{kind=link}
[ad_1]
October 13, 2023 Published by Josh Gardner, Simon Durand, Daniel Stoller, Rachel Bittner
Every day, music is loved, created, and found by billions of individuals across the globe – and but, current AI programs largely battle to mannequin the nuances that make music completely different from different types of audio.
We are thrilled to introduce LLark, a multimodal language mannequin for music understanding. In the world of music understanding analysis, there are numerous programs that may estimate particular particular person attributes of a track (tempo, chords, and so on.), and even generate quick textual content descriptions of music (referred to as “captions”). However, these fashions are usually particular to fixing a single job. In the broader discipline of AI, now we have seen thrilling progress with the creation of AI programs that may clear up an unbelievable number of duties with a single system, simply by merely asking a query or offering a set of directions to a language mannequin. Recently, this has expanded past pure textual content fashions, with AI programs capable of dialogue about photographs, video, and audio. However, there are few fashions like this for music – and people who do exist are inclined to have restricted generalization capabilities or unreliable outputs. LLark is a analysis exploration into the query: how can we construct a versatile multimodal language mannequin for music understanding?
Source: MusicWeb/Museopen/Andrew D. Lawson
Title: Quartet No 53 in D main 3. Menuetto: Allegretto
License: Creative Commons Attribution 4.0 International
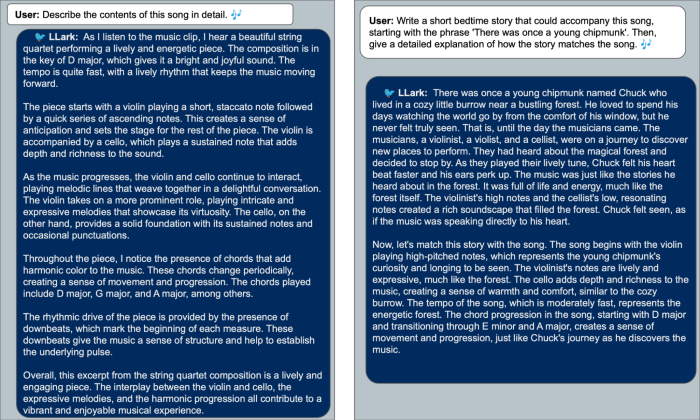
Example textual content inputs and outputs from LLark, for the offered audio. LLark is able to each conventional music duties, similar to captioning (left), in addition to extra enjoyable and complicated duties (proper).
This weblog publish introduces the important thing concepts behind LLark, how we constructed it, and what LLark is able to. If you have an interest find out extra particulars past this weblog publish, we invite you to take a look at our demo web site, open-source coaching code, or the paper preprint.
Building the Dataset
LLark is designed to supply a textual content response, given a 25-second music clip and a textual content question (a query or quick instruction). In order to coach LLark, we first wanted to assemble a dataset of (Music + Query + Response) triples.
We constructed our coaching dataset from a set of open-source educational music datasets (MusicCaps, YouTube8M-MusicTextClips, MusicNet, FMA, MTG-Jamendo, MagnaTagATune). We did this by utilizing variants of ChatGPT to construct query-response pairs from the next inputs: (1) the metadata out there from a dataset, as pure JSON; (2) the outputs of current single-task music understanding fashions; (3) a brief immediate describing the fields within the metadata and the kind of query-response pairs to generate. Training a mannequin utilizing one of these knowledge is called “instruction tuning.” An instruction-tuning strategy has the extra advantage of permitting us to make use of a various assortment of open-source music datasets that include completely different underlying metadata, since all datasets are finally reworked into a typical (Music + Query + Response) format. From our preliminary set of 164,000 distinctive tracks, this course of resulted in roughly 1.2M query-response pairs.
We can illustrate our dataset development course of with an instance. Given a track with the out there tags “fast,” “electro,” and style label “disco”, we use off-the-shelf music understanding fashions to estimate the track’s tempo, key, chords, and beat grid. We mix all of this metadata and ask a language mannequin to generate a number of query-response pairs that match this metadata. For instance, the mannequin may generate the Query/Response pair: “How would you describe the tempo of this song?” → “This song has a fast tempo of 128.4 beats per minute (BPM).” We do that for 3 several types of queries (music understanding, music captioning, and reasoning) to make sure that LLark is uncovered to several types of queries throughout coaching.
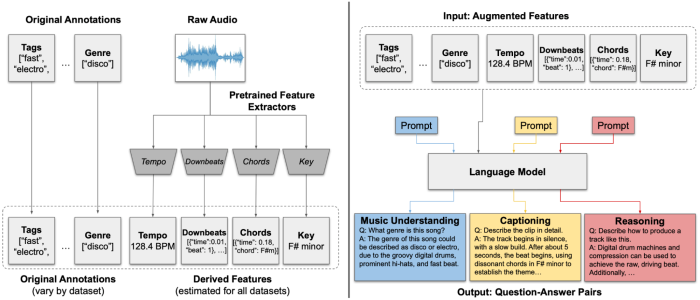
An overview of LLark’s dataset creation course of.
Model Architecture and Training
LLark is skilled to make use of uncooked audio and a textual content immediate (the question) as enter, and produces a textual content response as output. LLark is initialized from a set of pretrained open-source modules which might be both frozen or fine-tuned, plus solely a small variety of parameters (lower than 1%!) which might be skilled from scratch.
