{kind=link}
[ad_1]
April 18, 2023

TL;DR Instead of performing 10 main software program upgrades to our infrastructure yearly, what if we did 10,000 small ones? Across our whole codebase? That’s the concept behind Fleet Management: by constructing automation instruments that may safely make adjustments to hundreds of repos without delay, we are able to preserve the well being of our tech infrastructure constantly (as an alternative of slowly and laboriously). More importantly, eradicating this low-level work from our builders’ to-do lists permits product groups to give attention to fixing issues far more fascinating than migrating from Java 17.0.4 to 17.0.5. A more healthy, safer codebase, plus happier, extra productive engineers. What’s to not like? In this primary publish about Fleet Management at Spotify, we describe what it means to undertake a fleet-first mindset — and the advantages we’ve seen to date.
The downside of sustaining velocity at scale
Since delivery the very first app, Spotify has skilled practically fixed progress, be that within the variety of customers we serve, the scale and breadth of our catalog (first music, then podcasts, now audiobooks), or the variety of groups engaged on our codebase. It’s essential that our structure helps innovation and experimentation each at a big scale and a quick tempo.
Many small squads, many extra elements
We’ve discovered it highly effective to divide our software program into many small elements that every of our groups can totally design, construct, and function. Teams personal their very own elements and might independently develop and deploy them as they see match. This is a reasonably common microservice structure (though our structure predates the time period), utilized to all varieties of elements, be these cellular options, information pipelines, providers, web sites, and so forth. As we’ve scaled up and expanded our enterprise, the variety of distinct elements we run in manufacturing has grown and is now on the order of hundreds.

The small stuff provides up shortly
Maintaining hundreds of elements, even for minor updates, shortly will get arduous. More advanced migrations — e.g., upgrading from Python 2 to three or increasing the cloud areas we’re in — take vital engineering funding from a whole bunch of groups over months and even years. Similarly, pressing safety or reliability fixes would flip into intense coordination efforts to ensure we might patch our manufacturing surroundings in a well timed vogue.
The graph beneath exhibits the development of a typical migration, on this case upgrading our Java runtime, pre–Fleet Management at Spotify. All in all, this single migration took eight months, about 2,000 semiautomated pull requests, and a major quantity of engineering work.
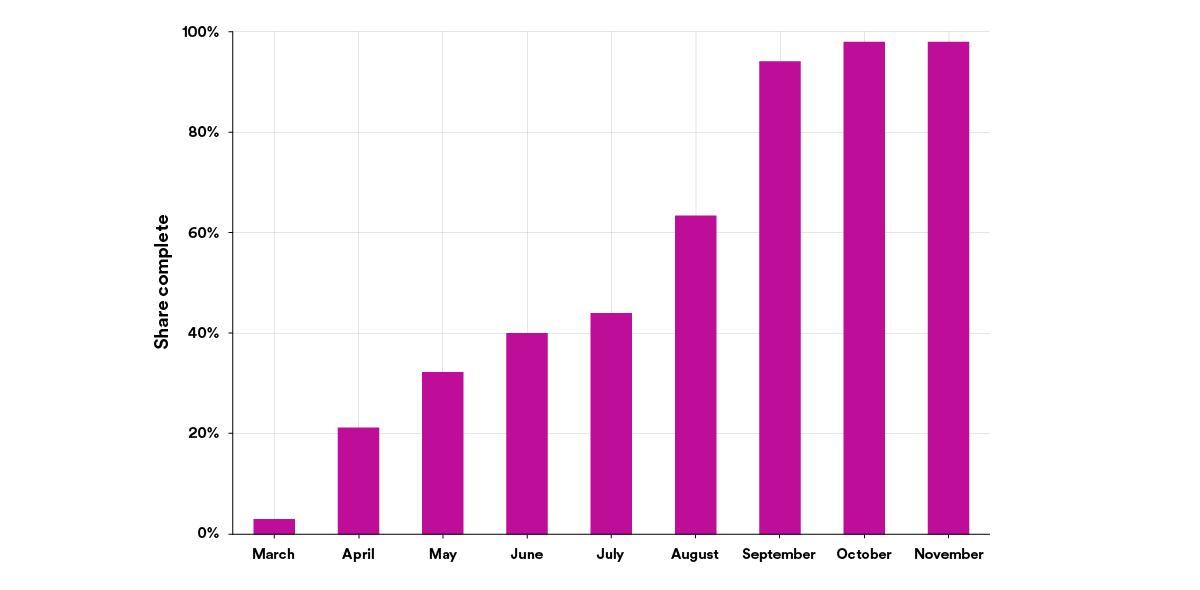
In addition to the toll this takes on a developer’s time, it additionally takes its toll on developer expertise: the sort of upkeep is boring and repetitive toil. It’s precisely the kind of work you need to automate.
