{kind=link}
[ad_1]
May 3, 2023

Check out Part 1 of our collection on Fleet Management at Spotify and the way we handle our software program at scale.
At Spotify, we adopted the declarative infrastructure paradigm to evolve our infrastructure platform’s configuration administration and management aircraft method, permitting us to handle tons of of 1000’s of cloud sources throughout tens of 1000’s of various companies at scale.
Our on-premise origins
A couple of years in the past, Spotify underwent a transition from being completely hosted in our personal on-premise information facilities to as an alternative working on the Google Cloud Platform (GCP). As a part of this transition, we employed a “lift and shift” mannequin, the place current companies, their structure, and the relationships with the underlying infrastructure had been largely preserved.
This meant that the actual infrastructure decisions builders made within the cloud different loads relying on the use case and group. As we realized extra about working in a cloud atmosphere, our greatest follow suggestions additionally advanced with our studying. For instance, whereas we had been working on premises, it was thought-about greatest follow to host your individual Apache Cassandra cluster, ship messages through Apache Kafka, run customized Elasticsearch or PostgreSQL situations, or set up Memcached on devoted VMs. The cloud gives managed equivalents for all of those — Google Cloud Bigtable and Cloud Pub/Sub, or working Memcached on high of Kubernetes, for instance. As a outcome, the infrastructure that had been created through the years began forming a protracted tail — snapshots in time of no matter was thought-about the very best follow of its day, together with the errors made alongside the best way.

The drawback was exacerbated with the continued development of the corporate. While our engineering groups grew at a considerably fixed charge, the quantity of software program being created and infrastructure being provisioned grew exponentially in comparison with the variety of builders. It grew to become more and more widespread for a group of builders to wish to personal dozens to tons of of codebases (in Spotify lingo, “components”), and thru acquisitions and reorgs, transfers of possession grew to become more and more widespread, the place the group proudly owning a codebase had misplaced the information concerning the architectural and infrastructural decisions that had led as much as its present design.
Sorely lacking was a mechanism for bringing current infrastructure as much as our newest and biggest requirements, in addition to for placing our fleet right into a state the place the fragmentation of infrastructure decisions could be low sufficient that our inner platform group may help the overall footprint of our infrastructure.
Our journey into the cloud
In the on-premise world, the place particular person machines had been often valuable pets, we relied on hostcentric configuration administration instruments like Puppet and, in some instances, Ansible. It was additionally extremely widespread for groups to host their very own infrastructure — some examples of that had been talked about above. However, this method wouldn’t maintain up in a cloud atmosphere, as a consequence of quite a lot of components:
- In a cloud atmosphere, we usually encourage utilizing cloud-managed alternate options to self-hosted infrastructure.
- A whole lot of configuration is neither service nor infrastructure useful resource particular. IAM configuration, community and firewall configuration, relationships between entities corresponding to subscriptions, backups, cross-region replication guidelines, and many others., don’t essentially map effectively to at least one explicit service, VM occasion, or related.
- There aren’t any long-running compute situations that may make use of the gradual and regular host-oriented reconciliation mannequin that Puppet or Ansible employs. A VM or Kubernetes Pod may get re- or descheduled at any cut-off date, and the lengthy bootstrapping course of for spinning up new situations of Puppet-managed VMs was thought-about unacceptable to help the shifting visitors patterns of the Spotify information facilities.
Hence, we had been in search of a brand new resolution that may give us management of all infrastructure at Spotify and permit us to depart from the host-oriented configuration administration of the previous. We nonetheless needed to retain the flexibility to use company-wide insurance policies, information customers to greatest practices, and many others., so we seemed for an answer to align on as an organization. Quite a few constraints shortly emerged:
- We wanted to help a GitOps workflow, the place infrastructure configuration is checked in with supply code, could be peer-reviewed, and gives an audit path.
