{kind=link}
[ad_1]


This is probably essentially the most direct methodology now we have for speaking with our customers, which additionally means we have to be cautious to not interrupt their listening experiences unnecessarily. We intentionally withhold in-app messaging for some customers in order that we are able to measure its total effectiveness. These holdouts present that in-app messages have a blended impact on consumer conduct when wanting on the entire inhabitants, demonstrating that we’d profit from concentrating on customers extra selectively for in-app messaging.
We believed that we might use ML to determine in-app messaging eligibility and that by doing so we might enhance consumer expertise with out harming enterprise metrics. We mentioned quite a few attainable options to this drawback however determined to deal with uplift modeling, the place we attempt to instantly mannequin the impact of in-app messaging on consumer conduct.
It’s clear that in-app messages have a special impact on completely different customers, which is called a heterogeneous remedy impact. We have some customers which may take pleasure in Spotify Premium and would profit from receiving a message prompting them to subscribe. We even have customers which might be pleased with their present product providing, the place messaging wouldn’t profit both the consumer or Spotify. Our job, then, is to foretell the impact of in-app messages on customers. In specific, we needed to know the causal impact of sending in-app messages.
The current literature on causal inference is intensive, however in our case, such studying is comparatively easy as a result of we have already got the randomly assigned holdout group mentioned earlier. In the language of causal inference, we had been in a position to make use of this holdout to measure the common remedy impact — i.e., the impact on consumer conduct averaged throughout all the inhabitants of customers.
Given our heterogeneous remedy impact, we need to goal particularly these customers that will profit from in-app messages, that means we’d like to have the ability to predict the conditional common remedy impact (CATE), given in equation kind as:
CATE(x)=E[Y(1) - Y(0) | X=x]
In this equation, Y(t) represents the end result given remedy t and X represents the options used to determine completely different subgroups of customers. The CATE is subsequently the anticipated worth of impact dimension conditioned on consumer options. As a machine studying (ML) drawback, we need to practice a mannequin that approximates this perform, which we are able to then use to determine which customers to focus on for in-app messaging.
The difficult half right here is that we can not observe the CATE instantly, as a result of there is no such thing as a option to each give and never give a consumer a remedy. Fortunately, we are able to use the identical holdout information that we used for estimating the common remedy impact for coaching this mannequin. We can observe consumer options, remedy project, and outcomes and use these to study the uplift rating utilizing a so-called metalearner.
The two easiest types of metalearner are the S-learner and the T-learner. In each formulations now we have consumer options u and remedy values t. In the S-learner, we study a mannequin ŷ(u, t) and calculate the uplift as:
ŷ(u) = ŷ(u, 1) - ŷ(u, 0)
This is contrasted with the T-learner, the place we study two fashions, ŷ0(u) and ŷ1(u), and calculate the uplift as:
ŷ(u) = ŷ1(u) - ŷ0(u)
Our mannequin takes inspiration from each the S-learner and the T-learner, in addition to the multiheaded Dragonnet, in that we don’t embrace the remedy as a characteristic for the mannequin, however we additionally study just one mannequin. We have some shared a part of the mannequin, which is identical for each remedy and management, the output of which is fed into completely different prediction heads for every remedy.
