{kind=link}
[ad_1]
May 04, 2023 Published by Spotify Research
Allowing customers to find new entities resembling books, music, and films is a vital aim for on-line platforms. This may be achieved for instance by recommending entities that the person has not but interacted with. Another means customers can discover new entities is by exploring the catalog with the search system. However, the recognition of an entity has a robust affect on which entities are surfaced by the search system, particularly if a machine-learned mannequin for retrieval was skilled based mostly on person interactions. If only some entities are proven for almost all of the queries we are saying that the search system has a excessive retrievability bias.If this inequality is just too robust, various entities that may very well be related for various data wants won’t ever be surfaced.
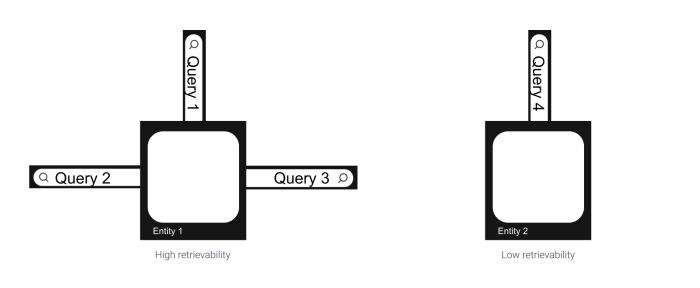
Besides the coaching information usually used to coach such fashions, one other issue that influences the retrievability of search techniques is the distribution of the queries’ intents. Most customers have a slim underlying intent and simply need to discover the precise entity they bear in mind. Users with broad intents alternatively have an exploratory mindset and are keen to find new entities when interacting with the search system. The quantity of broad intent queries is small in comparison with slim intent queries, which ends up in a whole lot of search interactions with standard entities.
In order to mitigate such issues, we suggest an method to generate artificial queries. For coping with the bias within the coaching information, we are able to generate queries for each entity within the catalog, and use that as coaching information for the retrieval mannequin. For coping with the distribution of slim and broad queries, we are able to generate broad question options as a way to affect person conduct.
Generating queries to mitigate retrievability bias
We introduce a mannequin that for a given entity and the specified intent (slim or broad), it generates an artificial question for the chosen intent: CtrlQGen. The proposed mannequin makes use of the metadata data accessible for the entity and learns generate queries based mostly on that. Our mannequin has three parts: (1) serialization, which turns entities right into a string illustration, (2) weak labeling, which generates coaching information with out entry to ground-truth information and (3) intent-aware technology, which learns generate queries controlling for the intent. CtrlQGen can leverage any encoder-decoder pre-trained language mannequin, e.g.T5, to implement element (3).
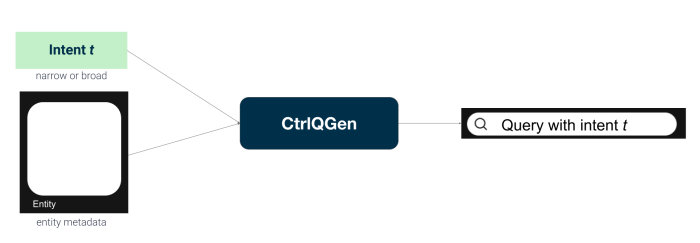
In our experiments, we check the 2 essential hypotheses relating to we mentioned within the introduction to cut back the retrievability bias:
- [H1] Training dense retrieval fashions with queries generated by CtrlQGen will result in much less retrievability bias in comparison with coaching with actual queries and their respective clicked entities.
- [H2] Suggesting broad queries utilizing CtrlQGen will result in much less retrievability bias in comparison with the present set of queries.
Results
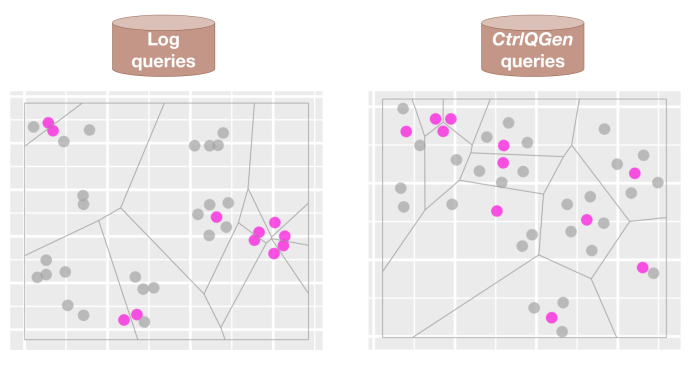
Our experimental outcomes on three totally different pattern datasets—of music tracks and podcast episodes from Spotify, and a public e-book dataset—present that certainly a transformer-based bi-encoder mannequin skilled on queries from the logs has the next retrievability bias than a mannequin skilled on artificial queries, which is constructive proof for [H1]. This is proven with an anecdotal instance under, the place we encode the representations of entities (pink coloration) and queries (gray coloration) discovered by the bi-encoder fashions right into a two-dimensional house. We see that the entities are higher distributed with the queries generated by our mannequin.
We additionally present in our experiments that making use of CtrlQGen for producing broad question options can cut back the retrievability bias of the system by as much as 9% p.c, displaying constructive proof for our second speculation [H2]. The framework for producing question options utilizing CtrlQGen is as follows: given the preliminary question issued by the person, for every entity within the ranked listing for this question we apply CtrlQGen to generate broad queries. This means if a person is trying to find one thing particular, we additionally recommend broader associated content material to discover through question options.
Some content material, e.g. tracks, podcasts, and so forth, is retrieved through many queries, whereas others get little to no publicity from search interactions. In this work, we present mitigate this retrievability bias with a question technology system that controls for the underlying intent of the question. We use the queries generated by the proposed CtrlQGen to both (I) prepare dense retrieval fashions or (II) as question options. We consider that bettering the capabilities of search techniques to advertise discoveries is a vital route of analysis for on-line media platforms.
For extra data, please consult with our paper:
Improving Content Retrievability in Search with Controllable Query Generation
Gustavo Penha, Enrico Palumbo, Maryam Aziz, Alice Wang, and Hugues Bouchard
TheWebConf 2023
[ad_2]