{kind=link}
[ad_1]
May 15, 2023

Check out Part 1 and Part 2 of our collection on Fleet Management at Spotify and the way we handle our software program at scale.
For the third a part of this Fleet Management collection, we’ll focus on what we name “fleet-wide refactoring” of code throughout 1000’s of Git repos: the instruments we’ve constructed to allow fleet-wide refactoring and make it an on a regular basis incidence, how we rolled them out, and classes we’ve discovered alongside the way in which.
Why do we’d like fleet-wide refactoring?
As talked about in Part 1 of this collection, Spotify’s codebase is unfold out throughout 1000’s of Git repos. We use a polyrepo format — every repo accommodates one or a small variety of associated software program parts out of the 1000’s of parts we run in manufacturing (the codebase for our desktop and cell shoppers is laid out in a different way, in monorepos). This format has grown out of wanting every particular person staff to have sturdy possession of their parts, independently creating and deploying them as they need.
While having many repos favors particular person staff autonomy, a lot of the supply code in these repos has dependencies on different components of our codebase dwelling in different repos. For instance, a big proportion of our backend providers is constructed on an inside service framework and set of core libraries, and most batch information pipelines are written utilizing Scio. Updating each considered one of these repos for each change or bugfix within the framework or core libraries would require an enormous effort, and, prior to now, this might not be performed rapidly — as talked about within the earlier put up, it will normally take 6+ months for every new launch of the backend service framework to succeed in 70%+ adoption in our backend service fleet.
As the variety of parts we run in manufacturing has grown — at a quicker charge than the variety of engineers — making adjustments that contact all or most of our fleet of parts has develop into harder.
To change our growth practices to be fleet-first, in 2021, we determined to spend money on creating the tooling and infrastructure to allow fleet-wide refactoring. Our imaginative and prescient is that engineers ought to consider and be capable to make adjustments to our total fleet of parts directly, slightly than enhancing them one after the other. For instance, a staff that produces a library or framework that different groups use ought to not consider their work as performed after they lower a brand new launch and announce it’s prepared for use — the work is completed after they’ve up to date all of Spotify’s code to make use of that new launch. Rather than sending an electronic mail asking different groups to make a code change by some deadline, platform groups ought to now tackle the work of constructing that change fleet-wide throughout our total codebase, regardless of what number of repos it impacts or who owns these repos. Someone discovering a efficiency optimization ought to really feel empowered to make that optimization in all places.
To make a lot of these adjustments simple and customary whereas nonetheless having code in 1000’s of repos, we wanted to take away “the repo” as a barrier or unit of labor and to encourage engineers to cease considering by way of “my code” and “your code”.
This work has damaged down into two primary areas:
- Managing the dependencies of most parts with automation and making it very simple for engineers to replace the actual model of a library used throughout your entire fleet
- Enabling engineers to simply ship pull requests to a whole lot or 1000’s of repos and managing the merge course of
Actively managing dependencies with automation
When we determined to spend money on fleet-wide refactoring, we had already been utilizing a BOM (“Bill of Materials”) in our Apache Maven–primarily based backend providers and libraries for a couple of 12 months. A BOM specifies the to-be-imported model for a lot of artifacts in a single artifact. Our BOM (which we name “the Java BOM”) was created to cut back the quantity of complications when upgrading libraries in a backend service, since we’ve so many libraries that rely on one another — for instance, Guava, Google Cloud libraries, grpc-java, our personal inside frameworks, and so forth. By making a single artifact that may management what model of many different libraries is used, we are able to improve particular person repos to make use of newer dependencies by updating only a single line within the pom.xml file.
Using a BOM to manage what particular model of often-used dependencies is pulled into every element additionally permits us to vet which variations of which libraries are suitable with one another, saving particular person engineers from having to try this themselves throughout many parts and groups. Compared with different instruments like Dependabot, utilizing a centralized dependency administration manifest similar to our Java BOM permits us to seamlessly improve many libraries directly whereas ensuring that they’re all suitable with one another. Every time anybody at Spotify proposes an replace to our BOM to replace the particular model of a library or add a brand new library, we run a collection of exams to test the compatibility of all libraries towards one another.
One of the primary choices in our fleet-wide refactoring effort was to speed up using our Java BOM in our Maven-based backend providers. Instead of groups opting in to utilizing the BOM, we’d mechanically onboard all backend parts to make use of the BOM, producing pull requests (PRs) for each repo. In addition, we determined we’d mechanically merge these PRs into these repos so long as all of the exams have passing scores (extra on this beneath in “Getting automated code changes into production”).
Today we’ve a really excessive adoption charge of the BOM in our manufacturing backend providers — at present 96% of manufacturing backend providers use our Java BOM and 80% are utilizing a BOM model lower than seven days outdated (a streak we’ve saved up for 18 months). With this excessive adoption, engineers at Spotify can replace the model of a dependency through a single pull request to the BOM repo and be assured that it’s going to mechanically roll out to almost all backend providers within the subsequent few days. This supplies a really handy distribution mechanism for groups who personal libraries that others rely on — so long as the adjustments are backward suitable.
