{kind=link}
[ad_1]
July 19, 2023 Published by Federico Tomasi, Joseph Cauteruccio, Surya Kanoria, Kamil Ciosek, Matteo Rinaldi, and Zhenwen Dai

Reinforcement studying (RL) is a longtime instrument for sequential resolution making. In this work, we apply RL to unravel an automated music playlist technology downside. In specific, we developed a RL framework for set sequencing that optimizes for person satisfaction metrics through using a simulated playlist-generation setting. Using this simulator we develop and practice a modified deep Q-Network, which we name the Action-Head DQN (AH-DQN), in a way that addresses the challenges imposed by the big state and motion area of our RL formulation. We analyze and consider brokers offline through simulations that use setting fashions skilled on each public and proprietary streaming datasets. We present how these brokers result in higher user-satisfaction metrics in comparison with baseline strategies throughout on-line A/B assessments. Finally, we show that efficiency assessments produced from our simulator are strongly correlated with noticed on-line metric outcomes.
RL for Automatic Music Playlist Generation
We body the issue as an automated music playlist technology: given a (giant) set of tracks, we wish to discover ways to create one optimum playlist to suggest to the person so as to maximize satisfaction metrics. Crucially, our use case is totally different from customary slate advice duties, the place normally the goal is to pick out at most one merchandise within the sequence. Here, as a substitute, we assume now we have a user-generated response for a number of objects within the slate, making slate advice programs circuitously relevant.
As an instance, contemplate the case when customers determine on a sort of content material they’re taken with (eg, “indie pop”). Having a catalog of thousands and thousands of tracks, it’s not simple which tracks are greatest suited to the person that requested the playlist, as every person experiences music otherwise. For this cause, automated playlist technology is a related and sensible downside for music streaming platforms to create the very best personalised expertise for every person.
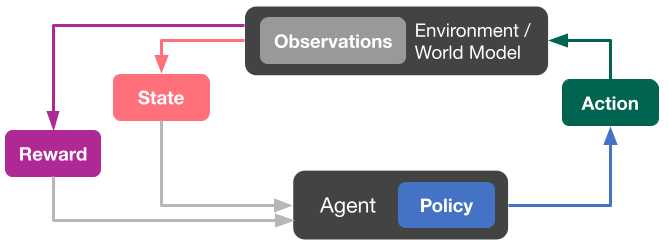
To take note of the constraints and the sequential nature of music listening, we use a reinforcement studying strategy. To keep away from letting an untrained agent work together with actual customers (with the potential of injuring person satisfaction within the exploration course of), we make use of a model-based RL strategy.
In model-based RL, the agent shouldn’t be skilled on-line in opposition to actual customers. Instead, it makes use of a person simulator, a mannequin that estimates how a person would reply to an inventory of tracks picked by the agent. Using this mannequin we are able to optimize the choice of tracks in such a means as to maximise a (simulated) person satisfaction metric. During the coaching part the setting makes use of this person mannequin to return a predicted person response for the motion beneficial by the agent. The person mannequin takes the motion (observe) and its options as inputs and makes a prediction primarily based on the present state of the setting.
The determine above exhibits the usual reinforcement studying loop, the place the motion, in playlist technology duties, is the observe to be beneficial. The setting consumes the motion proposed by the agent and makes use of the world mannequin (a person simulator) to transition to the brand new state and returns a selected reward conditioned on the motion; for instance, whether or not the person performs the observe. The agent is ready to see the brand new state and reward, utilizing them to adapt the coverage and predict the following motion to go to the setting for the following iteration. This process continues till the world mannequin alerts the termination of a selected sequence of states (known as episode).
We developed an motion head (AH) DQN agent that is ready to take care of dynamic candidate swimming pools. In specific, it is a variant of the favored DQN agent. DQN makes use of a deep neural community to foretell the advice high quality (Q) of every merchandise (motion) in a listening session. The predominant thought behind the Q community is that every obtainable observe is assigned to a selected worth (a Q worth), and the observe with the very best worth is then chosen by the agent. The reward as returned by the setting after every motion is used to replace the Q community.