- In order to grasp the fleet of infrastructure — i.e., all of the infrastructure sources on the market — we would have liked to discover a resolution that may help runtime introspection, the place we may, for instance, enumerate all of the databases that exist on the firm, determine those which may violate a sure coverage, determine the proudly owning group, and many others. In some instances, a break-glass course of may even be needed, the place an SRE group may go in and alter the configuration for an infrastructure useful resource instantly, bypassing a GitOps workflow.
- In order to have the ability to apply automated adjustments to our infrastructure, the configuration wanted to be information (e.g., JSON/YAML) slightly than code (e.g., Starlark, HCL, TypeScript, and many others., common decisions for infrastructure configuration). It may be very onerous (i.e., Halting Problem onerous) to vary code in order that evaluating it ends in the specified infrastructure output however altering configuration-that-is-data is trivial.
The resolution we recognized additionally had to have the ability to be a vacation spot for all the current infrastructure at Spotify. We didn’t begin from a clean slate; slightly, Spotify had many tons of of 1000’s of cloud sources earlier than we went on this journey. Hence, no matter resolution we picked would wish to help some type of “import” workflow, the place current infrastructure might be encoded through configuration information whereas not affecting the present state of the infrastructure sources in any method.
We believed {that a} first rate start line could be to easily mannequin uncooked cloud sources however that this is able to result in an enormous configuration footprint in the long term. Instead, we noticed this as a stepping stone to introducing bespoke customized sources, permitting us to encapsulate and bundle/compose lower-level sources and finally do away with all uncooked cloud useful resource declarations.
Commonly used options wouldn’t meet all the necessities set above; for instance, Terraform wouldn’t meet necessities 2 and three.
The resolution we determined to guess on was to make use of Kubernetes for modeling infrastructure sources, which ended up assembly all the necessities set above. We referred to as the ensuing product merely “declarative infrastructure.”
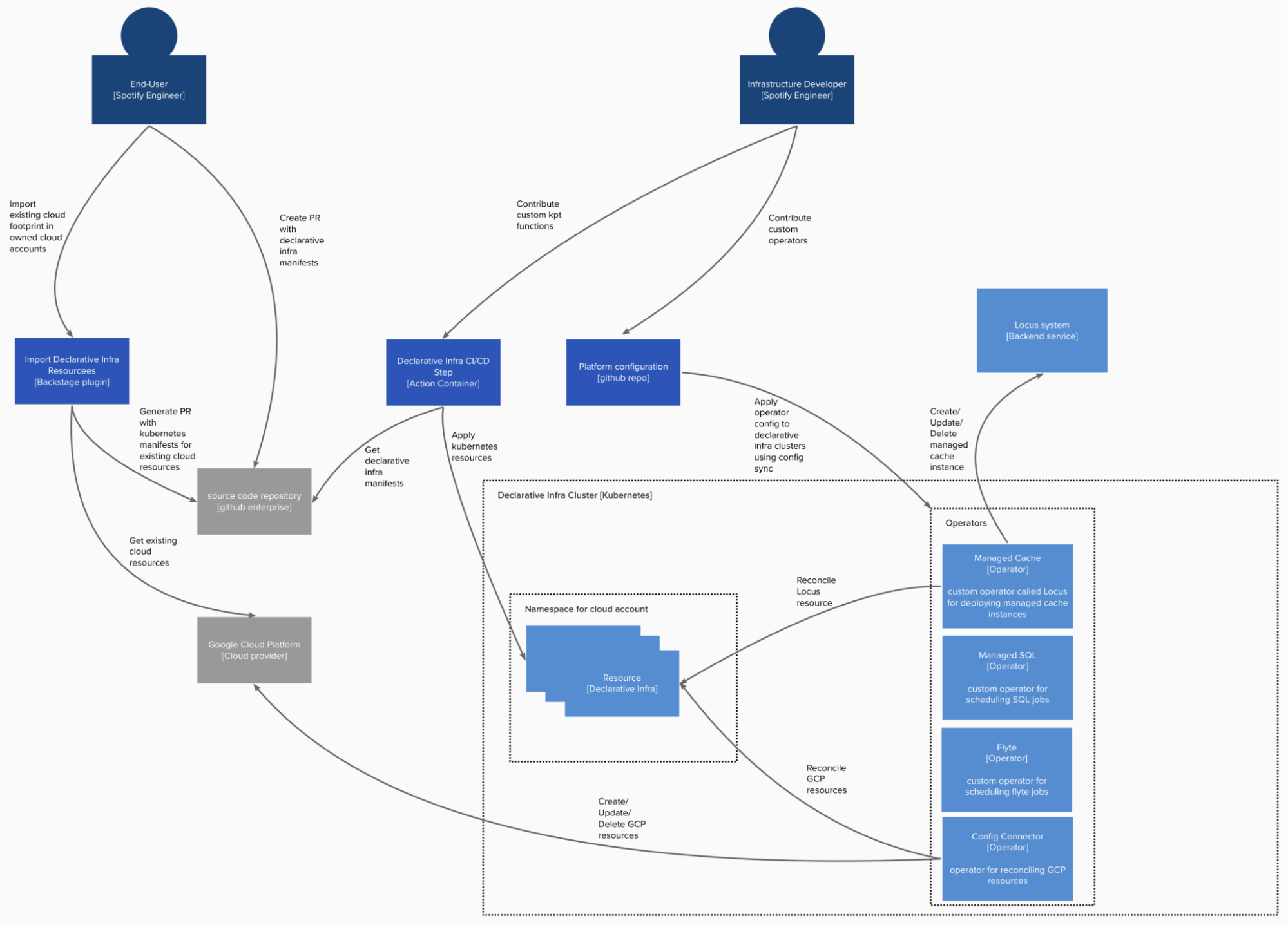
Implementing declarative infrastructure utilizing Kubernetes