We targeted first on automated dependency administration for our backend parts because of their massive quantity (1000’s in a microservice structure). We’ve since repeated this effort for our batch information pipelines utilizing Scio. 97% of Scio-using pipelines use an sbt plugin that manages the model of most libraries utilized by the pipeline code (appearing just like a BOM), and 70% of pipelines on common are utilizing a model of the artifacts lower than 30 days outdated. We at the moment are seeking to repeat this “BOM-ification” for our Node-based internet parts (inside and exterior web sites) and Python-using parts, to centralize and higher management variations of the entire dependencies getting used.
Being capable of simply handle and replace the dependencies that our fleet of software program parts makes use of has had huge safety advantages. As talked about in Part 1, when the notorious Log4j vulnerability was found in late 2021, 80% of our manufacturing backend providers have been patched inside 9 hours. There has been one other profit to having a majority of parts use the identical variations of generally used dependencies — it’s simpler to put in writing code refactorings for your entire fleet when most parts are utilizing the identical variations of dependencies.
Fleetshift: the platform we use to alter code in lots of repos directly
The engine we use to automate fleet-wide code adjustments throughout all our repos is an in-house device known as “Fleetshift”. Fleetshift was initially a hack challenge created by a single engineer as a successor to an extended line of homegrown scripts for producing bulk pull requests, and was then adopted by the fleet-wide refactoring initiative and made a typical device, just like the BOM.
We deal with Fleetshift as a platform — a single staff owns it and different refactoring instruments, and this staff focuses on making the method of a fleet-wide change ever simpler, whereas different groups use these instruments to truly execute their fleet-wide code adjustments. This separation in possession and accountability is essential to scale up the variety of automated fleet-wide adjustments and to embrace the fleet-first mindset company-wide. Each staff at Spotify that produces a platform, library, SDK, API is the perfect staff to deal with and automate the rollout of that change to your entire fleet — we don’t need to have a single “refactoring team” answerable for rolling out different groups’ adjustments, as that may create a bottleneck and adversely have an effect on what number of fleet-wide adjustments we are able to realistically make.
Fleetshift makes fleet-wide code adjustments by basically working a Docker picture towards every repo. An engineer desirous to make a fleet-wide code change wants to produce a Docker picture that may refactor the code, utilizing both off-the-shelf instruments (similar to sed, grep, and so forth.) or writing customized code. Once the refactoring is prepared, the Docker picture is handed over to Fleetshift to run towards every of the focused repos. Fleetshift clones every repo and executes the Docker picture towards the checked-out code — noting any modified/added/eliminated information and making a Git commit for the change — after which generates a pull request to the unique repo. The writer of the shift specifies the commit message and PR title/description within the shift configuration in order that the receiver of the automated change can perceive what’s being modified and why. Authors can monitor the progress and different particulars of their shift on our inside platform, Backstage.
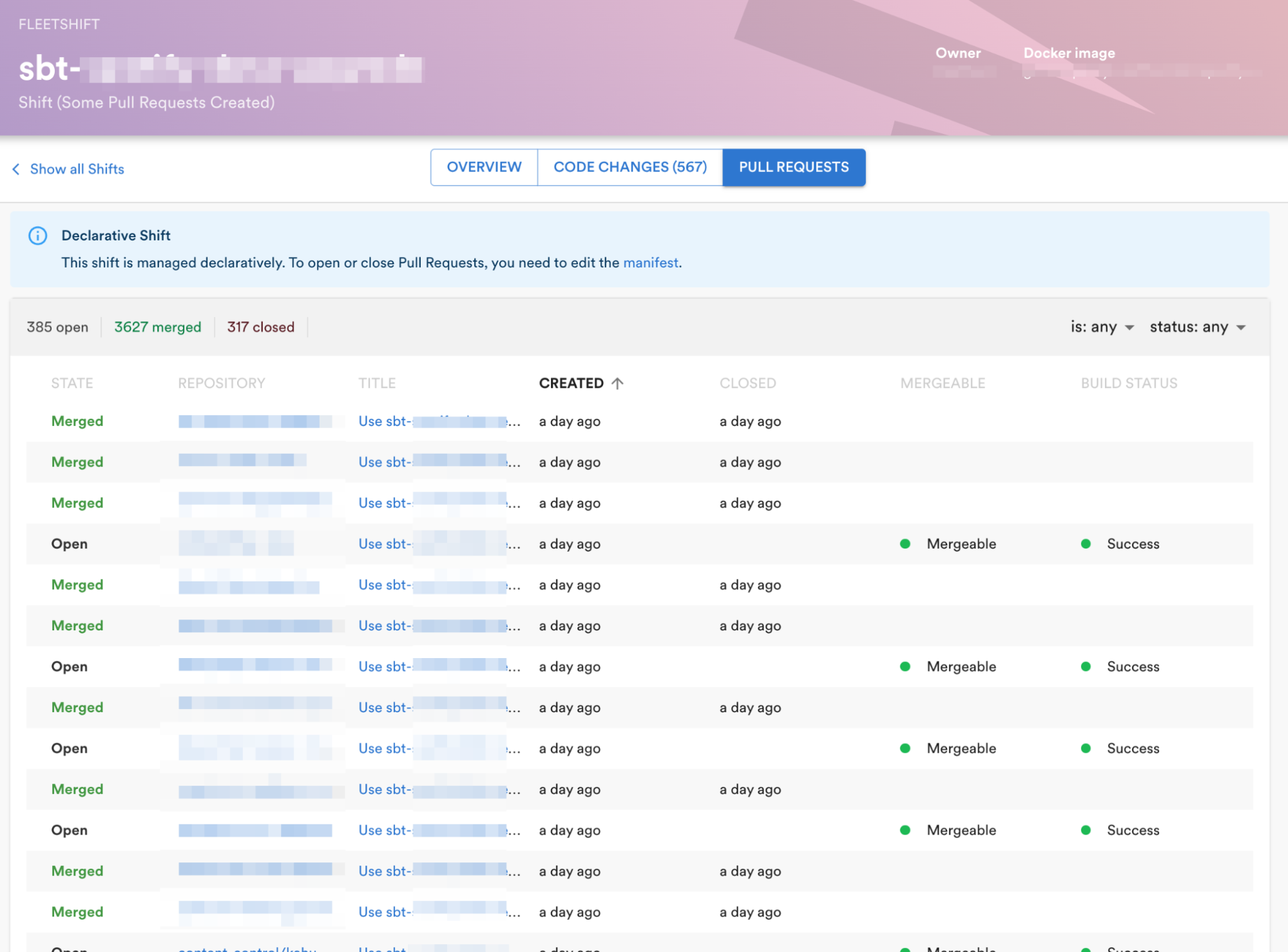
