effort throughout groups is required, involving not solely the customers themselves, but in addition the help engineers and area consultants.
To handle these challenges, now we have developed a brand new function, known as Auto Remediation, which integrates the rule-based classifier with an ML service. Based on the classification from the rule-based classifier, it makes use of an ML service to foretell retry success likelihood and retry value and selects one of the best candidate configuration as suggestions; and a configuration service to robotically apply the suggestions. Its main benefits are under:
- Integrated intelligence. Instead of utterly deprecating the present rule-based classifier, Auto Remediation integrates the classifier with an ML service in order that it may leverage the deserves of each: the rule-based classifier gives static, deterministic classification outcomes per error class, which relies on the context of area consultants; the ML service gives performance- and cost-aware suggestions per job, which leverages the facility of ML. With the built-in intelligence, we will correctly meet the necessities of remediating totally different errors.
- Fully automated. The pipeline of classifying errors, getting suggestions, and making use of suggestions is totally automated. It gives the suggestions along with the retry resolution to the scheduler, and significantly makes use of a web-based configuration service to retailer and apply really helpful configurations. In this fashion, no human intervention is required within the remediation course of.
- Multi-objective optimizations. Auto Remediation generates suggestions by contemplating each efficiency (i.e., the retry success likelihood) and compute value effectivity (i.e., the financial prices of working the job) to keep away from blindly recommending configurations with extreme useful resource consumption. For instance, for reminiscence configuration errors, it searches a number of parameters associated to the reminiscence utilization of job execution and recommends the mixture that minimizes a linear mixture of failure likelihood and compute value.
These benefits have been verified by the manufacturing deployment for remediating Spark jobs’ failures. Our observations point out that Auto Remediation can efficiently remediate about 56% of all reminiscence configuration errors by making use of the really helpful reminiscence configurations on-line with out human intervention; and in the meantime scale back the price of about 50% because of its potential to advocate new configurations to make reminiscence configurations profitable and disable pointless retries for unclassified errors. We have additionally famous an incredible potential for additional enchancment by mannequin tuning (see the part of Rollout in Production).
Basics

Figure 1 illustrates the error classification service, i.e., Pensive, within the information platform. It leverages the rule-based classifier and consists of three parts:
- Log Collector is answerable for pulling logs from totally different platform layers for error classification (e.g., the scheduler, job orchestrator, and compute clusters).
- Rule Execution Engine is answerable for matching the collected logs towards a set of predefined guidelines. A rule consists of (1) the title, supply, log, and abstract, of the error and whether or not the error is restartable; and (2) the regex to establish the error from the log. For instance, the rule with the title SparkDriverOOM consists of the knowledge indicating that if the stdout log of a Spark job can match the regex SparkOutOfMemoryError:, then this error is classed to be a consumer error, not restartable.
- Result Finalizer is answerable for finalizing the error classification outcome based mostly on the matched guidelines. If one or a number of guidelines are matched, then the classification of the primary matched rule determines the ultimate classification outcome (the rule precedence is decided by the rule ordering, and the primary rule has the very best precedence). On the opposite hand, if no guidelines are matched, then this error can be thought-about unclassified.
Challenges
While the rule-based classifier is straightforward and has been efficient, it’s dealing with challenges because of its restricted potential to deal with the errors attributable to misconfigurations and classify new errors:
- Memory configuration errors. The rules-based classifier gives error classification outcomes indicating whether or not to restart the job; nevertheless, for non-transient errors, it nonetheless depends on engineers to manually remediate the job. The most notable instance is reminiscence configuration errors. Such errors are typically attributable to the misconfiguration of job reminiscence. Setting an excessively small reminiscence can lead to Out-Of-Memory (OOM) errors whereas setting an excessively massive reminiscence can waste cluster reminiscence sources. What’s more difficult is that some reminiscence configuration errors require altering the configurations of a number of parameters. Thus, setting a correct reminiscence configuration requires not solely the handbook operation but in addition the experience of Spark job execution. In addition, even when a job’s reminiscence configuration is initially nicely tuned, modifications comparable to information measurement and job definition could cause efficiency to degrade. Given that about 600 reminiscence configuration errors per 30 days are noticed within the information platform, well timed remediation of reminiscence configuration errors alone requires non-trivial engineering efforts.
- Unclassified errors. The rule-based classifier depends on information platform engineers to manually add guidelines for recognizing errors based mostly on the identified context; in any other case, the errors can be unclassified. Due to the migrations of various layers of the info platform and the range of functions, current guidelines could be invalid, and including new guidelines requires engineering efforts and likewise depends upon the deployment cycle. More than 300 guidelines have been added to the classifier, but about 50% of all failures stay unclassified. For unclassified errors, the job could also be retried a number of occasions with the default retry coverage. If the error is non-transient, these failed retries incur pointless job working prices.
