{kind=link}
[ad_1]
August 18, 2023 Published by Winstead Zhu, Md Iftekhar Tanveer, Yang Janet Liu, Seye Ojumu, and Rosie Jones
TL; DR
Existing spoken Language Identification (SLI) options deal with detecting languages from quick audio clips. Podcast audio, alternatively, poses peculiar challenges to SLI as a result of its heterogeneous nature, similar to assorted period, various format and elegance, complicated turn-taking with a number of audio system, and potential existence of the code-switching phenomenon. To handle the problem of podcast SLI, we developed a two-step ML system that may successfully establish language(s) from complicated lengthy audio and effectively scale up. We evaluated the mannequin on podcast audio and confirmed that it achieves robust efficiency outcomes on the check set with a median F1 rating of 91.23%. In addition, at inference time, the mannequin can analyze and predict language for an 1-hour-long audio inside lower than 3 minutes.
Spoken Language Identification (SLI)
Spoken Language Identification (SLI) tackles the issue of figuring out languages spoken from audio enter, and thus it’s essential to the success of multilingual speech processing duties, similar to Automatic Speech Recognition (ASR) and speech translation. For instance, when utilizing the exterior Google Cloud’s multilingual Speech-to-Text service, customers are requested to specify at most 4 transcription languages, which preconditions a previous data in regards to the enter language and thus imposes a dependency on human annotation or correct metadata.
Existing SLI approaches and datasets, nonetheless, deal with tackling short-form, single-speaker audio that’s shorter in period and less complicated in construction, and thus not suited to direct software to long-form audio like podcast as a result of drastic knowledge shift. For instance, present state-of-the-art SLI programs deal with tackling audio clips which might be a couple of seconds lengthy, whereas well-known SLI datasets differ from a couple of seconds to some minutes in size.
Speaker Embeddings as Feature Input
Motivated by the remark that speaker embeddings — neural community generated vectors that embody the distinctiveness of an individual’s voice traits — additionally seize essential info related to the identification of languages, we set off by experimenting with the VGGVox speaker embeddings. VGGVox speaker embeddings are generated utilizing the well-known state-of-the-art speaker identification and verification VGGVox mannequin, which has been educated over a big set of various languages and dialects available from the VoxCelebb dataset. We investigated whether or not VGGVox speaker embeddings can function efficient characteristic enter for long-form audio SLI.
We randomly sampled 100 episodes for every of the 5 chosen languages (English, Spanish, Portuguese, French, and Japanese) and extracted a median VGGVox speaker embedding for every episode. We then used T-SNE to visualise the common embeddings in a 2D area as proven in Figure 1:
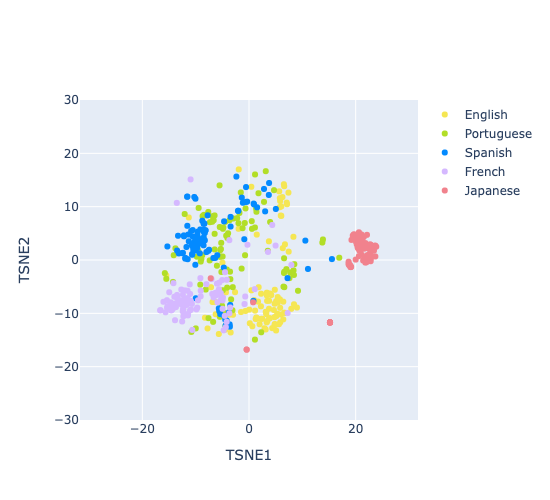
Figure 1. T-SNE plot of VGGVox speaker embeddings extracted from podcasts of 5 languages
Spanish, Portuguese, and French type their very own cluster as all of them belong to the Romance language household, whereas Spanish and Portuguese are extra overlapped with one another as a result of excessive lexical similarity. English as a Germanic language types its personal cluster within the plot, although it’s positioned fairly near the Romance language cluster as a result of the truth that English has Latin influences: a good portion of the English vocabulary comes from Romance and Latinate sources. Japanese types its personal cluster and it’s extra separated from the opposite two clusters, as most phrases in Japanese don’t derive from a Latin origin.
Overall, the T-SNE plot highlights the language distinctiveness of VGGVox speaker embeddings, proving its effectiveness as characteristic enter for long-form audio SLI.
System Architecture and Training
Motivated by utilizing VGGVox speaker embeddings as enter for long-form audio SLI, we educated a two-step SLI system (as illustrated in Figure 2) on podcast audio. The SLI system consists of two essential steps: (1) speaker embedding technology utilizing unsupervised speaker diarization and (2) language prediction by way of a feedforward neural community (FNN).