The innovation in Fleetshift is to make use of our massive present Kubernetes infrastructure (a number of thousand nodes throughout dozens of clusters) to do the work of cloning repos, executing code transformations and pushing adjustments again to our GitHub occasion. Previous generations of in-house instruments like this might do the entire work on a person engineer’s laptop computer, creating an obstacle for any engineer courageous sufficient to aim a fleet-wide code change. Fleetshift runs code transformations on repos as Kubernetes Jobs, leveraging the parallelism and autoscaling inherent in Kubernetes to make it equally as simple for an engineer to kick off a code transformation concentrating on ten or a thousand repos. Code transformation/refactoring jobs run on what are successfully the spare cycles of the identical computing infrastructure that powers Spotify’s backend.
Another innovation in Fleetshift is to mannequin the code transformation that the writer needs to make as a Docker picture. Fleetshift helps any sort of code change, so long as you possibly can write the code to make that change and put it right into a Docker picture. The instruments that we use at the moment to energy our fleet-wide refactorings run the spectrum from shell scripts that make comparatively easy adjustments to utilizing OpenRewrite and Scalafix for making subtle AST-based refactorings.
Shifts may be run as soon as or configured to run each day (each weekday). Recurring shifts are helpful for continuous adjustments, such because the shift that updates the Java BOM model in every backend element day by day or that updates all shoppers of our inside base Docker photographs to the most recent launch day by day.
Shifts are modeled as a customized Kubernetes useful resource, and Fleetshift itself acts as an operator constructed on high of our declarative infrastructure tooling. The shift useful resource is saved as a YAML file in a GitHub repo identical to some other code at Spotify in order that launching or iterating on a shift means making pull requests, getting code critiques, and so forth.
apiVersion: fleetshift.spotify.com/v1
sort: Shift
metadata:
title: update-foobar-sdk-to-v2
namespace: fleetshift
spec:
container:
picture: example-shift:1.2.3
pullRequest:
title: replace foobar-sdk to v2
commitMessage: replace foobar-sdk to v2
description: |
The PR updates the foobar-sdk from v1 to v2 and refactors code calling now-removed strategies in v2 to make use of their counterparts as an alternative.
You can see a full changelog [here](hyperlink).
If you have got any questions please attain out to #foobar-team-channel
targetRepos: [ ... ]An instance shift useful resource.
To discover which repos to run their shift towards, authors can use both GitHub seek for primary queries or BigQuery for extra subtle searches. (We ingest all of our supply code from GitHub into BigQuery each day to permit for looking and becoming a member of towards different datasets — for instance, to seek out all repos containing manufacturing information pipelines calling a selected methodology and in addition utilizing model 2.3 of some library.) The listing of repos to focus on may be configured immediately within the shift useful resource or may be saved in a BigQuery desk, which is helpful for recurring shifts that run each day and would possibly want to focus on a distinct set of repos every day (as traits of the supply code in these repos change over time).
Similar to our Java BOM, Fleetshift already existed and was utilized by a handful of groups after we determined to speculate extra closely in fleet-wide refactoring. In order to decrease the quantity of friction first-time customers would possibly encounter, the Fleetshift platform homeowners additionally preserve a set of reusable Docker photographs that others can use or construct on for his or her specific fleet-wide code refactoring. Common constructing blocks embody Docker photographs for mutating YAML information, bumping the model of a specified Docker picture to the most recent launch, and doing Java AST-based refactoring with OpenRewrite. We additionally preserve a data base and documentation hub on how you can accomplish sure forms of refactoring duties in numerous languages so that each one groups who’ve a necessity to alter code fleet-wide can be taught from one another.