Time to shift our pondering from squad first to fleet first
All in all, these insights led us to pursue a change in how we take into consideration our software program and to contemplate how we may apply adjustments throughout our whole fleet of elements, relatively than one after the other. We name this fleet-first pondering, and the practices and infrastructure to help it Fleet Management.
While we’ll principally cowl the technical elements of this work on this publish, it’s price noting that altering to a fleet-first mind-set additionally features a large shift in our engineering tradition and within the obligations of our infrastructure groups. It implies that making a change or fixing an issue is not only on your staff, however throughout all of Spotify’s code. Conversely, because the proprietor and operator of a part, you now obtain adjustments to your elements the place you aren’t within the loop earlier than the adjustments are merged and deployed.
How we apply fleet-first pondering to Spotify’s infrastructure
Let’s think about what’s required with a view to safely make adjustments throughout a fleet of hundreds of elements and round 60 million strains of code. (In complete, we now have >1 billion strains of code in supply management, with about 60 million being thought of manufacturing elements and thus in scope for Fleet Management.) Here are the 4 large questions we have to reply:
1. What code are we altering?
First, we’d like methods to establish the place adjustments should be utilized. Luckily, this was principally obtainable already. We have fundamental code search, and all our code and configuration is ingested into Google’s BigQuery, permitting for fine-grained and versatile querying. Similarly, our manufacturing infrastructure is instrumented and equally ingested into BigQuery, permitting us to question for library dependencies, deployments, containers, safety vulnerabilities, and lots of different elements. This may be very highly effective and helpful for exact concentrating on of adjustments. We are at the moment exploring semantic indexing of our code to allow much more fine-grained concentrating on — e.g., figuring out API name websites throughout your entire codebase.
2. Is every little thing we’re altering underneath model management?
Next, we’d like to ensure every little thing we need to make adjustments to is underneath model management, in our case, in Git. It goes with out saying that this was already the case for our code and configuration, however a fair proportion of our cloud assets — issues like storage buckets, service accounts, and database cases — weren’t but in Git, as we had been midway by our migration (again) to a totally declarative infrastructure. That story is for an additional day, however for the needs of this publish, simply know we would have liked to complete up this work.
3. How will we truly make the adjustments?
After that, we’d like a mechanism to creator, apply, and roll out adjustments in a secure means. In quick, this mechanism should have the ability to establish the place to use a change (e.g., match a specific piece of code in a repository), apply it to the repository (e.g., automated code refactoring), and confirm that it really works (e.g., by a CI construct). Lastly, the mechanism has to orchestrate how these adjustments are merged and deployed and to watch to make sure we are able to safely abort in case of failures throughout construct or deployment time.
It’s price noting that automated code refactoring at this scale shortly will get sophisticated. Hyrum’s regulation states that “with a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.” We have discovered this to be a really apt statement and definitely true for us as properly.
Spotify at the moment makes use of a polyrepo structure with hundreds of GitHub repos — though we now have good causes to consider that the identical set of practices and instruments outlined right here will probably be relevant ought to we transfer to a monorepo sooner or later. Either means, upon getting very massive codebases, the sort of specialised tooling is important to securely and effectively make fleet-wide adjustments — see, for instance, Google’s paper on C++ refactoring. We’re already seeing this for our largest repositories, at the moment with round 1 million strains of code.
4. How can we enhance belief in adjustments no one evaluations?
Lastly, we wish to have the ability to full a fleet-wide change inside hours or a number of days, and with out asking a considerable amount of our builders to do the work. This requires that adjustments could be routinely verified, merged, and deployed — with out a human within the loop.
