{kind=link}
[ad_1]
December 5, 2023
TL;DR Large units of numerous knowledge current a number of challenges for clustering, however by a novel strategy that mixes dimensionality discount, recursion, and supervised machine studying, we’ve been capable of receive robust outcomes. Using a part of the algorithm, we’re capable of receive a better understanding of why these clusters exist, permitting user-researchers and knowledge scientists to refine, enhance, and iterate quicker on the difficulty they’re making an attempt to unravel. The cherry on prime is that by doing this, we find yourself having an explainability layer to validate our findings, which in flip permits our user-researchers and knowledge scientists to go deeper.
Understanding our customers is essential to us — one strategy to perceive them higher is to have a look at their utilization habits and determine similarities, forming clusters. And this isn’t a simple job. What knowledge ought to we use? What algorithm? How do we offer worth?
There are many established methods of clustering knowledge, — e.g., principal part evaluation (PCA) and k-means — however we wanted a approach that might each allow us to search out important clusters and in addition clarify why these clusters exist, permitting us to cater to particular teams of customers. So we seemed to develop a brand new strategy.
So a lot knowledge, so many algorithms, so few solutions
When making an attempt to reply questions associated to customers, the info may come from unfamiliar sources which might be loosely outlined and that want cautious therapy (e.g., the primary time we get responses from a survey, new knowledge endpoints, preprocessed knowledge, and many others.). In the again of your thoughts, you’ll be able to hear slightly knowledge scientist asking questions:
- What is the precise definition of every reply?
- Is the distribution of this pattern proper?
- A thousa- … how many columns did you say?!
Trying classical approaches to those questions can result in a whole lot of tables of summaries, strategies that don’t work at scale, and most significantly, no approach of explaining our analyses.
So we launched into a unique quest to assist our knowledge scientists remedy, in the beginning, the extra common downside of clustering at scale, then validating and speaking their outcomes. We in the end landed on 4 steps to deal with these challenges:
- Make the info manageable.
- Cluster it.
- Understand it (and predict it).
- Communicate it.
- Make the info manageable.
In order to make knowledge simpler to deal with, we normally attempt to visualize it. However, 1000’s of variables are sort of laborious to see. So we use some type of dimensionality discount.
And right here is after we first hit a wall. Our knowledge seemed like a blob. Round. And blobby. So what to do?
For a lot of this part, I’ll illustrate our answer to the issue with the MNIST (or Modified National Institute of Standards and Technology) dataset. MNIST has 784 dimensions to signify the written digits 0 to 9.
In knowledge science 101, you equate dimensionality discount with PCA. And right here’s what it seems like when utilized to MNIST:
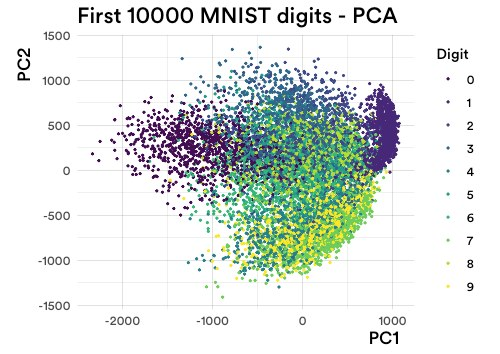
You see what I imply? Round. And blobby. Remove all colour representing floor fact, and it turns into much more tough to decipher. And in actual life, we don’t know what or if clusters even exist!
The predominant difficulty is that by having so many dimensions, all the info lives “at the edge”, aka “the curse of dimensionality”.
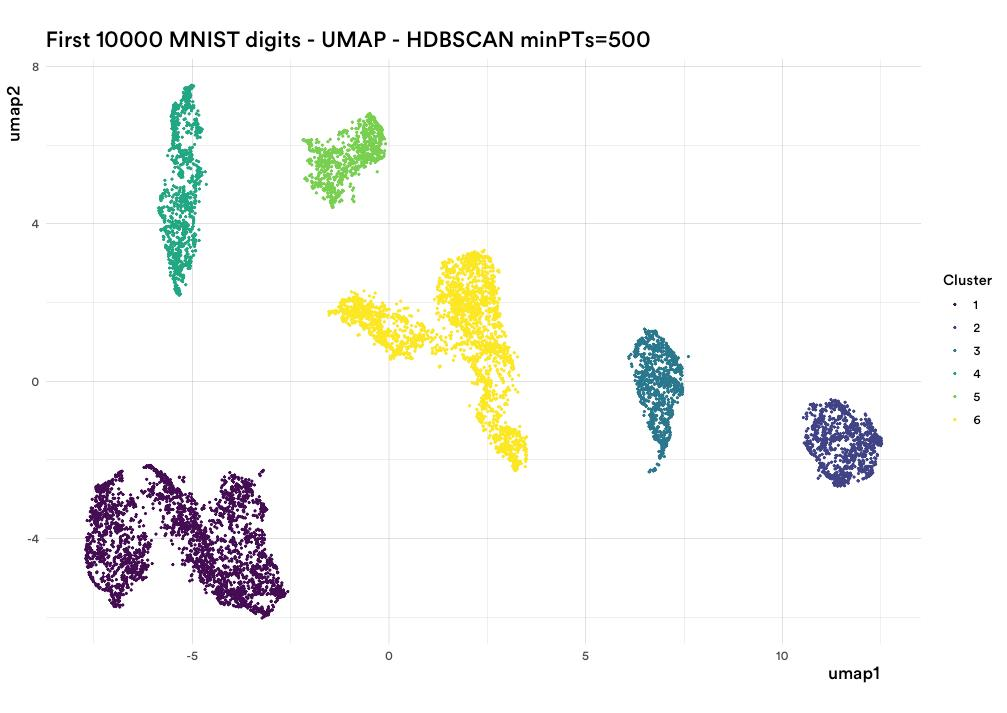
Luckily for us, prior to now few years, there have been nice advances on this space. Those advances make this curse much less related. We tried just a few of those new methods, however the one we settled upon is UMAP (or uniform manifold approximation and projection, right here). I’ll present you why, utilizing the identical knowledge as earlier than:

Not blobby. Not spherical. There’s truly some construction in there!
So now we’re executed with Step 1. The reply is, use UMAP.
- Cluster it
Now our knowledge is much less blobby, seems good(r), and is extra manageable. It’s time to start out discovering teams of factors and labeling them. It’s time to start out clustering. But what does it imply to cluster? What makes clustering good? Here’s what we expect:
- Some extent belongs to a cluster if the cluster exists.
- If you want parameters on your clustering, make them intuitive.
- Clusters needs to be secure, even when altering the order of the info or the beginning situations.
You know which algorithm doesn’t meet these three standards? Data science 101 favourite k-means.
Let me present you, as soon as once more, with Figure 2 above from UMAP. I ran k-means with ok=6. Because in Figure 2, there are six clearly outlined teams of factors (or clusters), proper?
Something much like the next:

However, k-means does this!?

Here’s what the info scientist behind your head is doing when trying on the image above:
(╯°□°)╯︵ ┻━┻
There is, nevertheless, an algorithm that meets the standards above, and that solves the issue rather well, HDBSCAN (or hierarchical density-based spatial clustering of purposes with noise). Here’s the comparability:
Your knowledge scientist can put the desk down now …
┬─┬ノ( º _ ºノ)
So it appears we’ve discovered an excellent companion for UMAP, though alternate options exist, like Gaussian combination fashions or Genie clustering. But nonetheless, among the clusters clearly have some inside construction.
And right here is after we utterly went off monitor. What if we zoom in? How can we zoom in? What does it imply to zoom in? When can we zoom in?
Recursive clustering and embedding, aka zooming in
Answering the questions above required including complexity to the algorithm.
UMAP is an algorithm that tries to keep up native and international construction of the info when doing dimensionality discount. We thought that by limiting ourselves to solely one of many clusters, we might one way or the other change what “global” and “local” meant for that individual bit of knowledge.
This is our thought of zooming in: Choose one of many clusters, maintain solely the unique knowledge factors belonging to the cluster, and repeat the method just for it.
Maybe it’s simpler to see with an instance. Take, as an example, the yellow cluster in the midst of Figure 5 above. We isolate the info factors belonging to this cluster, and we run UMAP and HDBSCAN on them.

Eureka!
It is now clear that this center cluster truly had three “subclusters”, every representing a nuanced imaginative and prescient of the unique knowledge. In this case, they’re handwritten digits. So let’s have a look at the typical picture represented by every subcluster.

Fascinating! The digits 8, 3, and 5 all have one thing in widespread. They have three horizontal sections joined by semicircles. How these semicircles are drawn differentiates them. And this clearer understanding solely seems when zooming in.
What’s much more fascinating is that we will do it for all of the clusters within the authentic image, even people who appear to not have any construction in any respect. Like the rightmost one, the blue circle.
Here’s blue circle + UMAP + HDBSCAN + common picture:

It’s a inhabitants of zeros, separated by how spherical and the way slanted they’re drawn.
One essential factor to note, nevertheless, is that this course of is probably time-consuming. Also, it’s essential to set up how deep you need to zoom in firstly. Do you actually need to zoom in on a cluster of simply 1% of your knowledge? That’s as much as you and what you need to obtain.
- Understand it (and predict it)
So far, we’ve been capable of make our knowledge manageable, and we additionally discovered some clusters. We exploited the algorithms’ skills to search out finer construction too. But as a way to do that, we repeatedly ran some very advanced algorithms. Understanding why the algorithms did what they did is just not one thing any human can do simply; they’re extremely nonlinear processes stacked one on prime of one other.
But perhaps some nonhuman statistical and machine studying course of could make sense of it.
We have knowledge, and thru the above course of, we’ve clusters for every knowledge level — knowledge and robotically generated labels. This is a typical machine studying classification downside! Luckily for us, there was an incredible quantity of growth in mannequin explainability (XAI, or explainable synthetic intelligence). So what if we construct a mannequin and use XAI to know what our UMAP + HDBSCAN + recursion is doing?
In our specific case, we determined to make use of XGBoost as a one-versus-all mannequin for every cluster. This permits for very quick and correct coaching, but additionally built-in SHAP (or Shapley additive explanations, right here) values for explainability.
By trying on the SHAP abstract plots, we will collect insights on the interior workings of our stacked processes. We can then deep dive into every of the essential options, assess the validity of every cluster, and maintain refining our understanding of our knowledge and our customers.
We also can use and deploy the mannequin in manufacturing with out the necessity to run UMAP and HDBSCAN once more. We can now use our authentic knowledge coming from our pipelines. Easy as pie, isn’t it?
- Communicate it
Once the clusters are nicely established, we will then have a look at different sources of knowledge, like demographics, on platform utilization, and many others., to additional fine-tune our understanding of who the customers are. This will oftentimes contain additional work from person analysis, market analysis, and knowledge science.
But ultimately, you’ll receive some very stable proof about every cluster.
Think a couple of presentation deck that exhibits the next:
- You have some data-driven, well-informed, totally researched clusters of inhabitants.
- You have your SHAP charts that present why the mannequin is selecting to place a person in a sure cluster.
- You have additional finely tuned analysis of these customers, pushed by the unique knowledge and augmented with focused person and market analysis. Each with its personal slide.
- You understand how essential every cluster is within the inhabitants.
- You also can have a look at different questions, exterior the scope of the unique investigation, and reply them cluster by cluster. Perhaps there’s a portion of the inhabitants that can settle for a sure function extra readily than others?
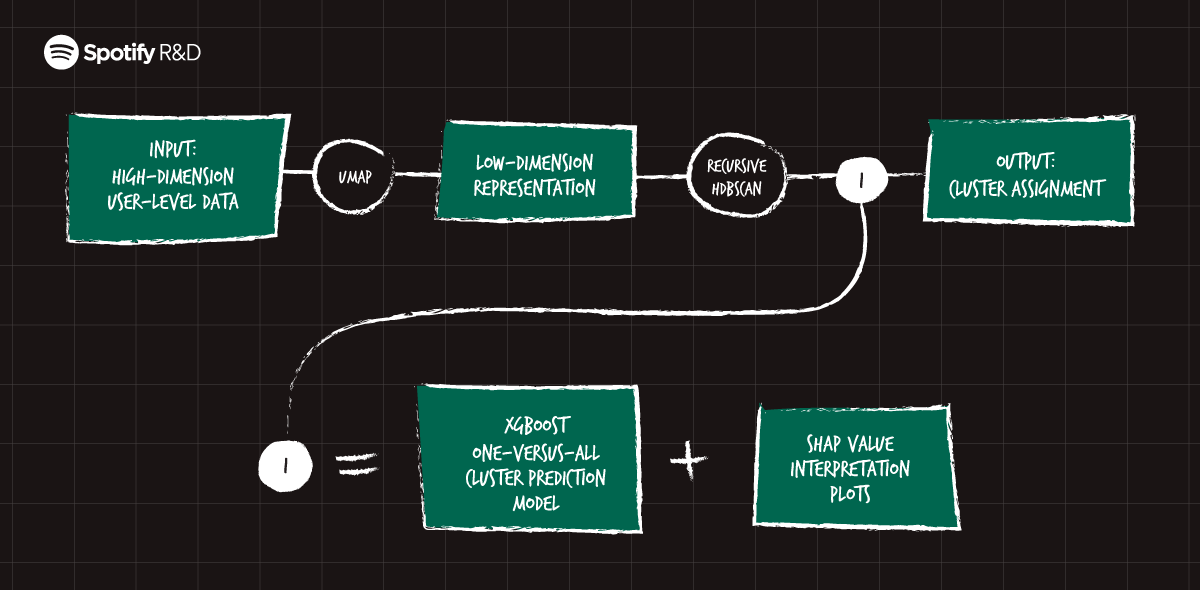
To recap the method, here’s a diagram:

This course of consists of some clearly outlined steps, most of them used earlier than. However, our predominant contribution on this course of is the novel thought of recursing (zooming in) and constructing an interpretability layer. This permits for a finer, deeper understanding of our customers from the beginning. In flip, higher data permits for extra focused analysis into every of the data-driven, but additionally qualitatively assessed, person teams, in the end resulting in the event of higher merchandise and experiences for all customers.
As for additional growth, we imagine there are alternatives to make the method much more secure and strong, so we could be extra assured in every of the clusters, rushing up the invention course of. We are at the moment engaged on this. Expect extra!
[ad_2]