Methodology
To handle the above-mentioned challenges, our fundamental methodology is to combine the rule-based classifier with an ML service to generate suggestions, and use a configuration service to use the suggestions robotically:
- Generating suggestions. We use the rule-based classifier as the primary go to categorise all errors based mostly on predefined guidelines, and the ML service because the second go to supply suggestions for reminiscence configuration errors and unclassified errors.
- Applying suggestions. We use a web-based configuration service to retailer and apply the really helpful configurations. The pipeline is totally automated, and the providers used to generate and apply suggestions are decoupled.
Service Integrations
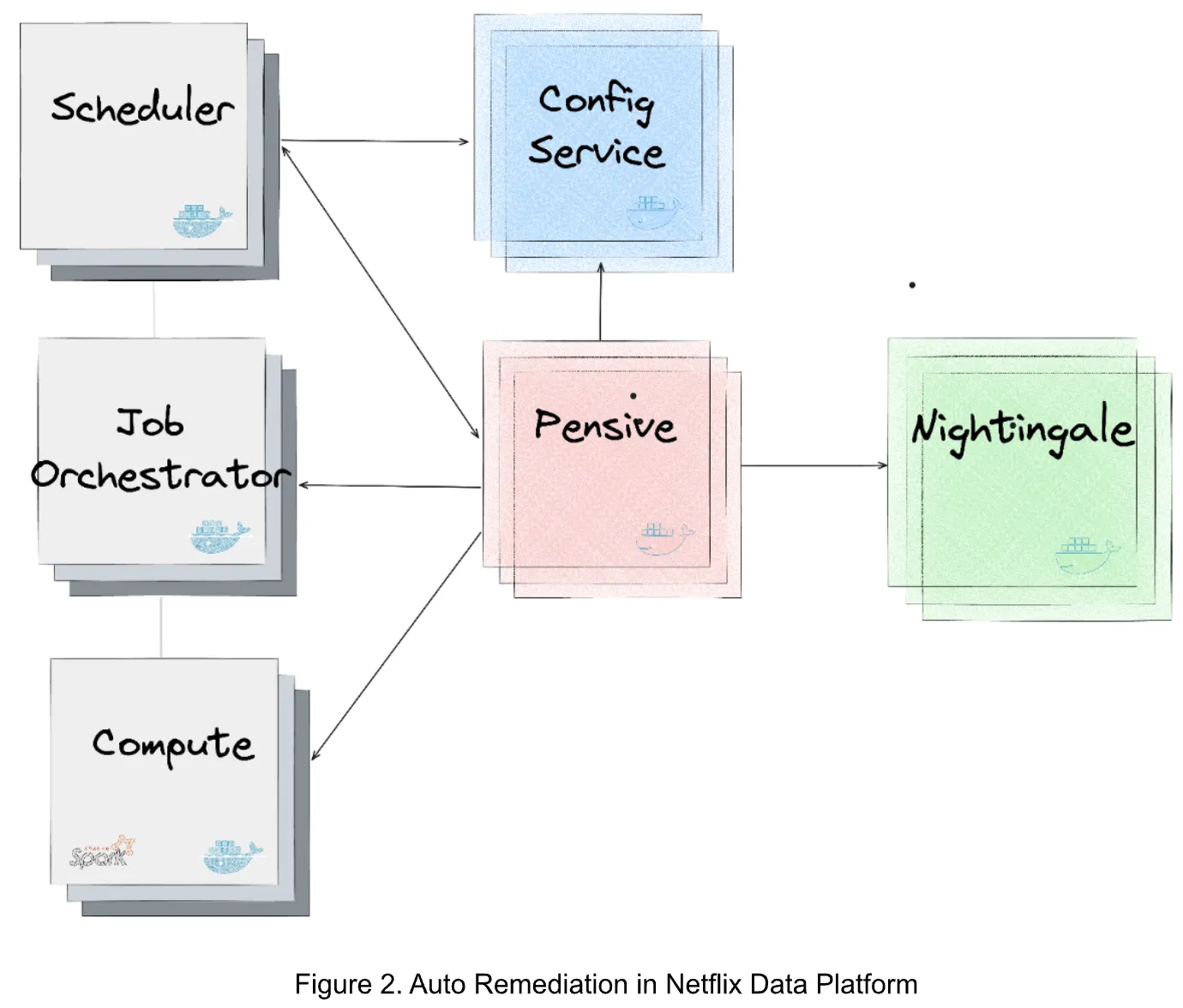
Figure 2 illustrates the combination of the providers producing and making use of the suggestions within the information platform. The main providers are as follows:
- Nightingale is a service working the ML mannequin educated utilizing Metaflow and is answerable for producing a retry suggestion. The suggestion consists of (1) whether or not the error is restartable; and (2) if that’s the case, the really helpful configurations to restart the job.