While we typically have high-quality check automation, we would have liked to enhance check protection for some elements, and in some circumstances, add container-based integration testing. Also, many elements didn’t have automated canary-based testing throughout deployment. We rely closely on our check automation, and the overwhelming majority of our elements don’t use any kind of handbook testing or staging surroundings. Exceptions are sometimes people who have to be verified finish to finish with one in every of our companions or which have further compliance necessities.
To achieve additional confidence that we may at all times deploy from the principle department in Git, we additionally applied an everyday rebuild and redeployment of all elements. This ensures that each part will get rebuilt and redeployed not less than as soon as per week, lowering the chance of construct or deployment failures as a consequence of code rot.
Results: The proof is within the repos
We’re now at a stage the place we fleet-manage >80% of our manufacturing elements, specifically our information pipelines and backend providers. We have accomplished >100 automated migrations over the past three years and routinely replace exterior and inside library dependencies for elements each day. Our automation has authored and merged >300,000 adjustments, including roughly 7,500 per week, with 75% being automerged.
Happier, extra productive builders
We estimate we now have diminished developer toil, liberating up an order of magnitude of a whole bunch of developer years for extra enjoyable and productive work. We additionally see this within the sentiment evaluation, the place greater than 95% of Spotify builders consider Fleet Management has improved the standard of their software program.
A safer codebase
Our fleet of elements is now additionally in a more healthy state than earlier than. For instance, elements are updated with the inner and exterior libraries and frameworks they use. This has considerably diminished the variety of identified safety vulnerabilities deployed within the fleet and the variety of reliability incidents as we constantly make sure that each part is updated with bug fixes and enhancements.
As an instance, we had been capable of deploy a repair to the notorious Log4j vulnerability to 80% of our manufacturing backend providers inside 9 hours. (It then took a number of days to finish the rollout to our, on the time, unmanaged providers.)

New options, quicker
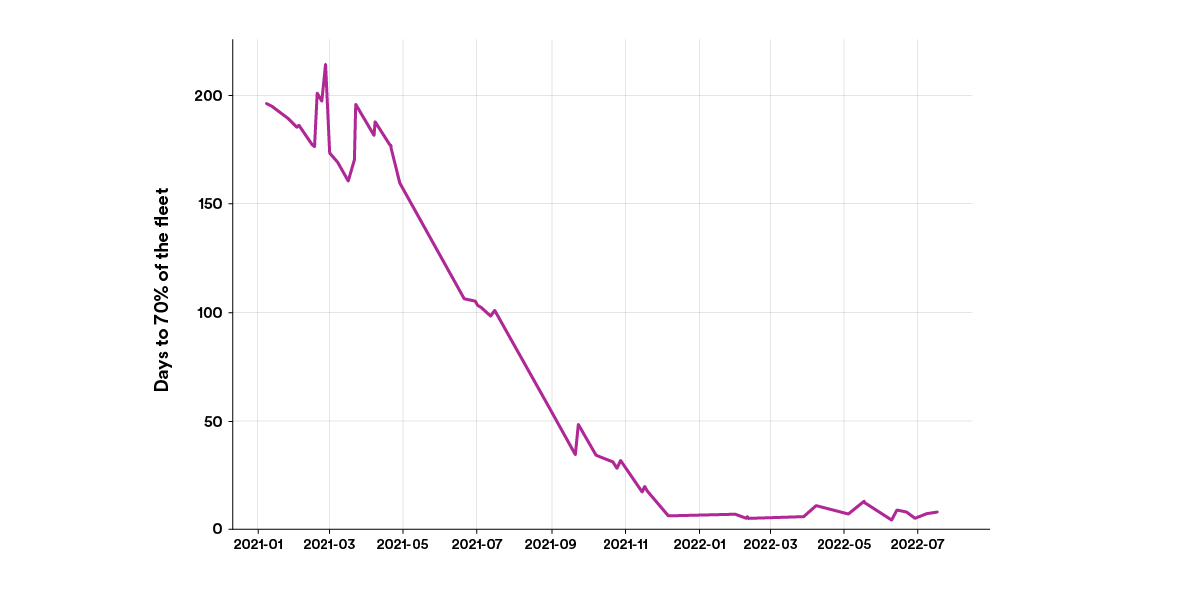
Similarly, this additionally implies that we are able to make new options and enhancements in our inside frameworks obtainable to our builders extra shortly than ever earlier than. For instance, a brand new model of our inside service framework used to take round 200 days to succeed in 70% of our backend providers by natural updates (see the graph beneath). Now that quantity is <7 days, which means that for those who work on our inside infrastructure platforms, you possibly can iterate and ship new options a lot quicker.
