{kind=link}
[ad_1]
February 21, 2022 Published by Ghazal Fazelnia, Ben Carterette and Mounia Lalmas

Music suggestion programs at Spotify are constructed on fashions of customers and gadgets. They typically depend on previous consumer interactions to study customers’ preferences and generate applicable representations of those preferences. In this paper, which is introduced at WSDM 2022, we developed an strategy for studying consumer representations based mostly on their previous interactions.
In music suggestion, customers’ pursuits at any time are formed by the next elements:
- General preferences for music listening
- Momentary pursuits in a specific kind of music
The first forms of pursuits are primarily slow-moving and should range gently over time. However, the second sorts are fast-moving preferences, and symbolize instantaneous tastes which could change quickly.
For occasion, an off-the-cuff music listener Bob usually likes Pop and R&B genres and listens to them regularly. Last month, Bob began exploring Jazz music for a few days. More not too long ago, he has been exploring Classical music and has discovered it attention-grabbing. Now, a recommender mannequin is making an attempt to grasp his music style to counsel him the proper music monitor to take heed to. If we glance into the majority of his listening, Pop and R&B music are highlighted. However, we all know that extra not too long ago he has been exploring music throughout the Classical style. How can we greatest symbolize consumer pursuits in the intervening time? If we had been to suggest a monitor, ought to we concentrate on his all-time favorites Pop and R&B or his momentary curiosity within the Classical style? Or each? How would the 2 curiosity teams, basic and momentary, work together with one another and the way ought to we account for them?
By recognizing these two totally different parts of consumer pursuits, we developed an strategy for studying consumer illustration based mostly on slow-moving and fast-moving options. Our mannequin is predicated on a variational autoencoder structure with sequential and non-sequential parts to investigate fast-moving and slow-moving options, respectively. We name the mannequin FS-VAE. We practice the mannequin on the following merchandise (monitor) prediction job.
We evaluated FS-VAE on a dataset consisting of music listening and interactions for customers over a 28-day interval. Our experiments confirmed clear enhancements over the prediction job in comparison with state-of-the-art approaches and verified the advantages of our strategy on this suggestion job. Our methodology confirmed quite a few benefits:
- By defining gradual and quick options, we will seize basic customers’ preferences alongside their instantaneous tastes.
- Modeling gradual and quick options with non-sequential and sequential parts permits us to study the majority of consumer tastes via aggregation at scale whereas individually analyzing latest fast-moving options for capturing momentary tastes.
- The probabilistic nature of our mannequin for consumer illustration learns a operate via the inference course of for illustration quite than level estimates. Variational inference permits us to study non-linearities in extremely complicated consumer habits and higher perceive listening patterns.
Data
We work on a streaming dataset consisting of a pattern of over 150k customers and 3M tracks over a 28-day interval. As we concentrate on studying consumer illustration, we let every monitor be represented by an 80-dimensional real-valued vector acquired in a pre-processing step by way of a Word2Vec-based mannequin. This dataset accommodates the occasions of every listening occasion and aggregated customers’ interactions with tracks (if any). These are i) whole variety of likes, ii) whole variety of tracks added to their playlists, iii) whole variety of skipped tracks, and eventually iv) whole variety of restarts (restarting a monitor).
Model
Our mannequin consists of variational encoder and decoder blocks. To seize basic and all-time consumer preferences, we design a daily encoder that takes in aggregates of historic consumer interactions. A second sequential element within the encoder block takes in quick options individually similar to latest consumer interplay. This permits the mannequin to study any momentary style or tendencies in consumer preferences. The consumer illustration is then the output of the encoder state, which is taken in by the decoder. We practice the mannequin end-to-end on the following monitor performed by the consumer.