We utilized help for declarative infrastructure sources in Kubernetes by leveraging customized sources. Each form of infrastructure useful resource, whether or not or not it’s a uncooked cloud primitive or bespoke customized useful resource, is modeled with a customized useful resource definition (CRD). The sources are frequently reconciled by operators, which try and deliver the state of the world (GCP;our managed cache system, Locus, which declaratively deploys a Memcached occasion; the Flyte system, amongst others) in step with the infrastructure declarations.
We opted to run the declarative infrastructure platform on devoted Kubernetes clusters. This was primarily to cut back the danger of impacting different Spotify companies working on the principle workload clusters. The declarative infrastructure operators could be pretty demanding on the API server, in distinction to workloads for Spotify stateless companies, which are typically demanding on the employee nodes. The platform at the moment has 3,000-plus GCP tasks and roughly 50K GCP sources.
Kubernetes manifests are sometimes ingested from supply code repositories into the Kubernetes cluster via the CI/CD course of, the place one of many steps within the construct course of is the declarative infrastructure step, which is a Docker picture that performs some mild transformations and validation on the manifests utilizing kpt after which applies them to the related Kubernetes cluster.
For simplicity and isolation, a devoted service account is used per supply code repository within the CI/CD system. Additionally, a Kubernetes namespace is created per GCP challenge (a one-to-one relationship). This allows us to restrict entry for repositories solely to handle sources in GCP tasks explicitly granted entry.
Users create the Kubernetes useful resource manifests of their supply code repo via numerous mechanisms:
- Existing cloud sources are imported with the import Backstage plugin, which queries sources from the related cloud account and generates a pull request with the corresponding manifests utilizing Config Connector. With Spotify’s massive current Google Cloud footprint, this facilitates quick adoption of the declarative infrastructure platform.
- A Backstage plugin generates an acceptable infrastructure manifest with present greatest follow, based mostly on solutions to some questions.
- An IDE plugin with autocomplete makes crafting the YAML for the manifests simpler.