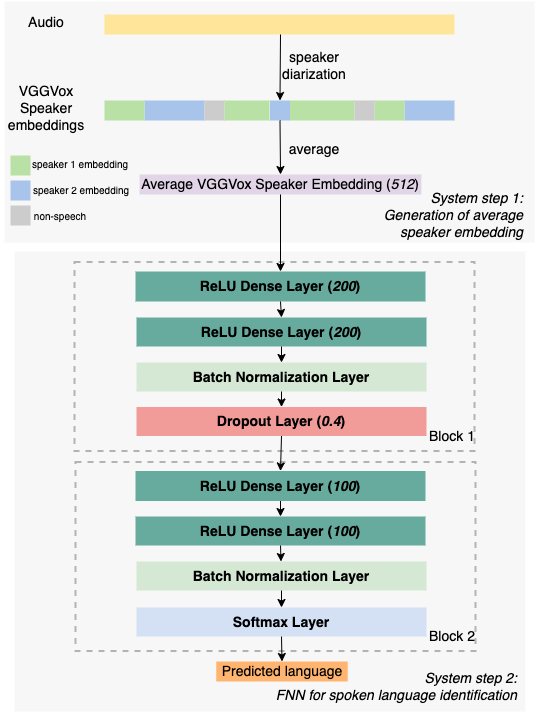
Figure 2. Two-step ML SLI system
We educated from scratch the FNN mannequin utilized in step (2) on a constructed podcast practice set consisting of 10 languages (English, Spanish, Portuguese, German, French, Indonesian, Swedish, Italian, Chinese, and Welsh), comparable to in complete 10,572 hours of podcast audio (1000 episodes had been sampled per language). During coaching, we utilized a 90%/10% practice/validation break up with a batch dimension of 10 and a dropout fee of 0.4, and we educated the mannequin for a most of 500 epochs.
Results
We evaluated our SLI mannequin on a podcast audio check set with human annotated language labels for 5 check languages (English, Spanish, German, Portuguese, and Swedish), comparable to in complete 5,485 hours of podcast audio (1000 episodes had been sampled per language). The analysis outcomes are offered in Table 1.
| Metric –––––––– Language |
Precision (%) | Recall (%) | F1 (%) | AUC |
| English (en) | 97.07 | 88.33 | 92.50 | 0.99 |
| Spanish (es) | 93.93 | 87.67 | 90.69 | 0.98 |
| German (de) | 98.15 | 88.67 | 93.17 | 0.99 |
| Portuguese (pt) | 88.46 | 88.33 | 86.74 | 0.95 |
| Swedish (sv) | 94.50 | 91.67 | 93.06 | 0.98 |
| Average | 94.42 | 88.93 | 91.23 | 0.98 |
Table 1. Evaluation outcomes on the long-form audio check set (podcast)
Overall, our SLI mannequin achieved a median F1 rating of 91.23% throughout all check languages. For benchmarking objective, we additionally ran ECAPA-TDNN (a state-of-the-art SLI mannequin educated on the VoxLingua107 dataset utilizing SpeechMind) on the identical check set, nonetheless, the ECAPA-TDNN mannequin did not run inference on episodes longer than quarter-hour as a result of Out-of-Memory error in a normal n1-standard-4 Dataflow machine, whereas in contrast our system is ready to run inference on episodes of 5 hours and longer utilizing the identical machine, and our system can analyze and predict language for an 1-hour-long audio inside lower than 3 minutes.
Code-Switching Spoken Language Identification
As a subsequent step, the present system could be readily prolonged to foretell speaker-level language(s), the place we use every particular person speaker embedding as enter with out taking common. This extension is essential for code-switching audio the place multiple language is spoken. We illustrate in Figure 3 how the prolonged system will deal with a chunk of code-switching audio taken from the Duolingo French podcast Episode 6: Le surfeur sans limites (The Surfer Without Limits), the place the mannequin predicts language for every turn-taking of various audio system.

Figure 3. Example of spoken language identification for code-switching audio
Conclusion
Spoken language identification (SLI) has been a difficult in addition to essential process for multilingual pure language processing, and current SLI options usually are not readily relevant to long-form audio similar to podcasts. In this work, motivated by the remark that speaker embeddings can successfully seize each speaker traits and language-related info, we educated a neural mannequin for long-form audio language identification utilizing speaker embeddings as enter; the mannequin achieves robust efficiency on a podcast audio dataset. We additional suggest code-switching spoken language identification as a subsequent step, which is essential for analyzing multilingual audio widespread in interviews, instructional reveals, and documentaries.
For extra element, please examine our paper:
Lightweight and Efficient Spoken Language Identification of Long-form Audio
Winstead Zhu, Md Iftekhar Tanveer, Yang Janet Liu, Seye Ojumu, and Rosie Jones
INTERSPEECH 2023
[ad_2]