- ConfigService is a web-based configuration service. The really helpful configurations are saved in ConfigService as a JSON patch with a scope outlined to specify the roles that may use the really helpful configurations. When Scheduler calls ConfigService to get really helpful configurations, Scheduler passes the unique configurations to ConfigService and ConfigService returns the mutated configurations by making use of the JSON patch to the unique configurations. Scheduler can then restart the job with the mutated configurations (together with the really helpful configurations).
- Pensive is an error classification service that leverages the rule-based classifier. It calls Nightingale to get suggestions and shops the suggestions to ConfigService in order that it may be picked up by Scheduler to restart the job.
- Scheduler is the service scheduling jobs (our present implementation is with Netflix Maestro). Each time when a job fails, it calls Pensive to get the error classification to determine whether or not to restart a job and calls ConfigServices to get the really helpful configurations for restarting the job.

Figure 3 illustrates the sequence of service calls with Auto Remediation:
- Upon a job failure, Scheduler calls Pensive to get the error classification.
- Pensive classifies the error based mostly on the rule-based classifier. If the error is recognized to be a reminiscence configuration error or an unclassified error, it calls Nightingale to get suggestions.
- With the obtained suggestions, Pensive updates the error classification outcome and saves the really helpful configurations to ConfigService; after which returns the error classification outcome to Scheduler.
- Based on the error classification outcome obtained from Pensive, Scheduler determines whether or not to restart the job.
- Before restarting the job, Scheduler calls ConfigService to get the really helpful configuration and retries the job with the brand new configuration.
Overview
The ML service, i.e., Nightingale, goals to generate a retry coverage for a failed job that trades off between retry success likelihood and job working prices. It consists of two main parts:
- A prediction mannequin that collectively estimates a) likelihood of retry success, and b) retry value in {dollars}, conditional on properties of the retry.
- An optimizer which explores the Spark configuration parameter area to advocate a configuration which minimizes a linear mixture of retry failure likelihood and value.
The prediction mannequin is retrained offline day by day, and known as by the optimizer to guage every candidate set of configuration parameter values. The optimizer runs in a RESTful service which known as upon job failure. If there’s a possible configuration resolution from the optimization, the response consists of this suggestion, which ConfigService makes use of to mutate the configuration for the retry. If there is no such thing as a possible resolution–in different phrases, it’s unlikely the retry will succeed by altering Spark configuration parameters alone–the response features a flag to disable retries and thus eradicate wasted compute value.
Prediction Model
Given that we wish to discover how retry success and retry value may change below totally different configuration situations, we want some option to predict these two values utilizing the knowledge now we have concerning the job. Data Platform logs each retry success final result and execution value, giving us dependable labels to work with. Since we use a shared function set to foretell each targets, have good labels, and must run inference shortly on-line to fulfill SLOs, we determined to formulate the issue as a multi-output supervised studying process. In explicit, we use a easy Feedforward Multilayer Perceptron (MLP) with two heads, one to foretell every final result.
Training: Each file within the coaching set represents a possible retry which beforehand failed because of reminiscence configuration errors or unclassified errors. The labels are: a) did retry fail, b) retry value. The uncooked function inputs are largely unstructured metadata concerning the job such because the Spark execution plan, the consumer who ran it, and the Spark configuration parameters and different job properties. We cut up these options into these that may be parsed into numeric values (e.g., Spark executor reminiscence parameter) and people who can’t (e.g., consumer title). We used function hashing to course of the non-numeric values as a result of they arrive from a excessive cardinality and dynamic set of values. We then create a decrease dimensionality embedding which is concatenated with the normalized numeric values and handed by way of a number of extra layers.
Inference: Upon passing validation audits, every new mannequin model is saved in Metaflow Hosting, a service supplied by our inside ML Platform. The optimizer makes a number of calls to the mannequin prediction operate for every incoming configuration suggestion request, described in additional element under.