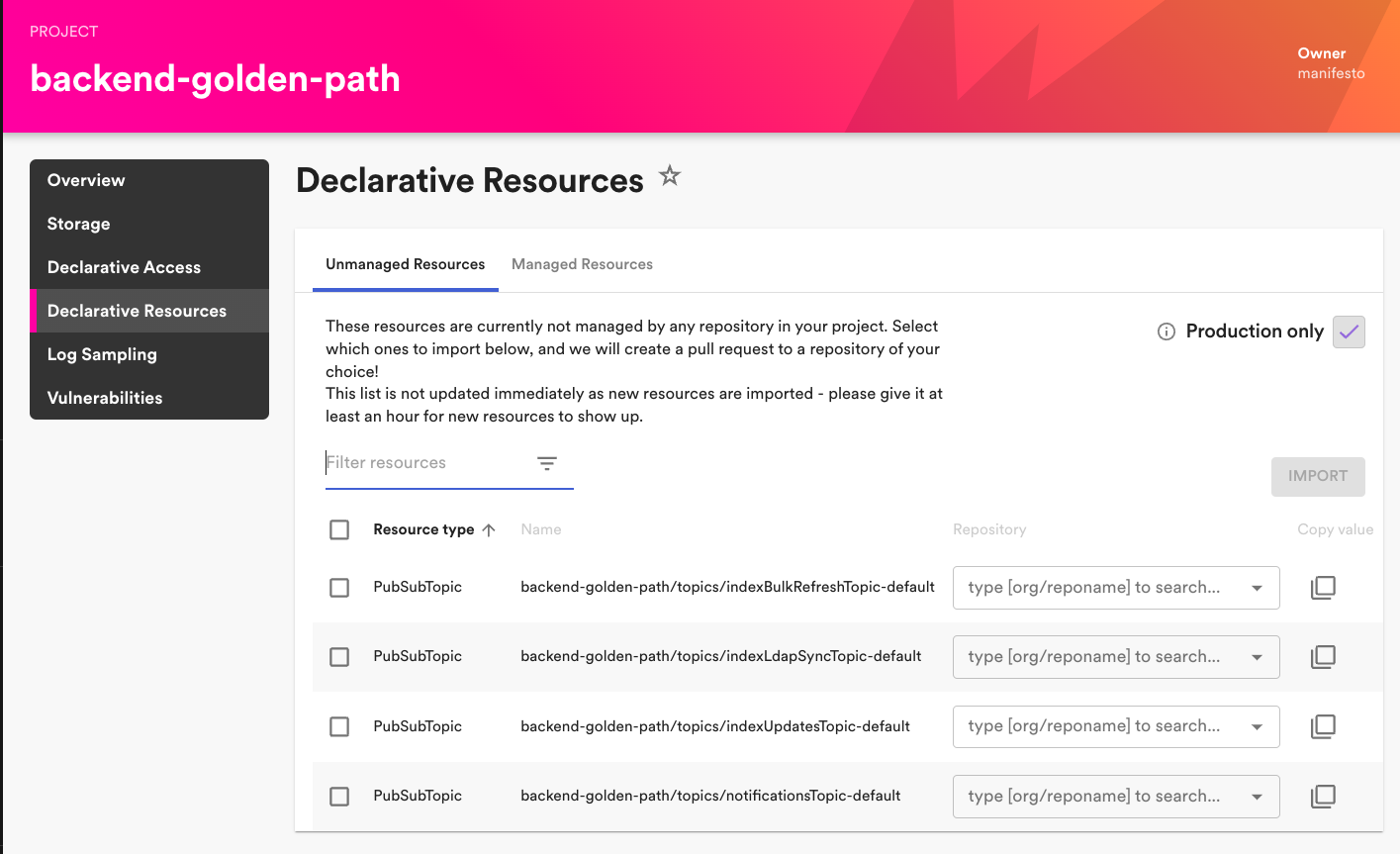
During the construct, the manifests are utilized, after which the declarative infrastructure construct step waits for the Kubernetes sources to be reconciled (for instance, waits for a managed cache occasion to be created) and surfaces any suggestions to the consumer on the success or failure of this operation within the construct logs and pull request.
