{kind=link}
[ad_1]
July 24, 2023 Published by Thomas M. McDonald, Lucas Maystre, Mounia Lalmas, Daniel Russo, Kamil Ciosek

TL;DR: On on-line platforms resembling Spotify, recommender techniques are more and more tasked with bettering customers’ long-term satisfaction. In follow, this implies coaching these techniques to explicitly optimize for long-term notions of success, resembling repeat engagement or retention. This results in a very difficult cold-start drawback: when a brand new piece of content material seems, it’d take weeks or months to grasp the long-term affect of recommending that merchandise to customers. In a brand new paper that we’re presenting on the KDD 2023 convention, we argue that there’s an efficient option to tackle this drawback, by making use of intermediate outcomes noticed between making a suggestion and absolutely observing the long-term metric of curiosity.
Recommender Systems and Long-Term Goals
Recommender techniques are instrumental to the success of on-line platforms like Spotify: they assist customers discover new, related content material amongst thousands and thousands of things. Traditionally, most recommender techniques are skilled to optimize short-term notions of success: outcomes like clicks, or streams, or maybe the size of a session. The underlying perception is that driving these outcomes helps us obtain higher-level targets resembling growing customers’ satisfaction, retaining customers on the platform, and so forth. In follow, this strategy has been very efficient. But it solely works up to some extent: short-term proxies fail to seize all of the nuances of profitable suggestions, and the way they relate to long-term person satisfaction targets.
To overcome the constraints of optimizing for short-term proxies, there was an growing curiosity in optimizing recommender techniques explicitly for long-term outcomes. This could be extraordinarily profitable: At Spotify, now we have developed a podcast recommender system that optimizes suggestions for long-term success [1], and proven that it may result in massive will increase in long-term engagement. The key’s to explicitly estimate and goal primarily based on long-term outcomes, by amassing information concerning the long-term outcomes related to previous suggestions. In that particular software, we estimate the variety of days a person is prone to have interaction with a brand new present that they uncover via a suggestion over a 2-month interval.
While this strategy holds numerous promise, it exacerbates a problem that every one recommender techniques should face, the so-called merchandise cold-start drawback. The problem is as follows: when a brand new piece of content material is launched, we have to learn to advocate it. If the outcomes we use to find out about and regulate suggestions are solely noticed after a protracted delay (2 months in our podcast suggestion instance), then at first sight plainly there isn’t a means aside from to attend for a very long time to get information concerning the affect of recommending that content material. As such, within the context of this cold-start drawback, we see that there’s an obvious tradeoff between alignment and velocity:
- Short-term proxies allow recommender techniques to rapidly find out about new content material, however they could be poorly aligned with long-term success, as we mentioned.
- Long-term indicators are higher aligned, however are solely accessible after a protracted delay (by development!), making it troublesome to learn to advocate new content material.
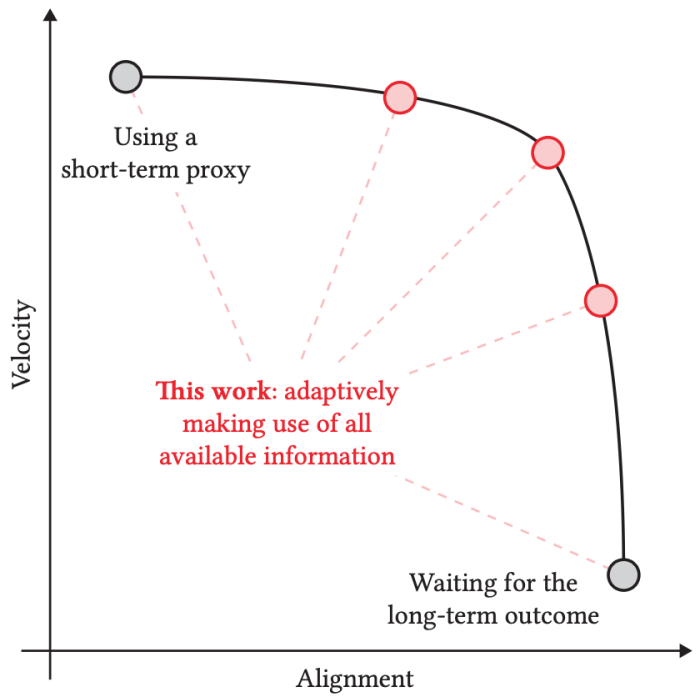
In this work, we present that this tradeoff could be circumvented, and that we don’t want to surrender on optimizing for the long-term: when new content material seems, we will do a lot better than naively ready for long-term outcomes of curiosity to be absolutely accessible. The key instinct is that, as quickly as a suggestion is made, we will begin guessing what the long-term affect shall be. Every day brings just a little bit of data that lets us refine our guess. These guesses can be utilized to drive suggestions, and we give proof that doing so could be very efficient in follow.
