{kind=link}
[ad_1]
April 05, 2023 Published by Ciarán Gilligan-Lee, Thanos Vlontzos
Introduction
Understanding trigger and impact relationships in Spotify knowledge to tell decision-making is essential for finest serving Spotify’s customers and the corporate. The generally-accepted gold normal resolution to this downside is to conduct a randomised managed trial, or A/B check. However, in lots of conditions such trials can’t be carried out; they may very well be unethical, exorbitantly costly, or technologically infeasible. In the absence of such trials, many strategies have been developed to deduce the causal influence of an intervention or therapy from observational knowledge given sure assumptions. One of probably the most broadly used causal inference approaches in economics, advertising, and medication are artificial management strategies.
To concretely illustrate artificial controls, contemplate the launch of an promoting marketing campaign in a particular geographic area, aimed to extend gross sales of a product there. To estimate the influence of this marketing campaign, the artificial management technique makes use of the variety of gross sales of the product in several areas, the place no coverage change was applied, to construct a mannequin which predicts the pre-campaign gross sales within the marketing campaign area. This mannequin is then used to foretell product gross sales within the marketing campaign area within the counterfactual world the place no promoting marketing campaign was launched. By evaluating the mannequin prediction to precise gross sales in that area after the marketing campaign was launched, one can estimate its influence.
In the usual artificial management set-up, the mannequin is taken to be a weighted, linear mixture of gross sales within the no-campaign areas. To practice the mannequin, one wants to find out the weights for gross sales in every no-campaign area that minimise the error when predicting the gross sales within the marketing campaign area earlier than the marketing campaign was launched. The linearity of the mannequin is justified by assuming an underlying linear issue mannequin for all areas, or items, that’s the identical all the time intervals, each earlier than and after the intervention. Recent work has eliminated the necessity for the linear issue mannequin assumption and confirmed identifiability from a non-parametric assumption: that items are aggregates of smaller items. This assumption is cheap in conditions like our promoting marketing campaign instance, the place complete gross sales in a area is simply the mixture of gross sales from every particular person in that area. However, in lots of purposes, this assumption doesn’t apply. In medication as an example, sufferers will not be typically thought-about to be aggregates of smaller items. When the mixture unit assumption can’t be justified, can the causal impact of an intervention on a particular unit be recognized from knowledge about “similar” items not impacted by the intervention?
Returning to our instance, the rationale gross sales in several areas present good artificial management candidates is that the causes of gross sales in most areas are very comparable, consisting of demographic elements, socioeconomic standing of residents, and so forth. Informally, gross sales in “similar” areas act as proxies for these, typically unobserved, causes of gross sales within the marketing campaign area. That is, earlier than the marketing campaign, the causes of gross sales within the marketing campaign area are additionally causes of gross sales within the no-campaign area—they’re widespread causes of the marketing campaign and no-campaign areas. This relationship between the goal variable and artificial management candidates is illustrated as a directed acyclic graph, or DAG, within the beneath Figure. Previous work mixed this formulation with outcomes from the proximal causal inference literature to show one can establish the causal impact of an intervention on the goal unit from knowledge concerning the proxy items not impacted by the intervention. Hence, in our instance, observing gross sales in a number of no-campaign areas permits one to foretell the contemporaneous evolution of gross sales within the marketing campaign area within the absence of the marketing campaign with no need any linearity assumptions.
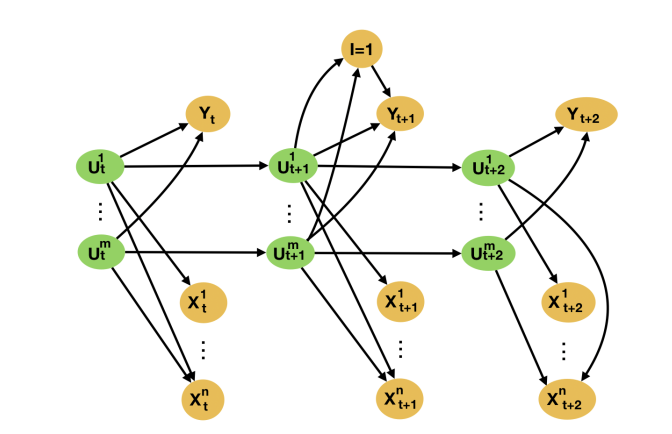
However, in all earlier identifiability proofs, it’s implicitly assumed that the underlying assumptions are glad all the time intervals, each pre- and post-intervention. This is a powerful assumption, as fashions can solely be discovered within the pre-intervention interval. That is, one of many important assumptions underlying the validity of artificial management fashions is that there isn’t any unobserved heterogeneity within the relationship between the goal and the management time-series noticed within the pre-intervention interval. Such unobserved heterogeneity may, as an example, be resulting from unaccounted-for causes of the goal unit.