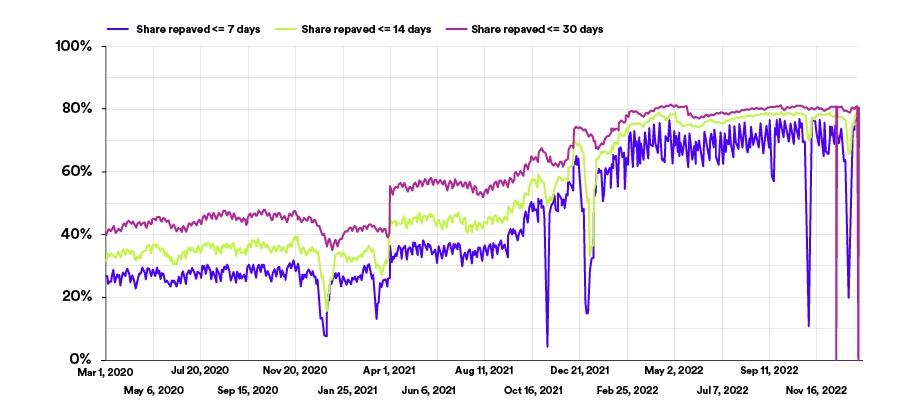
Stepping up our repaving sport
Lastly, >75% of our manufacturing surroundings is repaved (rebuilt and redeployed from supply code) weekly, lowering the chance of persistent construct/deployment failures, mitigating safety vulnerabilities, and guaranteeing elements are updated with Git.
The way forward for Fleet Management at Spotify
While we’ve made good progress to date, we now have numerous enhancements to make and challenges remaining.
Continuing adoption
We are step by step onboarding the remaining lengthy tail of elements onto Fleet Management. These are sometimes elements that aren’t constructed utilizing our expertise requirements and thus require extra growth work earlier than they are often totally managed, in addition to further part sorts. As talked about above, fleet first can also be a significant change in our infrastructure groups’ obligations. We will proceed onboarding groups to be fleet first and to routinely and safely roll out their adjustments to the fleet, till that is the default for all groups.
More advanced adjustments
We additionally need to have the ability to tackle more and more advanced fleet-wide adjustments. We’re now skilled in managing library and container dependencies and in making easier configuration and code refactoring adjustments. Next, we need to step by step enhance the complexity of the adjustments we’re assured in rolling out, specifically with the automated merging and deployment described above.
Increased standardization
One issue that extremely influences the complexity of constructing fleet-wide adjustments is how comparable elements within the fleet are. If they use the identical frameworks and comparable code patterns, making adjustments to them at scale turns into considerably simpler. Thus, we need to restrict the fragmentation in our software program ecosystem by offering stronger pointers to our builders on, for instance, what frameworks and libraries are advisable and supported and by supporting onboarding current elements to the anticipated state for our software program. We have over the past 12 months doubled the share of elements that totally use our commonplace expertise stacks and plan to proceed increasing the stacks and driving this adoption over the approaching years.
Improved tooling
Lastly, we’ll give attention to simplifying our Fleet Management tooling and persevering with our long-term technique to boost the platform abstraction stage we expose to our builders. We need each developer at Spotify to have the ability to simply and safely carry out a fleet-wide change.
Look out for extra posts
Now that we’ve outlined the advantages of adopting a fleet-first mindset, how did we truly implement it? In future posts on this sequence, you’ll get to study extra about the best way we implement declarative infrastructure at Spotify and the opposite infrastructure adjustments we made to help Fleet Management. In the meantime, you possibly can study extra about our shift to fleet-first pondering on Spotify R&D’s official podcast — NerdOut@Spotify
[ad_2]