This work is motivated by in-app messaging’s competing results on completely different enterprise metrics, so we care not solely about two completely different remedies but in addition two completely different outcomes. We subsequently find yourself with 4 completely different outputs from the mannequin:
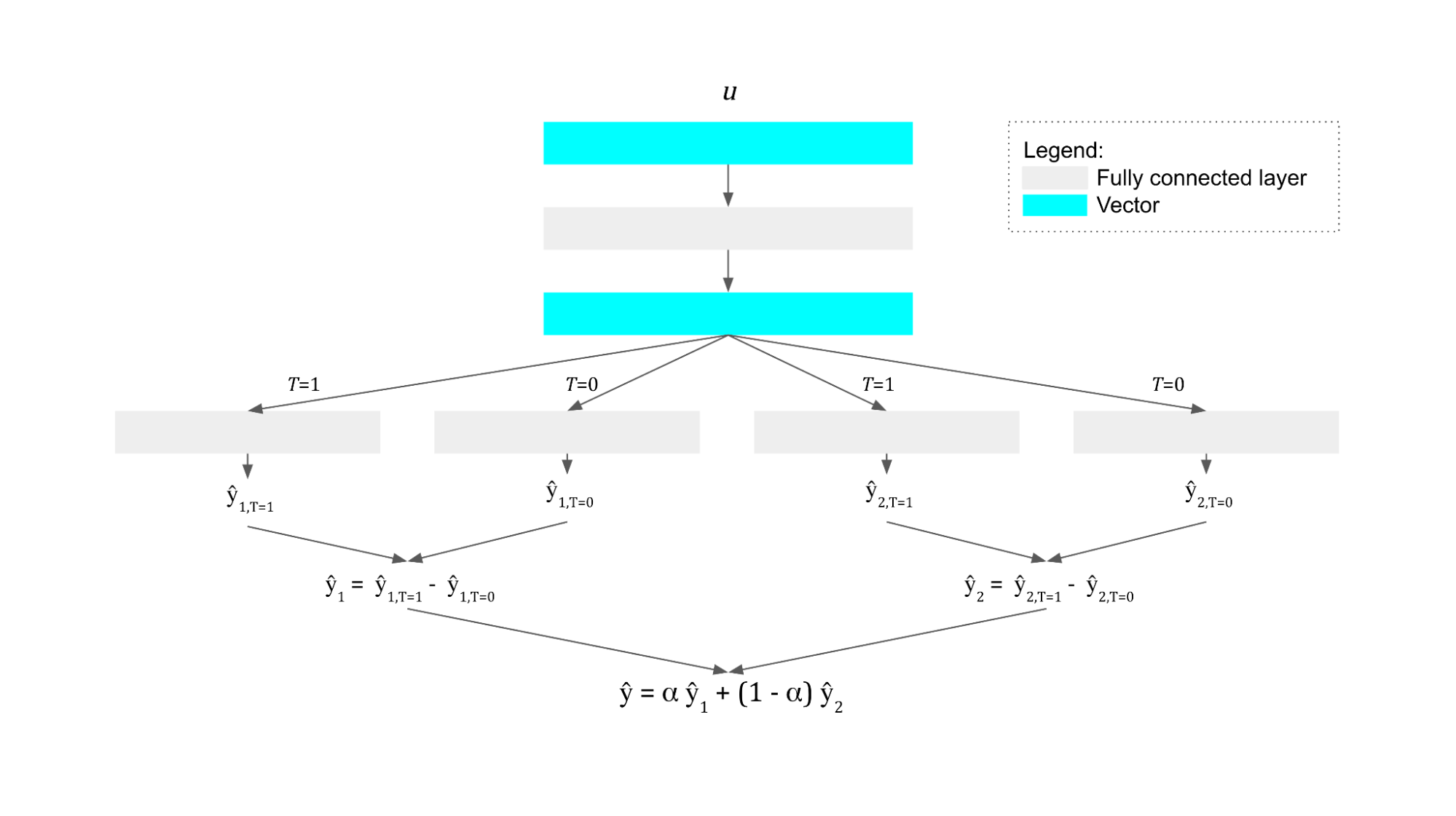
As Figure 3 above exhibits, for every consumer enter, we calculate uplift for our two metrics of curiosity after which take a weighted common of those two outputs to supply a remaining uplift rating, ŷ. If ŷ>0, then the consumer is taken into account eligible for in-app messaging. The worth is chosen by hyperparameter tuning and a few enterprise logic.
For a given coaching instance, we all know the remedy chosen and subsequently the anticipated outputs of precisely two of the heads. By conditioning the loss perform on the motion chosen, we are able to practice a mannequin on all 4 outputs concurrently, with every instance contributing to the replace of precisely two heads in addition to the widespread a part of the mannequin.
Before operating an A/B check, we have to have a greater thought of how the mannequin performs. We might observe a lowering loss on our held-out check set, however that wouldn’t inform us how the mannequin would do on the duty we really need to use it for. In specific, we want to know if utilizing the mannequin would have a major impression on enterprise metrics.
To perceive our analysis, it’s crucial first to know some ideas associated to contextual bandits. Without going into element, within the bandit drawback house now we have an agent that chooses from accessible actions in response to some coverage with a view to maximize some reward. A contextual bandit is basically a mannequin for choosing one out of a set of attainable actions. In different phrases, a contextual bandit is a mannequin that takes options and outputs an motion or distribution over actions. It’s not a lot of a stretch to consider our mannequin as a contextual bandit; deciding to permit messaging if the weighted common of uplift scores is above some threshold is a coverage.