Getting automated code adjustments into manufacturing
To successfully change code throughout all of our repositories, it isn’t sufficient to have the ability to use automation like Fleetshift to generate a whole lot or 1000’s of pull requests at a time — the adjustments additionally should be merged. A typical engineering staff at Spotify would possibly preserve a number of dozen repos, with these repos receiving various quantities of consideration relying on how secure or lively every element is. It would possibly take weeks or months for an automatic code change despatched to numerous repos to see nearly all of the pull requests be merged by the homeowners. If our purpose is to make it a typical on a regular basis exercise for engineers to refactor code throughout the entire firm — growing the quantity of bot-created code adjustments — we additionally need to keep away from overwhelming engineers with the necessity to evaluate all of the adjustments to all their repos. This is a matter we noticed even earlier than we determined to make fleet-wide refactoring simple, when utilizing open supply instruments like Dependabot or homegrown scripts to ship pull requests — getting the lengthy tail of pull requests merged to finish the fleet-wide change takes loads of following up and asking groups to evaluate and merge the PRs.
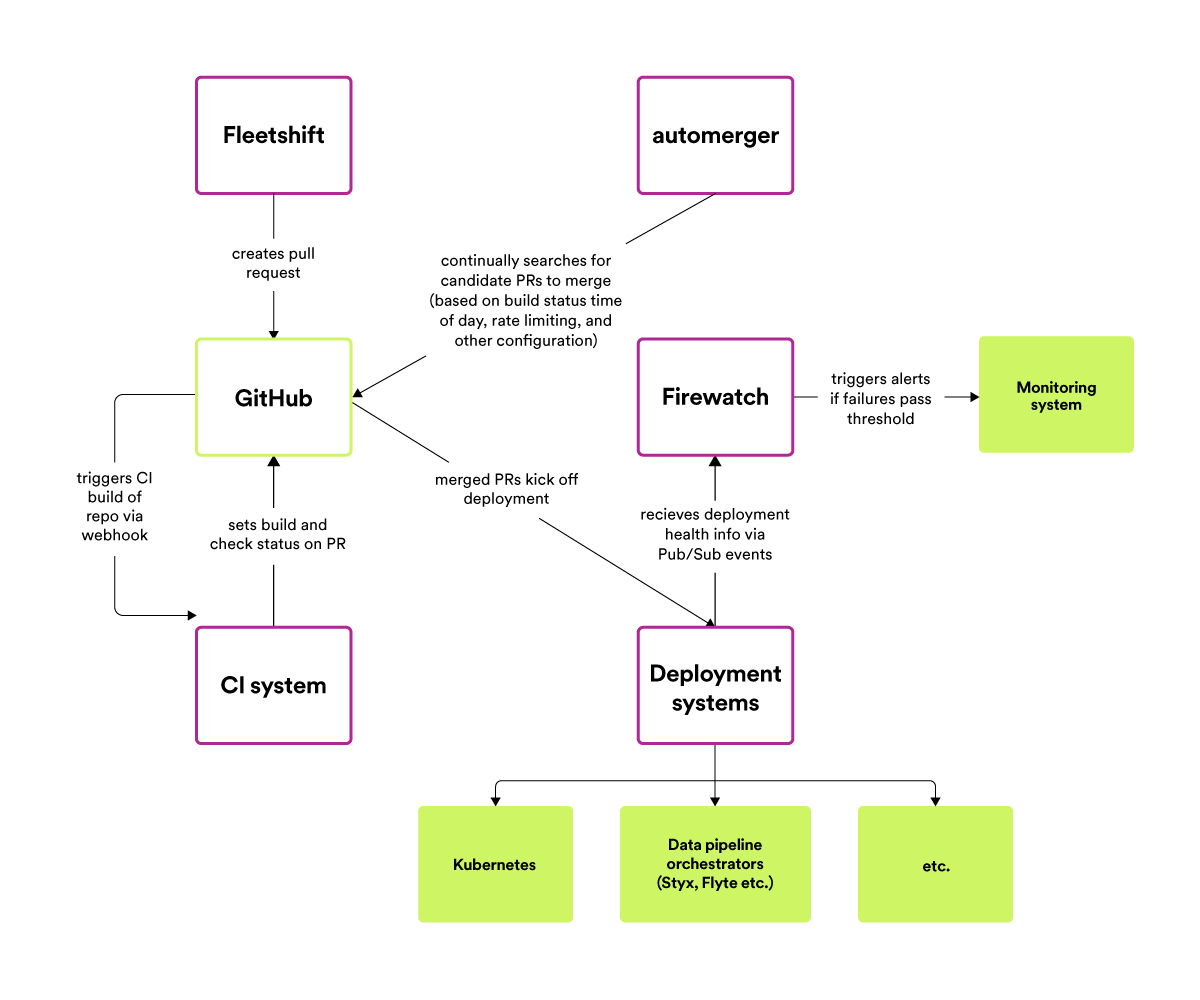
Our resolution is to take away the necessity for guide human critiques — we’ve constructed the aptitude for authors to configure their automated refactoring to be mechanically merged, so long as the code change passes all exams and checks.