In our paper we addressed this problem, and proved identifiability might be obtained with out the necessity for the requirement that assumptions maintain all the time intervals earlier than and after the intervention, by proving it follows from the precept of invariant causal mechanisms. Moreover, for the primary time, we formulate and examine artificial management fashions in Pearl’s structural causal mannequin framework.
Sensitivity evaluation
As the assumptions underlying our identifiability proof can’t be empirically examined—as with all causal inference outcomes—it’s vital to conduct a proper sensitivity evaluation to find out robustness of the causal estimate to violations of those assumptions. In propensity-based causal inference as an example, sensitivity evaluation has been performed to find out how strong propensity-based causal estimates are to the presence of unobserved confounders. These sensitivity analyses derived a relationship between the affect of unobserved confounders and the ensuing bias in causal impact estimation. This understanding permits one to certain bias in causal impact estimation as a operate of unobserved confounder affect. From this a website professional can supply judgments of the bias resulting from believable ranges of unobserved confounding.
However, regardless of the significance of this downside—and the huge use of artificial management strategies in lots of disciplines—common strategies for sensitivity evaluation of artificial management strategies are under-studied. Our paper remedied this discrepancy and supplied a common framework for sensitivity evaluation of artificial management causal inference to violations of the assumptions underlying our nonparametric identifiability proof.
Bounding the potential bias
One of the principle assumptions of our identifiability proof is that the DAG from the introduction is glad. But this may be violated if there’s an underlying latent, and proxy thereof, that we now have not been capable of embody in our evaluation. Such a scenario is graphically illustrated within the beneath DAG. Our purpose is to certain the bias that such a scenario may result in.
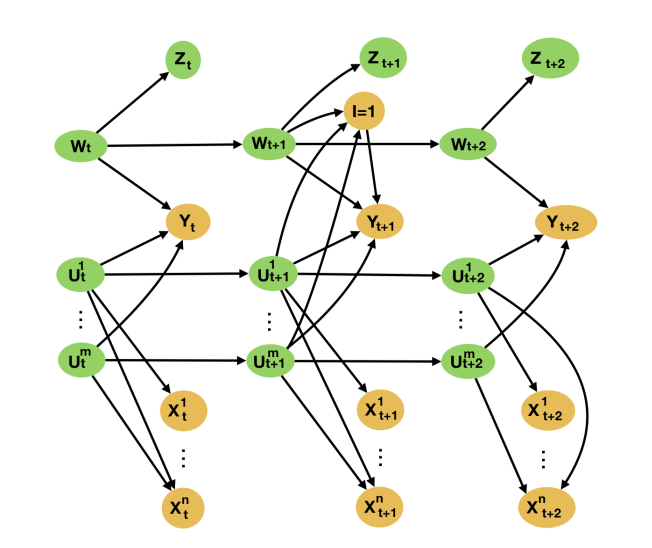
As with all sensitivity analyses, the certain we derive in our paper on the bias is by way of latent portions. As such, an analyst might want to make plausibility judgments to be able to devise a certain by way of observable portions. Indeed, if an analyst believes they haven’t missed latent causes as necessary to our downside as those they included proxies for, then we are able to higher certain the bias within the worst case by taking the maximums within the above certain on the bias to be the maximums within the noticed.
To check our certain, we assessed its validity on a collection of artificial and actual world knowledge. Using simulations, we examine our certain in a sound and invalid setting. Moreover, we check on well-known open supply datasets used ceaselessly in artificial management papers to display the certain in an actual world setting.
Conclusion
One of probably the most broadly used causal inference approaches are artificial management strategies. However, in all earlier identifiability proofs, it’s implicitly assumed that the underlying assumptions are glad all the time intervals each pre- and post-intervention. This is a powerful assumption, as fashions can solely be discovered within the pre-intervention interval. Our paper addressed this problem, and proved identifiability with out the necessity for this assumption by exhibiting it follows from the precept of invariant causal mechanisms. Moreover, for the primary time, we formulated and studied artificial management fashions in Pearl’s structural causal mannequin framework.
Importantly, we supplied a common framework for sensitivity evaluation of artificial management fashions to violations of the assumptions underlying nonparametric identifiability. We concluded by offering an empirical demonstration of our sensitivity evaluation method on real-world knowledge.
For full particulars, see our paper
Non-parametric identifiability and sensitivity evaluation of artificial management fashions
Jakob Zeitler, Athanasios Vlontzos, & Ciarán M. Gilligan-Lee
CLeaR (Causal Learning and Reasoning), 2023
[ad_2]