{kind=link}
[ad_1]
April 20, 2023 Published by Thanos Vlontzos, Ciarán Gilligan-Lee

Introduction
Answering causal questions with machine studying algorithms is a difficult but important activity. While it’s simple to identify correlation, unravelling causation necessitates cautious examination of confounding variables and experimental design.
At Spotify, figuring out the causal influence of recommending a selected kind of content material on a person will be difficult on account of potential omitted variable bias. For occasion, a person might love music, which suggests they spend extra time utilizing Spotify than others. This will increase the chance they’ll see a sure suggestion, but in addition will increase the chance they’ll frequently have interaction with Spotify regardless. Answering this query correctly requires superior statistical strategies and an intensive understanding of the underlying causal mechanisms to find out the true impact of our suggestions. And that’s not all. We are additionally on a quest to find what it actually means to be a fan. We are digging deep into the potential causes of fandom and analysing the causal impact of a person’s actions. Our mission at Spotify is to know the complicated relationship between our suggestions and person engagement.
While within the above examples, the therapy in query was binary—recommending particular content material or not—given the massive quantity of music, podcasts and audiobook content material we’ve got entry to, we have to transfer past simply quantifying the influence of binary therapies.
In this work, we take a step ahead, leaving the well-researched binary therapy and end result eventualities to delve into the world of categorical variables. We suggest and consider a brand new paradigm in answering counterfactual queries utilizing deep neural networks. Our methodology is evaluated in a variety of publicly out there datasets from Epidemiology, Medicine, and explainability in Finance—showcasing the true world applicability of our work.
Interventions vs Counterfactuals
While current machine studying advances have enabled sure causal inquiries to be answered in high-dimensional datasets, most of those strategies deal with Interventions, which solely represent the second degree of Pearl’s three-level causal hierarchy. Judea Pearl’s ladder of causality explains that interventions are at a better degree of causality than observations or associations, and so they allow us to check the consequences of actions. At the highest of the hierarchy sit Counterfactuals. These subsume interventions and permit one to assign absolutely causal explanations to knowledge. Counterfactuals examine various outcomes, by asking what would have occurred had a few of the preliminary circumstances been completely different. The essential distinction between counterfactuals and interventions is that the proof the counterfactual is “counter-to” can include the variables we want to intervene on or predict.
One express instance of a counterfactual query is the next: “Given that an artist released a specific track and it was streamed a certain amount, what would have happened had they released a different track?” Here we are able to use the remark of how nicely the unique monitor was acquired to replace our data about how engaged that viewers is, and use that data to raised predict the influence of an alternate monitor. A corresponding interventional question can be “what is the impact of releasing a single on the growth of my audience?”. Here, the proof that the viewers has grown is just not utilized in estimating the influence. By utilising this extra data, counterfactuals allow extra nuanced and personalised reasoning and resolution making.
Non-Identifiability
Picture this: you’ve got a strong machine studying mannequin that may predict the consequences of interventions and information your resolution making, you’re fairly excited to see it in motion. But wait, is it at all times dependable? Unfortunately, the reply is just not at all times clear-cut. The downside lies within the non-identifiability of counterfactuals, which implies that even when your mannequin is skilled on observations and interventions, its predictions can typically conflict with area data. This could be a main roadblock, as we would like our fashions to precisely replicate actuality. As the fashions agree on the information they’re skilled on, we should impose additional constraints to study the mannequin that generates domain-trustworthy counterfactuals.
Let us take a look at an illustrative instance from the sphere of epidemiology, formalised by the next Directed Acyclic Graph (DAG) and accompanying equations, under. In the context of epidemiology, X is the presence of a threat issue and Y is the presence of a illness. From epidemiological area data, it’s believed that threat components at all times enhance the chance {that a} illness is current—known as “no-prevention”, that no particular person within the inhabitants will be helped by publicity to the danger issue. Hence, if one observes a illness, however not the danger issue, then, in that context, if we had intervened to present that particular person the danger issue, the chance of them not having the illness should be zero—as having the danger issue can solely enhance the chance of a illness
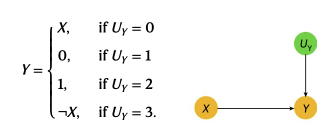
Under this regime, two potential likelihood distributions for the latent variable U_y are
P(UY=0) = 1/2, P(UY=1) = 1/6, P(UY=2) 1/6, and P(UY=3) = 1/6
and
P(UY=0) = 1/3, P(UY=1) = 1/3, P(UY=2) 1/3, and P(UY=3) = 0.