To do that, we constructed one other new infrastructure service — creatively named “automerger” — which accommodates the logic of how and when to carry out an automerge. While GitHub now has a built-in automerge function for pull requests, writing the code ourselves permits us to specify precisely how and after we need adjustments to be automerged. We invert management on who decides what’s automerged, from the repo proprietor to the change writer, and we additionally management the speed at which adjustments are merged to keep away from overwhelming our CI/CD techniques. Additionally, to cut back the probabilities of surprises or incidents, we solely automerge adjustments throughout working hours for the repo-owning staff, and by no means on weekends and holidays.
We will solely automerge a change right into a repo so long as it passes all of the exams, but when the exams of the repo aren’t adequate to check sure forms of dangerous adjustments, this can be a sign to the proprietor that they need to be including extra and higher exams to their repo. To assist groups monitor the readiness of their particular person parts for automerging, we created new Soundcheck packages and checks in our inside Backstage occasion. Teams use these to observe the code well being of the parts they personal and whether or not or not they’re assembly our requirements for testing, reliability, and code well being. For instance, these checks permit homeowners to trace which parts are utilizing our Java BOM (or different centralized dependency administration manifest), which parts may be lacking integration exams, or if their backend service just isn’t utilizing well being checks on their deployments.
Introducing automerging as an idea to our growth practices has acted each as a stick and a carrot — we are able to solely automate code upkeep duties for you if in case you have adequate exams. Your code additionally must go adequate exams to keep away from dangerous adjustments from being merged into your code. We’ve seen groups motivated to enhance the Soundcheck scores of their parts in order that the platform and different groups can handle and mechanically refactor extra features of their code.
While most parts have complete pre-merge take a look at suites which might catch any potential “bad” change and stop it from being automerged, we don’t need to depend on pre-merge testing alone to catch issues in automated fleet-wide refactoring. Once an mechanically generated pull request is automerged, we monitor the well being of the affected element by consuming Pub/Sub occasions from our backend deployment and information pipeline execution techniques, in a service we name Firewatch. Each pull request that’s automerged is registered with Firewatch in order that it could possibly correlate failed backend service deployments or information pipeline executions with potential automerged adjustments into their repos. If Firewatch notices that too many mechanically merged commits have failed backend deployments or pipeline executions related to them, it alerts the homeowners of these automated adjustments in order that they’ll examine.
The preliminary rollout of automerging was performed very slowly and was initially supposed just for the Java BOM–updating shift. Backend parts have been divided into phases primarily based on how essential they have been, and automerging of the BOM updates was step by step enabled for one part at a time. This allowed us to construct confidence within the security of the automerger and our potential to observe the well being of parts post-merge, whereas on the identical time growing adoption and utilization of the BOM to the 90%+ charge it’s at at the moment.
The preliminary sluggish rollout of merging adjustments with no human reviewing each single PR proved each the usefulness and security of automerging as an idea, and at the moment we use automerging for a number of dozen shifts day by day, for each easy dependency bumps and extra subtle refactorings.
During the preliminary rollout of automerging, a aware choice was made to deal with automerging as one thing you would need to decide out of in case you didn’t need it, slightly than one thing it’s essential to decide into. We consider this choice helped to make automerging such a profitable and widespread observe at the moment, because it was handled as a default from the very starting. When a staff needs to opt-out a repo from automerging, we require them to doc a motive and encourage them to set an expiration date on the opt-out in order that they really feel incentivized to repair no matter is inflicting them to not belief within the automation. Additionally, our most important repos have one other set of constraints and checks that they need to go earlier than we are able to automerge any change to them. As a results of treating automerging as one thing that should be opted out of slightly than into, solely about 50 out of 1000’s of repos at the moment are at present opting out. We usually see groups which have added an opt-out come again and take away the opt-out earlier than it expires, as soon as they’ve mounted the underlying problem and are prepared for automerging.
One lesson we’ve discovered from introducing automerging for some forms of automated adjustments: as soon as individuals recover from the preliminary worry of robots altering their code with out their approval, their common perspective towards the subject has not been reluctance however wanting extra. Far extra groups and engineers than we anticipated ask why sure automated adjustments aren’t being automerged, and the change-consuming groups have been recognized to ask the change producers to allow automerging. We have discovered that almost all engineering groups don’t need to be bothered to should evaluate and merge every PR to replace a library to the most recent patch launch or bump the model of a Docker picture utilized in a construct — and they’re completely satisfied for groups from whom they devour code to deal with refactoring their code to make use of new variations of frameworks or APIs as wanted.
Not all automated code adjustments despatched by Fleetshift are configured to be mechanically merged. Fleetshift can also be used to ship code adjustments as “recommendations” — for instance, groups have used Fleetshift to suggest higher storage courses for Google Cloud Storage buckets or to rightsize pods working in Kubernetes to make use of much less CPU or reminiscence assets. We’ve discovered that making a “recommendation” by presenting a staff with a pull request considerably lowers the barrier to having the staff act on that advice — all of the proudly owning staff has to do is evaluate the diff and press the merge button.