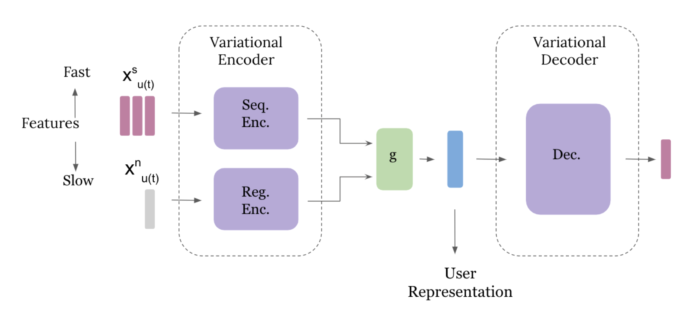
The sequential encoder consists of two LSTM cells with LeakyReLU activation operate. The common encoder and decoders are two-layer feedforward networks with LeakyReLU activations.
Results
To consider the efficiency of our mannequin FS-VAE, we examine with a number of baselines:
- Vanilla RNN: This baseline takes within the sequential options and trains an RNN mannequin to foretell the following monitor performed by a consumer.
- Aggregate Sequence: For this baseline, we combination the sequential options and feed them together with the gradual options to the mannequin.
- Popularity: We use recognition to suggest the following tracks to the customers.
- Average: Since we’re coaching and predicting within the monitor embedding house, this baseline takes the typical of previous tracks listened to by a consumer as the following monitor prediction.
- LatentCross: This RNN-based mannequin combines the sequential options with contextual options right into a deep structure for a recommender system.
- JODIE: This mannequin learns the embeddings from sequential and contextual options.
- VAE Collaborative Filtering: This is a collaborative filtering baseline that trains a variational autoencoder for suggestion duties.
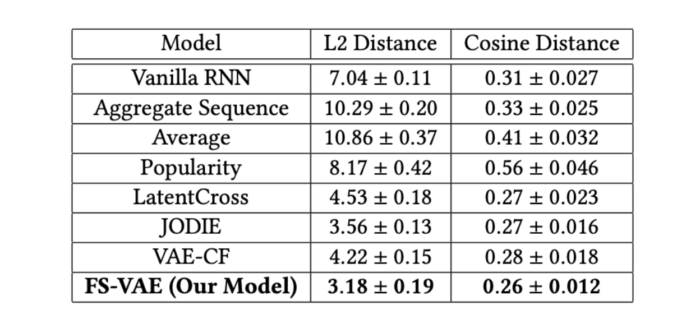
Our metrics are norm-2 distance and cosine distance between the expected monitor and floor fact throughout the 80-dimensional monitor illustration house. Our mannequin resulted in vital enchancment in prediction distances for the following monitor performed by the customers in a check set in comparison with different baselines.
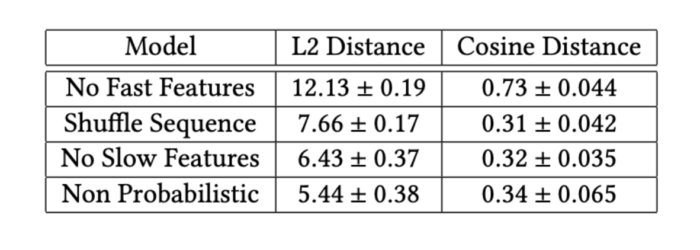
To additional examine quick and slow-moving options in addition to our mannequin parts, we ran ablation research. We analyzed the outcomes with i) no quick options, ii) no gradual options, iii) non-probabilistic structure (optimizing for max probability as a substitute of the variational goal), and eventually, iv) shuffling sequential options. The final one may very well be an indicator of whether or not there’s any beneficial info within the order with which tracks seem in sequences consumed by customers. As famous within the following desk, we observe that the prediction errors enhance certifying the essential function every characteristic and element performs.
Summary
In music streaming functions, customers’ preferences at any given second are influenced by their basic pursuits in addition to their instantaneous tastes. Our purpose is to study these elements and seize them in customers’ embeddings from the slow-moving and fast-moving options, respectively. We develop a variational autoencoder mannequin that distinctively processes slow-moving and fast-moving enter options in non-sequential and sequential mannequin parts respectively. Our experimental outcomes on the following monitor prediction job on a Spotify streaming dataset present clear enhancements over the present baselines.
More info could be present in our paper:
Variational User Modeling with Slow and Fast Features
Ghazal Fazelnia, Eric Simon, Ian Anderson, Ben Carterette, & Mounia Lalmas.
WSDM 2022.
[ad_2]