The uncooked audio is handed by a frozen audio encoder, particularly the open-source Jukebox-5B mannequin. The Jukebox outputs are downsampled to 25 frames per second (which reduces the scale of the Jukebox embeddings by almost 40x whereas preserving high-level timing data), after which handed by a projection layer that’s skilled from scratch to supply audio embeddings. The question textual content is handed by the tokenizer and embedding layer of the language mannequin (LLama2-7B-chat) to supply textual content embeddings. The audio and textual content embeddings are then concatenated and handed by by the remainder of the language mannequin stack. We fine-tune the weights of the language mannequin and projection layer utilizing a normal coaching process for multimodal massive language fashions (LLMs).
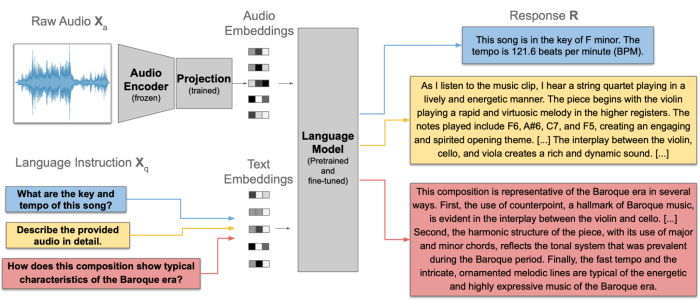
An overview of LLark’s mannequin structure. The blue, yellow and purple packing containers present instance inputs and outputs in our three job households: music understanding, music captioning, and reasoning.
Evaluating LLark’s Performance
We carried out an intensive set of experiments to guage LLark’s output in comparison with different open-source music and audio fashions.
In one set of experiments, we requested folks to take heed to a music recording and fee which of two (anonymized) captions was higher. We did this throughout three completely different datasets with completely different kinds of music, and for 4 completely different music captioning programs along with LLark. We discovered that folks on common most popular LLark’s captions to all 4 of the opposite music captioning programs.
Win fee of LLark vs. current music captioning programs.
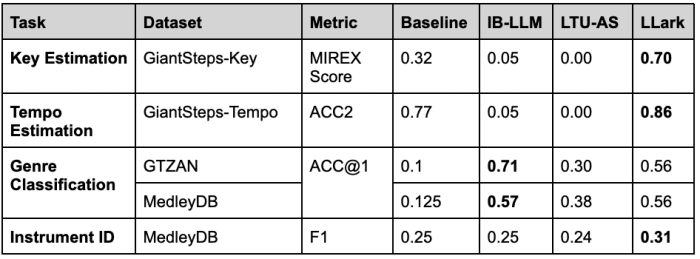
While the above experiments consider LLark’s skill to explain music, they don’t assure that the musical particulars LLark offers are correct: it’s doable that human raters can not simply assess these particulars. We carried out an extra set of experiments to measure LLark’s musical understanding capabilities. In these evaluations, LLark outperformed all baselines examined on evaluations of key, tempo, and instrument identification in zero-shot datasets (datasets not used for coaching). In zero-shot style classification, LLark ranked second, however style estimation is a troublesome and subjective job; we present within the paper that LLark’s predictions on this job are inclined to fall inside genres that the majority musicians would nonetheless contemplate appropriate (e.g., labeling “metal” songs as “rock”). We present a abstract of the outcomes under; see the paper preprint for particulars on the metrics and baselines used.
We embody a number of further experiments within the paper. Overall, our experiments present that LLark is ready to produce extra versatile and detailed solutions than any prior multimodal system to this point. These experiments additionally examine how the completely different parts of LLark – the audio encoder, language mannequin, and coaching dataset measurement – have an effect on its capabilities. If you’re within the particulars of those experiments, try the paper preprint. Our most important conclusion is that every core facet of Llark – the coaching knowledge, audio encoder, and language mannequin – contributes critically to its general high quality.
Finally, we had a number of enjoyable exploring what LLark is able to, and our paper solely offers a glimpse of LLark’s thrilling capabilities. We embody a number of extra examples of LLark’s responses to queries, together with the audio it’s answering about (all of those examples use the identical track as enter).
Source: FMA Title: Summer Wind Artist: Cyclone 60 License: Attribution-Noncommercial-Share Alike 3.0 United States

Conclusions
This publish launched LLark, our new basis mannequin for music understanding. We consider Llark is an enormous step towards the subsequent era of multi-modal music analysis. However, it’s vital to notice that LLark isn’t good – it faces a number of the similar challenges now we have seen throughout the AI group, together with generally producing “hallucinations” (producing solutions that could be vivid and overconfident however include incorrect data).
We consider strongly in accountable AI improvement. In order to honor the licenses of the open-source coaching knowledge used to coach our mannequin and the artists who made their knowledge out there by way of Creative Commons, we aren’t capable of launch the coaching knowledge or mannequin weights. However, we do launch our open-source coaching code to assist the group to proceed to advance this vital and thrilling analysis route.
We hope that our work spurs additional analysis into the event of AI fashions that may perceive music. We additionally encourage the sphere to proceed to develop high-quality open-source instruments, datasets, and fashions in order that members of the analysis group can construct the subsequent era of instruments and reliably measure their progress.
To study extra and discover out particulars about our mannequin and experiments, try our paper preprint, code, and the related web site with extra examples.
[ad_2]