Testing fleet-wide refactorings earlier than sending a pull request
Fleetshift has a “preview” mode for authors who’re iterating on their preliminary model of their fleet-wide change, the place prior to truly sending a pull request to anybody, the writer can look at the diff and logs of their code transformation towards the entire repos it can goal.
We rapidly discovered, although, that it isn’t sufficient to have the ability to see what code your refactoring will really change as soon as it runs. Authors additionally need to know if the exams of all of the impacted repos will proceed to go, earlier than really sending a pull request to anybody.
To fulfill this want, we constructed one other device, Fleetsweep (you would possibly discover a theme to the naming), that permits engineers to check their shift’s Docker picture towards a set of repos. A Fleetsweep job runs on the identical Kubernetes-backed infrastructure as Fleetshift, permitting it to scale to requests concentrating on numerous repos.
Instead of producing a pull request towards the unique repo, Fleetsweep creates a short-lived department within the repo containing the automated change. Fleetsweep then triggers a construct of that department in our CI system and studies the combination outcomes again to the change writer, permitting them to examine which repos would have failed exams inside that automated refactoring and to examine the construct logs of every repo as effectively, if wanted.
The existence of Fleetsweep permits engineers to check how effectively their change will work throughout the fleet earlier than submitting it to Fleetshift and creating pull requests (which might create noise for different engineers). For instance, it’s a widespread observe with our Java BOM for authors to run a Fleetsweep for a possible library improve if there may be any query of whether or not the brand new launch accommodates any backward incompatible adjustments.
Enabling gradual rollouts of some fleet-wide adjustments
As we’ve prolonged fleet-wide refactoring and automatic dependency administration to extra forms of parts, we’ve discovered that we can not all the time have a excessive quantity of confidence in pre-merge testing’s potential to catch issues for all sorts of adjustments. For instance, lots of our batch information pipelines are run on Google Dataflow, and whereas the take a look at suites of particular person parts are sometimes targeted on testing the enterprise logic of the information pipeline, it’s a lot more durable for every particular person pipeline to reliably take a look at the small print of what occurs when the pipeline runs within the cloud and the way the handfuls of runtime dependencies work together with one another.
Another problem with batch information pipeline parts specifically is that, in contrast to backend providers, code adjustments aren’t instantly run after being merged. The typical batch information pipeline is executed as soon as per hour or as soon as per day, dramatically growing the suggestions loop between when a code change is merged and when the outcomes of it may be noticed. Lastly, a “bad” code change won’t fail in a method that causes the element to crash or return errors — some dangerous adjustments would possibly lead to quiet corruption of knowledge.
To fight this whereas nonetheless embracing the necessity to make it simple for engineers to refactor and replace code throughout all parts directly, we’ve modified the Fleetshift system over time to help “gradual” rollouts. An writer can configure their shift in order that the goal repos are divided into quite a few cohorts; the change that the shift makes (e.g., improve the X library to model Y) is simply utilized to every cohort as soon as the change has been efficiently utilized to sufficient repos within the earlier cohort.
To decide when a cohort of repos is wholesome “enough” for a given model, Fleetshift consults the Firewatch system to seek out the utmost model for every cohort the place a specific amount of repos in prior cohorts have had a proportion of profitable deployments (or executions for batch information pipelines) larger than a configurable threshold.
The connection between Fleetshift and Firewatch creates a kind of suggestions loop within the automated system: the success (or failure) of an automatic change (similar to “update the foobar library to the latest release”) yesterday informs the choice to use or to not apply that very same replace to further repos at the moment.