Optimizer
When a job try fails, it sends a request to Nightingale with a job identifier. From this identifier, the service constructs the function vector for use in inference calls. As described beforehand, a few of these options are Spark configuration parameters that are candidates to be mutated (e.g., spark.executor.reminiscence, spark.executor.cores). The set of Spark configuration parameters was based mostly on distilled data of area consultants who work on Spark efficiency tuning extensively. We use Bayesian Optimization (carried out by way of Meta’s Ax library) to discover the configuration area and generate a suggestion. At every iteration, the optimizer generates a candidate parameter worth mixture (e.g., spark.executor.reminiscence=7192 mb, spark.executor.cores=8), then evaluates that candidate by calling the prediction mannequin to estimate retry failure likelihood and value utilizing the candidate configuration (i.e., mutating their values within the function vector). After a set variety of iterations is exhausted, the optimizer returns the “best” configuration resolution (i.e., that which minimized the mixed retry failure and value goal) for ConfigService to make use of whether it is possible. If no possible resolution is discovered, we disable retries.
One draw back of the iterative design of the optimizer is that any bottleneck can block completion and trigger a timeout, which we initially noticed in a non-trivial variety of circumstances. Upon additional profiling, we discovered that a lot of the latency got here from the candidate generated step (i.e., determining which instructions to step within the configuration area after the earlier iteration’s analysis outcomes). We discovered that this concern had been raised to Ax library house owners, who added GPU acceleration choices of their API. Leveraging this selection decreased our timeout charge considerably.
We have deployed Auto Remediation in manufacturing to deal with reminiscence configuration errors and unclassified errors for Spark jobs. Besides the retry success likelihood and value effectivity, the influence on consumer expertise is the main concern:
- For reminiscence configuration errors: Auto remediation improves consumer expertise as a result of the job retry isn’t profitable with no new configuration for reminiscence configuration errors. This implies that a profitable retry with the really helpful configurations can scale back the operational hundreds and save job working prices, whereas a failed retry doesn’t make the consumer expertise worse.
- For unclassified errors: Auto remediation recommends whether or not to restart the job if the error can’t be categorised by current guidelines within the rule-based classifier. In explicit, if the ML mannequin predicts that the retry could be very more likely to fail, it should advocate disabling the retry, which might save the job working prices for pointless retries. For circumstances during which the job is business-critical and the consumer prefers all the time retrying the job even when the retry success likelihood is low, we will add a brand new rule to the rule-based classifier in order that the identical error can be categorised by the rule-based classifier subsequent time, skipping the suggestions of the ML service. This presents some great benefits of the built-in intelligence of the rule-based classifier and the ML service.
The deployment in manufacturing has demonstrated that Auto Remediation can present efficient configurations for reminiscence configuration errors, efficiently remediating about 56% of all reminiscence configuration with out human intervention. It additionally decreases compute value of those jobs by about 50% as a result of it may both advocate new configurations to make the retry profitable or disable pointless retries. As tradeoffs between efficiency and value effectivity are tunable, we will determine to attain the next success charge or extra value financial savings by tuning the ML service.
It is value noting that the ML service is at the moment adopting a conservative coverage to disable retries. As mentioned above, that is to keep away from the influence on the circumstances that customers favor all the time retrying the job upon job failures. Although these circumstances are anticipated and could be addressed by including new guidelines to the rule-based classifier, we think about tuning the target operate in an incremental method to regularly disable extra retries is useful to supply fascinating consumer expertise. Given the present coverage to disable retries is conservative, Auto Remediation presents an incredible potential to finally deliver far more value financial savings with out affecting the consumer expertise.
Auto Remediation is our first step in leveraging information insights and Machine Learning (ML) for enhancing consumer expertise, lowering the operational burden, and enhancing value effectivity of the info platform. It focuses on automating the remediation of failed jobs, but in addition paves the trail to automate operations aside from error dealing with.
One of the initiatives we’re taking, known as Right Sizing, is to reconfigure scheduled large information jobs to request the right sources for job execution. For instance, now we have famous that the typical requested executor reminiscence of Spark jobs is about 4 occasions their max used reminiscence, indicating a big overprovision. In addition to the configurations of the job itself, the useful resource overprovision of the container that’s requested to execute the job will also be lowered for value financial savings. With heuristic- and ML-based strategies, we will infer the right configurations of job execution to reduce useful resource overprovisions and save thousands and thousands of {dollars} per yr with out affecting the efficiency. Similar to Auto Remediation, these configurations could be robotically utilized by way of ConfigService with out human intervention. Right Sizing is in progress and can be coated with extra particulars in a devoted technical weblog publish later. Stay tuned.
Auto Remediation is a joint work of the engineers from totally different groups and organizations. This work would haven’t been potential with out the strong, in-depth collaborations. We wish to respect all people, together with Spark consultants, information scientists, ML engineers, the scheduler and job orchestrator engineers, information engineers, and help engineers, for sharing the context and offering constructive solutions and useful suggestions (e.g., John Zhuge, Jun He, Holden Karau, Samarth Jain, Julian Jaffe, Batul Shajapurwala, Michael Sachs, Faisal Siddiqi).
[ad_2]