To examine the merchandise cold-start drawback in a rigorous means, we body it as a content material exploration activity. Starting with a set of content material which we all know nothing about, we have to make a sequence of suggestions. We take the terminology of reinforcement studying: every suggestion ends in a certain quantity of reward, quantifying the long-term success of the advice. This reward is just noticed after a protracted delay. The objective is to attenuate the cumulative remorse, i.e., the distinction between the sum of the rewards obtained over successive rounds and the theoretical optimum assuming full data. To this finish, the advice agent must discover the area of actions, but additionally rapidly determine promising actions in an effort to exploit them.
Making Use of Intermediate Observations
The concept that’s on the core of our strategy is as follows. Even although the reward related to a suggestion is just noticed after a protracted delay, we would be capable of observe intermediate outcomes, earlier on, which are correlated with the reward. This is fairly clear in our podcast software: if the reward is the variety of days a person engaged with a podcast present they found via our suggestion over 60 days, then each single day that passes after we make the advice brings just a little little bit of details about the ultimate long-term reward. Taking this to the acute: after 59 days, we should always have a fairly good concept concerning the variety of days a person engages with the present over the total 60 days.
We formalize this by assuming that the reward comparable to a suggestion, denoted by r, is a weighted mixture of intermediate outcomes, denoted by z1, …, zOkay, noticed after growing delays Δ1 ≤ … ≤ ΔOkay.
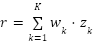
We name (z1, …, zOkay) the hint. To simplify issues, we take into account a non-contextual setting, the place we don’t search to personalize suggestions. In that case, all we have to find out about is the anticipated reward; that’s, we combine out the randomness resulting from totally different customers’ response to a suggestion. Instead of reasoning concerning the anticipated reward instantly, we as an alternative purpose concerning the anticipated hint, i.e., the anticipated worth of (z1, …, zOkay).
A key element we develop in our paper is a predictive mannequin of the reward. This reward mannequin is skilled to make predictions concerning the anticipated hint (and thus, the anticipated reward) from a dataset consisting of full and partial traces. The crux is that partial traces (i.e., traces for which now we have solely noticed the primary few parts; say the primary 5 days of engagement in our podcast instance) could be very informative and assist us make correct predictions. We focus on this reward mannequin in particulars in our paper, however we briefly spotlight two essential points:
- For every motion, we instantiate a Bayesian filter as our reward mannequin. The Bayesian framework lets us purpose concerning the uncertainty over our estimate, as we observe more and more extra info (extra traces, and extra intermediate outcomes for every partial hint). In quick, we progressively refine a Gaussian perception over the imply hint by folding in info because it arrives.
- To practice the parameters of the Bayesian filter, we make the most of historic information on comparable however distinct actions now we have noticed previously. For instance, we use full traces from earlier content material releases. The speculation is that correlations between intermediate outcomes and the long-term reward stay secure over time. This seems to work nicely, and is a vital characteristic of our strategy.
In the context of recurring podcast engagement, we observe that there are sturdy correlations between customers’ engagement within the first few days and their cumulative engagement over 60 days.
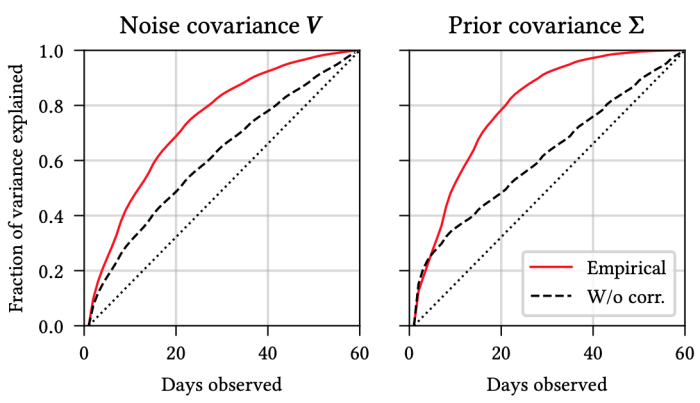
This signifies that we will begin making pretty correct inferences concerning the 60-day reward after observing simply 10-20 days of knowledge. Another perspective on that is given by the next determine, which shows the predictive efficiency as a perform of (a) the variety of traces and (b) the variety of intermediate outcomes noticed in every hint.