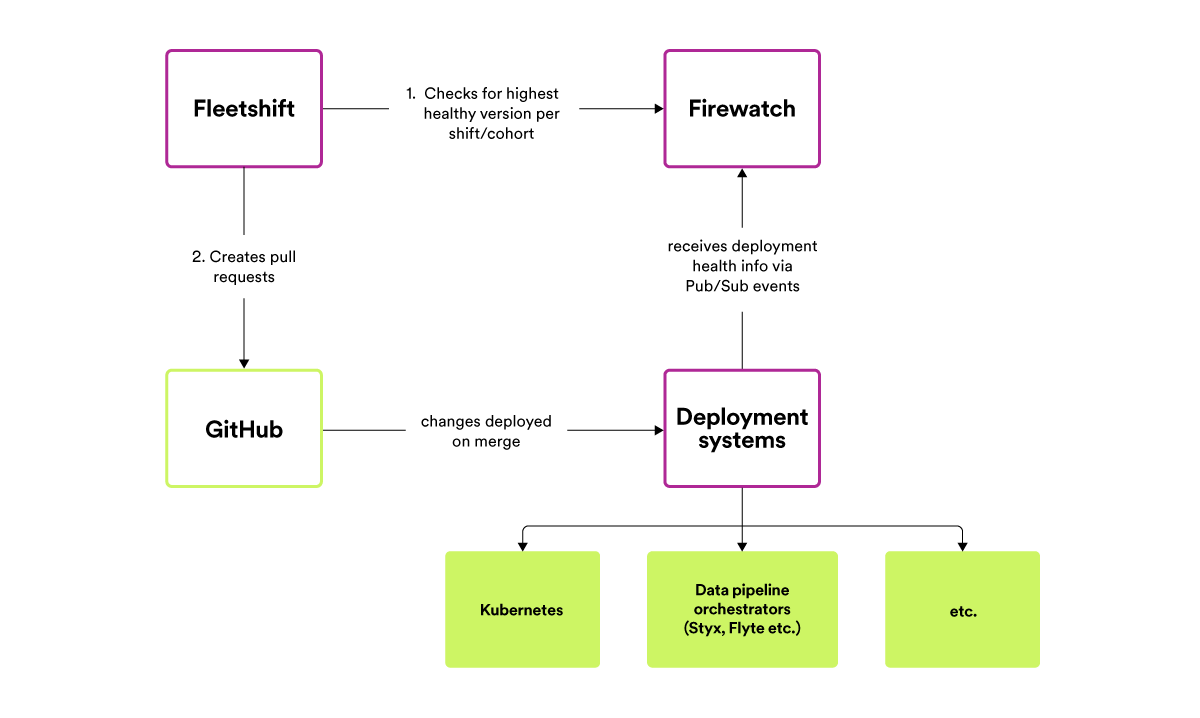
In the batch information pipeline instance talked about earlier, we divide the set of repos into cohorts primarily based on alerts, similar to how essential the information produced by the pipeline is (apply automated adjustments to the lower-value tiered parts earlier than higher-value tiers) and the way good the pre-merge exams and post-merge monitoring of the element is. As one other instance, the each day BOM replace shift divides backend repos in order that essentially the most essential system solely receives the brand new model as soon as it has been efficiently deployed in a majority of different backend parts.
Results
With the infrastructure and instruments outlined above, fleet-wide refactoring at Spotify has come a great distance prior to now two years. In 2022, Fleetshift created greater than 270,000 pull requests, with 77% of these PRs being automerged and 11% merged by a human (every of those stats is a 4–6x enhance from 2021). The 241,000 merged pull requests created by groups utilizing Fleetshift symbolize a complete of 4.2 million strains of code modified. In surveys, greater than 80% of engineers at Spotify stated that Fleet Management has positively affected the standard of their code.
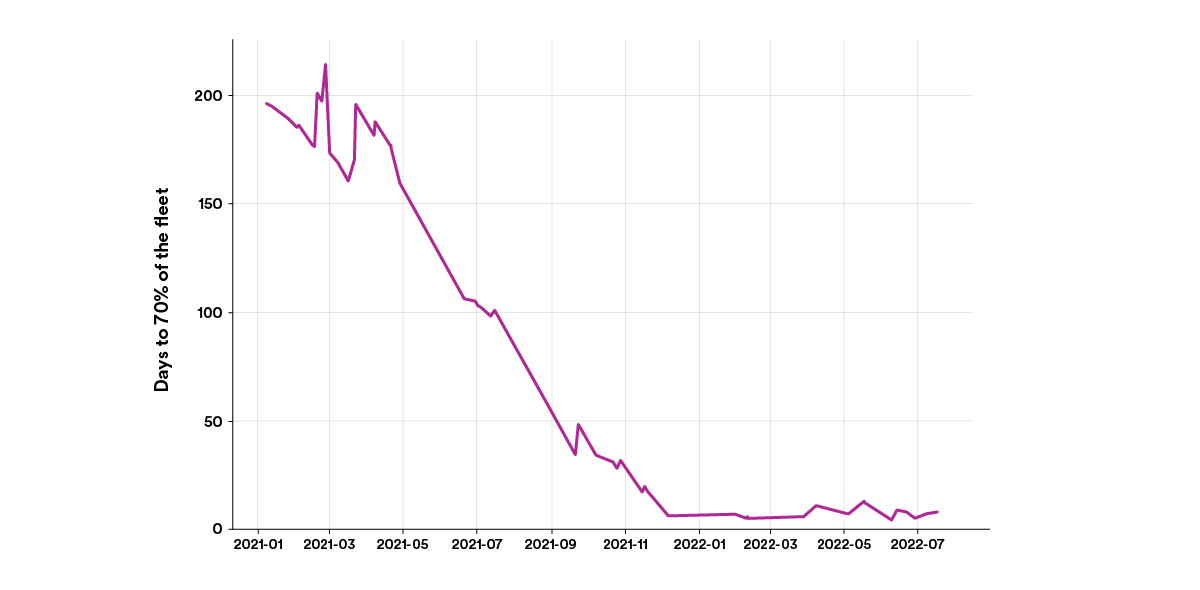
More importantly than the quantity of code modified or pull requests generated is the measurable impression that these instruments and new mindset have had on our potential to roll out adjustments throughout our fleet. As talked about within the first put up on this collection, the period of time taken for brand new releases of our inside backend service framework for use in 70+% of deployed providers has dropped from about 200 days to lower than 7 days, as proven within the graph beneath.