These two distributions may give the identical observations and interventions however differ on their counterfactual estimations. By definition counterfactuals usually are not observable so we can not know a priori which one is the proper reply. However, the primary instance clashes with the epidemiology area data talked about above, as we define in our paper.
This is the place identifiability comes into the image. Identifiability constraints supply theoretical ensures that within the conditions the place they’re fulfilled the reply to counterfactual questions are identifiable and distinctive from observational knowledge. In our instance that X and Y are binary variables it is sufficient to implement a monotonicity constraint as this completely captures the epidemiological area data. The mannequin that satisfies the constraint is the one with likelihood distribution:
P(UY=0) = 1/3, P(UY=1) = 1/3, P(UY=2) 1/3, and P(UY=3) = 0.
Counterfactual Ordering
But what occurs when we’ve got a number of classes of therapy and outcomes? In these circumstances we are able to solely supply a partial identifiability constraint. In different phrases, solely within the circumstances the place our derived constraint is happy can we remove counterfactuals that disagree with our area data and instinct however can not uniquely determine the reply. Despite this shortcoming we present in follow that this constraint can remove sufficient non-intuitive solutions to make sensible purposes have good efficiency.
We title our partial-identifiability constraint Counterfactual Ordering and it encodes the next instinct: If intervention X solely will increase the chance of end result Y relative to every other intervention, with out rising the chance of one other end result, then intervention X should enhance the chance that the result we observe is a minimum of as excessive as Y, whatever the context.
From an engineering perspective, Counterfactual Ordering implies a set of constraints on the causal mannequin. In our paper we show that these are in actual fact equal to monotonicity, which will be enforced throughout causal mannequin coaching to make sure the discovered mannequin satisfies counterfactual ordering.
Deep Twin Networks
Having derived a constraint that will allow partial-identification of our counterfactual queries from observational knowledge we’re left with the duty to study a mannequin that follows mentioned constraints and produces dependable outcomes from real-world knowledge. For this we introduce deep twin networks.
These are deep neural networks that, when skilled, are able to twin community counterfactual inference—an alternative choice to the kidnapping, motion, & prediction methodology of counterfactual inference. Twin networks have been launched by Balke and Pearl in 1994 and scale back estimating counterfactuals to performing Bayesian inference on a bigger causal mannequin, often known as a twin community, the place the factual and counterfactual worlds are collectively graphically represented. Despite their potential significance, twin networks haven’t been extensively investigated from a machine studying perspective. We present that the graphical nature of dual networks makes them significantly amenable to deep studying.
So, how do they work? First, deep twin networks correspond to neural networks whose structure corresponds to the graphical construction of the dual community illustration of the structural causal mannequin to be discovered.Our strategy has two phases: first, we practice the neural community to study the counterfactually ordered causal mechanisms that finest match the information. Then we interpret it as a twin community on which commonplace inference will be carried out to estimate counterfactual distributions. This course of is graphically depicted under.
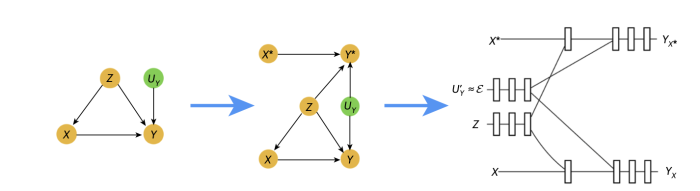
With the flexibleness and computational benefits offered by neural networks, our mannequin can deal with an arbitrary quantity and kind of confounders whereas estimating counterfactual chances. Moreover, twin networks have been designed to deal with the massive computational sources required for abduction-action-prediction counterfactual inference. As such, deep twin networks are quicker and fewer reminiscence intensive than commonplace abduction-action-prediction, and the inference will be carried out in parallel somewhat than in a serial nature.
Conclusion
Discovering and understanding causal relationships is a elementary problem in science and machine studying. In this work, we launched an modern strategy to study causal mechanisms and carry out counterfactual inference utilizing deep twin networks. We demonstrated that their strategy achieves correct counterfactual estimation that aligns with area data by way of empirical testing on actual and semisynthetic knowledge.
For extra about our findings, please discuss with our paper:
Estimating categorical counterfactuals through deep twin networks
Athanasios Vlontzos, Bernhard Kainz & Ciarán M. Gilligan-Lee
Nature Machine Intelligence, 2023
[ad_2]