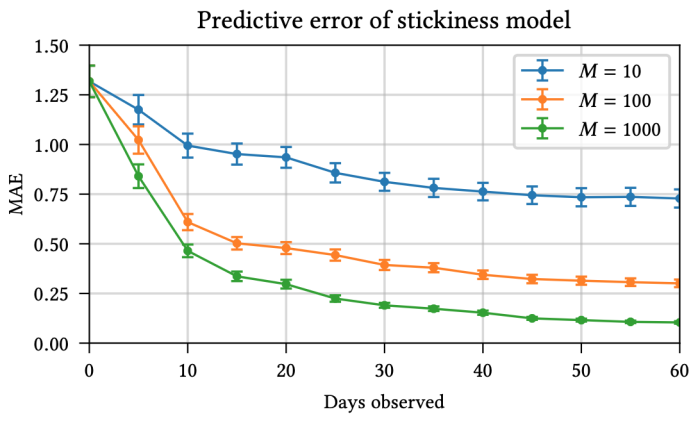
Again, we see that simply observing the primary few days permits moderately correct predictions concerning the imply long-term reward.
The Impatient Bandit
The reward mannequin, by itself, doesn’t inform us how to make suggestion choices. To choose actions at every spherical, we mix the reward mannequin with an algorithm named Thompson sampling. Informally, Thompson sampling selects actions randomly at every spherical, however with a bias in direction of actions which have both excessive anticipated reward, or excessive uncertainty (as per the reward mannequin). This bias permits us to navigate the exploration-exploitation trade-off successfully. At first, actions are chosen randomly, however progressively the algorithm converges on actions that present the largest promise.
We illustrate this on our podcast suggestion software. We evaluate variants of Thompson sampling with 4 totally different reward fashions. Starting with a pool of 200 totally different podcast reveals (actions), we run lots of of simulations and plot the common remorse in addition to the entropy of the empirical distribution over actions as time progresses.
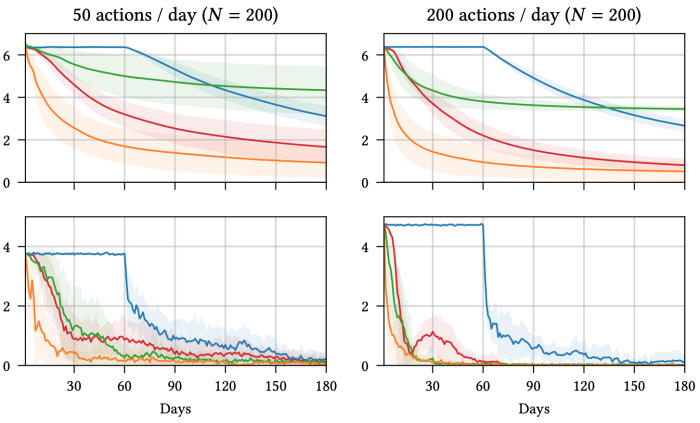
Focusing on the remorse plots (prime row), we will make the next observations.
- The blue traces symbolize a naive baseline that waits the total 60-days earlier than updating its perception concerning the long-term reward. Clearly, the suggestions loop is simply too gradual: it takes means too lengthy earlier than outcomes of early suggestions begin guiding future suggestions.
- The inexperienced traces symbolize the efficiency we would anticipate when utilizing a short-term proxy. Because of the shorter suggestions loop, the system begins studying virtually instantly. But as a result of short-term success and long-term success are usually not completely aligned, in the long term we fail to search out the perfect actions (as evidenced by the remorse not going to zero).
- The orange traces symbolize the efficiency of an imaginary “oracle” system, the place the total 60-day reward is noticed straightaway, with none delay. This is inconceivable in follow, however it’s nonetheless helpful to verify, because it gives a sure on the efficiency that any system would be capable of obtain.
- Finally, the pink traces symbolize our strategy, which depends on progressively-revealed intermediate outcomes. We see that it improves considerably on the blue and inexperienced traces. It is placing to watch that the pink line is far nearer to the orange line than to the blue one.
In conclusion, by making good use of intermediate outcomes, we will do virtually in addition to if the long-term reward was revealed instantly, directly!
For extra info, please consult with our paper:
Impatient Bandits: Optimizing for the Long-Term Without Delay
Thomas McDonald, Lucas Maystre, Mounia Lalmas, Daniel Russo, and Kamil Ciosek
KDD 2023
References:
[1] Optimizing Audio Recommendations for the Long-Term: A Reinforcement Learning Perspective.
Lucas Maystre, Daniel Russo, and Yu Zhao.
Presented on the Reinforcement Learning for Real Life Workshop @ NeurIPS 2022 (accessible on arXiv)
[ad_2]