Review builds additionally carry out mild validation and a dry run towards the cluster and floor suggestions to the consumer, on which sources will probably be added/up to date/eliminated.
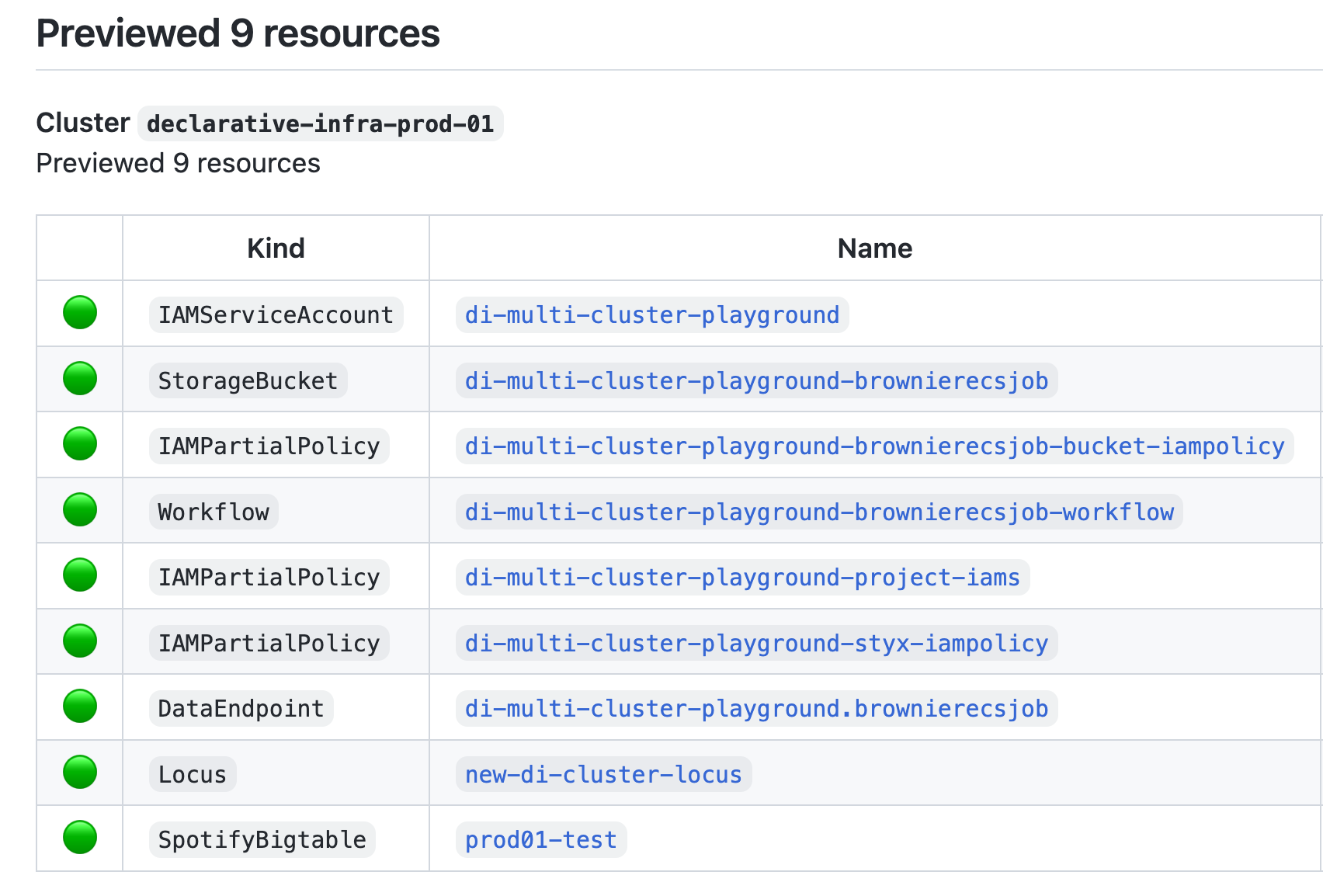
Kubernetes operators react to all adjustments of the sources, dealing with creating, updating, and deleting the infrastructure being managed by a useful resource when the Kubernetes useful resource is deleted.