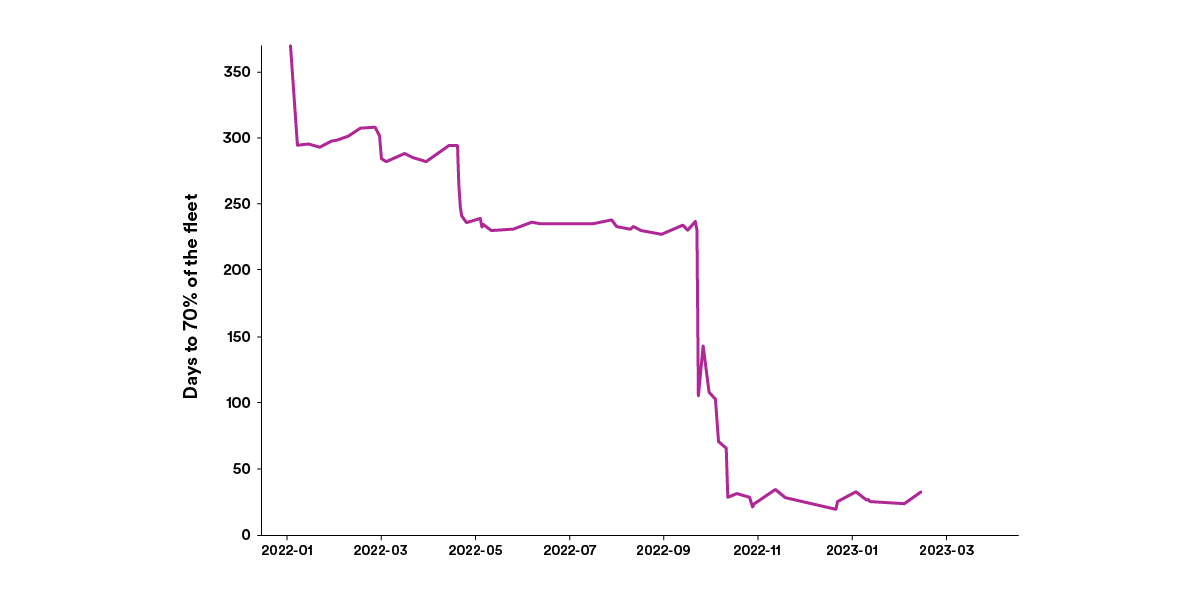
Similarly, the period of time taken for brand new releases of Scio and our inside SBT plugin managing dependencies in batch information pipelines has dropped from round 300 days to about 30 days, as you possibly can see beneath.
These examples are from two shifts of many — over the previous 12 months, 49 distinct groups have used Fleetshift to ship pull requests to different groups, with 27 groups sending PRs through Fleetshift over the previous 30 days alone. In this time interval, the median variety of repos focused by a shift is 46 repos and 22 shifts have modified code in a thousand or extra repos.
Establishing Fleetshift as our normal device for fleet-wide refactoring with a staff sustaining it full-time has been an essential a part of getting groups to embrace the fleet-first mindset. There is not a necessity for groups to ask what instruments they’ll use to alter code outdoors of their management, and we see that groups planning for brand new releases or breaking adjustments at the moment are actively planning for how you can roll out that change with Fleetshift.
While we’re happy with the progress to this point, we need to take fleet-wide refactoring so much additional sooner or later. We are all the time in search of methods to decrease the training curve for writing nontrivial code refactorings, to make it simpler for groups to get began with Fleetshift and to permit groups to be extra formidable with API deprecations and code migrations. There can also be so much we are able to do to make it simpler for shift authors to seek for the code that wants refactoring — writing SQL to question code saved in BigQuery tables just isn’t essentially the most simple process. Lastly, whereas we usually have many repos containing one or a number of parts every, a good portion of our codebase resides in monorepos, the place many groups are working in the identical repo (similar to our shopper/cell codebases) — a workflow that’s not adequately supported by Fleetshift at the moment.
This put up is the final in our collection on Fleet Management. We have many challenges remaining in our Fleet Management effort, so anticipate to listen to extra from us sooner or later. If you have an interest on this work or are constructing one thing comparable your self, we’d love to listen to from you – please get in contact.
Acknowledgments
The progress and instruments mentioned on this put up have been a results of laborious work from lots of people over the previous few years. Many due to Andy Beane, Brian Lim, Carolina Almirola, Charlie Rudenstål, Dana Yang, Daniel Norberg, Daynesh Mangal, Diana Ring, Gianluca Brindisi, Henry Stanley, Hongxin Liang, Ilias Chatzidrosos, Jack Edmonds, Jonatan Dahl, Matt Brown, Meera Srinivasan, Niklas Gustavsson, Orcun Berkem, Sanjana Seetharam, Tommy Ulfsparre, and Yavor Paunov.
Apache Maven is a trademark of the Apache Software Foundation.
Docker is a registered trademark of Docker, Inc.
Kubernetes is a registered trademark of the Linux Foundation within the United States and different international locations.
Google Cloud Bigtable and Dataflow are logos of Google LLC.
Tags: engineering management
[ad_2]