Our AH-DQN community takes as enter the present state and the record of possible actions. The community will produce a single Q worth for every motion in enter, and the one with the very best Q worth is chosen as the following motion to use.
Experiments
We examined our strategy each offline and on-line at scale to evaluate the flexibility of the agent to energy our real-world recommender programs. Our recommender system goals at maximizing person satisfaction and, as a proxy, we contemplate the completion rely (and charge) on the session degree, i.e., the quantity of tracks beneficial by the coverage which might be accomplished by the person. For this activity we first practice an agent offline utilizing a non-sequential world mannequin (CWM) as person simulator, after which deploy the agent on-line to serve suggestions to the customers.
The outcomes of our person mannequin are primarily consumption-focused and summarize the likelihood of user-item interactions. Specifically, CWM has been optimized for 3 targets: completion, skip and listening period. The reward for the agent is computed because the sum of the likelihood of completion for every observe in an episode.
We evaluate our proposed agent in opposition to three various insurance policies:
- Random: a mannequin that randomly types the tracks with uniform distribution (ie, all tracks have equal likelihood of showing in a selected place);
- Cosine Similarity: a mannequin that types the tracks primarily based on the cosine similarity between predefined person and observe embeddings;
- CWM-GMPC: the person mannequin rating, which types the tracks primarily based on the expected likelihood of completion from the person.
All insurance policies take as inputs options of the person who made the request and the pool-provided set of tracks with their related options. The objective of every coverage is to pick out and order an inventory of tracks from the pool that maximizes anticipated person satisfaction, which we measure by counting the variety of tracks accomplished by the person. We carried out an A/B take a look at evaluating the beforehand described 4 insurance policies to the manufacturing playlist technology mannequin.
Offline-online correlation

We use an impartial metric mannequin in offline simulation to estimate coverage efficiency, the sequential world mannequin (SWM). This is used to estimate offline efficiency for every mannequin, which we plot alongside on-line outcomes for the insurance policies beforehand listed. The offline efficiency expectations of the evaluated insurance policies align with their on-line efficiency.
We see that the offline efficiency between the Action Head Policy (the agent) and CWM-GMPC is actually the identical. This is anticipated because the optimum coverage for an agent skilled in opposition to the pointwise world mannequin is, in reality, the grasping coverage CWM-GMPC. Online outcomes present a slight hole between these insurance policies, however the distinction is statistically indistinguishable.

By wanting on the metric comparisons within the earlier desk, we see that the likelihood of a person skipping or finishing a observe is statistically indistinguishable between the person mannequin and management. This, together with the offline-online correlation evaluation, exhibits how our strategy to mannequin person habits is correct in follow.

During additional analysis outcomes, we see how each our person mannequin rating and the agent skilled in simulation present outcomes statistically indistinguishable from management.

Finally, we additionally used an improved person simulator (SWM) to estimate offline outcomes. Based on our earlier offline-online correlation evaluation, we are able to estimate how the development offline would result in a web-based enchancment. Such offline-online correlation evaluation is prime so as to approximate what’s the anticipated enchancment that could possibly be translated on-line. Based on these predictions we hypothesize a web-based enchancment over each CWM-GMPC and AH-CWM coverage efficiency. We argue this sort of evaluation of being related in sensible functions of recommender programs the place on-line deployment requires ample anticipated enchancment over current baselines.
Some closing phrases
In this work we offered a reinforcement studying framework primarily based on a simulated setting that we deployed in follow to effectively clear up a music playlist technology downside. We offered our use case which is totally different from customary slate advice duties the place normally the goal is to pick out at most one merchandise within the sequence. Here, as a substitute, we assume now we have a user-generated response for a number of objects within the slate, making slate advice programs circuitously relevant. The use of RL additionally allows the simple implementation of extra satisfaction metrics and person alerts, in such a means that the work might be simply ported to a variety of music suggestions issues.
For extra data please take a look at our paper under:
Automatic Music Playlist Generation through Simulation-based Reinforcement Learning
Federico Tomasi, Joseph Cauteruccio, Surya Kanoria, Kamil Ciosek, Matteo Rinaldi, and Zhenwen Dai
KDD 2023
[ad_2]