To keep away from any unintentional adjustments and to have the ability to scale our tooling to the entire group, no matter expertise stage or competence, we determined to restrict the default permissions for customers via RBAC to solely get sources, and added a break-glass mechanism for updates and deletes. The break-glass mechanism additionally allows groups to make emergency adjustments while not having to attend for the total code overview/construct course of. A break-glass account is created per namespace, and the proudly owning group has entry to impersonate.
One of the principle advantages in managing declarative infrastructure on Kubernetes is the extensibility that this permits. Infrastructure builders contribute to the platform by constructing customized operators. This allows highly effective, high-level abstractions for infrastructure wants, corresponding to managed databases, managed caches, information jobs, and different use instances. We at the moment have roughly 20 internally constructed operators.
Here is an instance useful resource for a managed cache occasion. Runtime insights could be gathered by inspecting the standing for the declarative infrastructure useful resource.
apiVersion: caching.spotify.com/v1alpha2
sort: Locus
metadata:
identify: my-locus-instance
namespace: my-gcp-project
spec:
numShards: 6
podSpec:
cpu: 10
memorySizeGb: 16
areas:
- europe-west1
- us-central1
- asia-east1
- us-east1
- europe-west4
standing:
circumstances:
- lastTransitionTime: "2023-03-17T15:13:46.690585664Z"
message: this useful resource is updated
observedGeneration: 1
purpose: UpToDate
standing: "True"
sort: Ready
observedGeneration: 1
prepared: "True"Another instance is the info endpoint useful resource (used to outline a dataset), which may in flip create and handle the lifecycle of the underlying cloud storage useful resource. On one other group that creates Flyte tasks via CRDs, the operator additionally creates Google service accounts, attaches position bindings to them, and fixes the workload identification for a number of namespaces. This form of interplay, with a number of sources, takes away loads of complexity that may occur in scripts and allows a brand new set of automation on the platform facet.
The declarative infrastructure platform may also be prolonged by infrastructure builders implementing kpt capabilities or including gatekeeper validating/mutating webhook configurations. The benefit of gatekeeper over kpt is that this logic will probably be utilized no matter how sources are utilized to the cluster. Kpt capabilities solely run client-side within the declarative infrastructure motion container and might simply be bypassed.
Looking into the long run
We are excited to proceed so as to add options to the platform.
For finish customers, we wish to enhance the developer expertise such that:
- It is simple to create cloud sources with out having to craft YAML declarations or depend on importing current cloud sources.
- A tighter integration with Backstage makes it doable to view the runtime state of sources with out having to manually question the cluster.
For infrastructure builders, we’ll work on bettering the operator dev expertise for different infrastructure groups to construct on high of the platform.
Acknowledgments
Building this platform was a group effort. Many due to the Manifesto squad, the Core Infra R&D studio, and contributors from different components of the group.
Apache Cassandra and Apache Kafka are both registered logos or logos of The Apache Software Foundation within the United States and different nations.
Postgres, PostgreSQL and the Slonik Logo are logos or registered logos of the PostgreSQL Community Association of Canada, and used with their permission.
Elasticsearch is a trademark of Elasticsearch B.V., registered within the U.S. and in different nations.
Google Cloud Bigtable is a trademark of Google LLC.
KUBERNETES is a registered trademark of the Linux Foundation within the United States and different nations, and is used pursuant to a license from the Linux Foundation.
[ad_2]