Using the identical randomly collected holdout information used for coaching, we are able to use offline coverage analysis to guage a coverage with out operating it on precise customers. The three insurance policies we care about are: send-to-all, send-to-none, and the uplift mannequin. By doing this offline analysis, we had no less than some proof that we’d not be harming Spotify’s enterprise by operating this check on such an vital channel of messaging.
Test and subsequent steps
We A/B examined our mannequin and noticed a major enchancment in consumer retention, so we rolled out the mannequin, and it has been in manufacturing since. The enterprise worth of the mannequin is obvious due to the sustained impression on consumer retention (as proven within the graph under); nevertheless, we predict there may be nonetheless extra profit to be gained from this work.
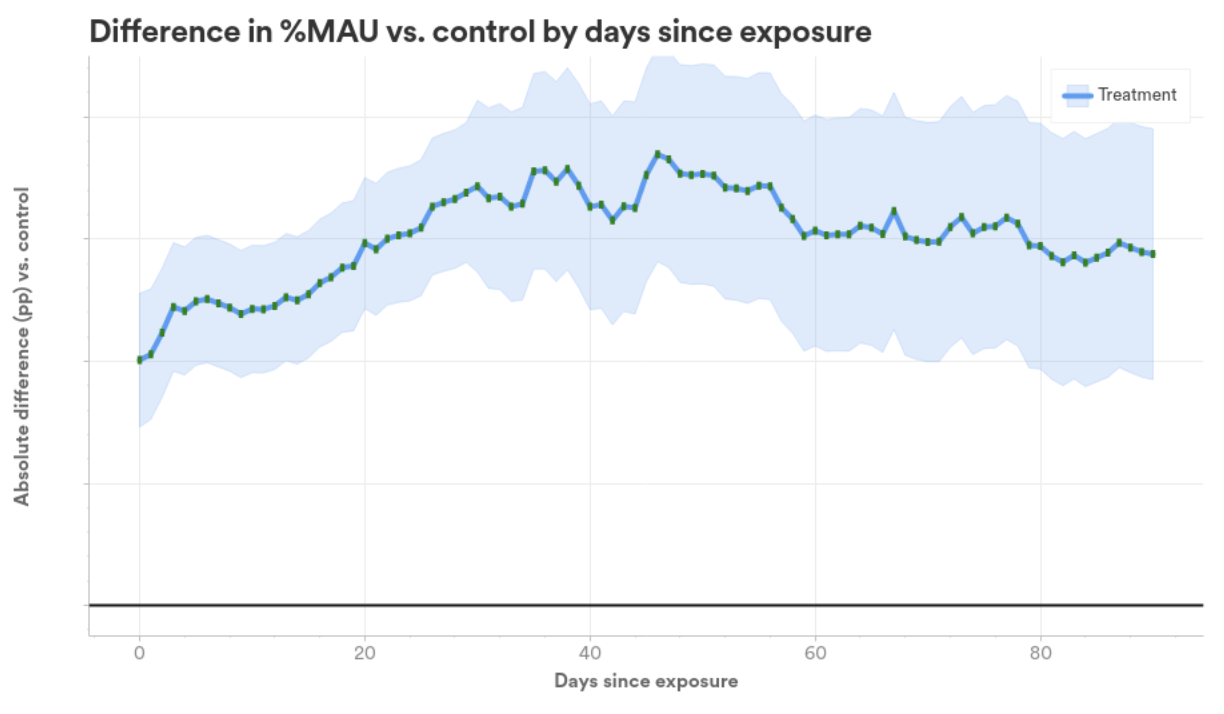
We’ve seen on this weblog put up the applying of ideas from causal inference to focus on in-app messaging eligibility. We took inspiration from an current uplift mannequin structure to do multi-task studying to steadiness completely different results of in-app messaging on consumer conduct, and efficiently rolled out this method and are actively engaged on enhancing the mannequin by permitting a extra dynamic messaging weight-reduction plan, which we imagine will carry higher worth to each Spotify and our customers.
[ad_2]