[ad_1]
By Alex Hutter, Falguni Jhaveri, and Senthil Sayeebaba
In a earlier publish, we described the indexing structure of Studio Search and the way we scaled the structure by constructing a config-driven self-service platform that allowed groups in Content Engineering to spin up search indices simply.
This publish will focus on how Studio Search helps querying the info obtainable in these indices.
When we are saying Content Engineering groups are serious about looking towards the federated graph, the use-case is especially centered on known-item search (a person has an merchandise or objects in thoughts they’re attempting to view or navigate to however want to make use of an exterior info system to find them) and information retrieval (sometimes the info is structured and there’s no ambiguity as as to if a selected report matches the given search standards besides within the case of textual fields the place there may be restricted ambiguity) inside a vertical search expertise (focus on enabling seek for a particular sub-graph inside the large federated graph)
Given the above scope of the search (vertical search expertise with a concentrate on known-item search and information retrieval), one of many first issues we needed to design was a language that customers can use to simply categorical their search standards. With a aim of abstracting customers away from the complexity of interacting with Elasticsearch straight, we landed on a customized Studio Search DSL paying homage to SQL.
The DSL helps specifying the search standards as comparability expressions or inclusion/exclusion filters. The filter expressions could be mixed collectively by way of logical operators (AND, OR, NOT) and grouped collectively by way of parentheses.
For instance, to search out all comedies from France or Spain, the question could be:
(style == ‘comedy’) AND (nation ANY [‘FR’, ‘SP’])
We used ANTLR to construct the grammar for the Query DSL. From the grammar, ANTLR generates a parser that may stroll the parse tree. By extending the ANTLR generated parse tree customer, we have been in a position to implement an Elasticsearch Query Builder element with the logic to generate the Elasticsearch question akin to the customized search question.
If you’re conversant in Elasticsearch, you then is likely to be conversant in how difficult it may be to construct up the proper Elasticsearch question for advanced queries, particularly if the index contains nested JSON paperwork which add an extra layer of complexity with respect to constructing nested queries (Incorrectly constructed nested queries can result in Elasticsearch quietly returning mistaken outcomes). By exposing only a generic question language to the customers and isolating the complexity to only our Elasticsearch Query Builder, now we have been in a position to empower customers to jot down search queries with out requiring familiarity with Elasticsearch. This additionally leaves the potential for swapping Elasticsearch with a unique search engine sooner or later.
One different problem for the customers when writing the search queries is to know the fields which might be obtainable within the index and the related sorts. Since we index the info as-is from the federated graph, the indexing question itself acts as self-documentation. For instance, given the indexing question –

To discover motion pictures primarily based on the actors’ roles, the question filter is solely
`actors.position == ‘actor’`
While the search DSL supplies a strong method to assist slender the scope of the search queries, customers can even discover paperwork within the index by way of free type textual content — both with simply the enter textual content or together with a filter expression within the search DSL. Behind the scenes through the indexing course of, now we have configured the Elasticsearch index with the suitable analyzers to make sure that essentially the most related matches for the enter textual content are returned within the outcomes.
Given the extensive adoption of the federated gateway inside Content Engineering, we determined to implement the Studio Search service as a DGS (Domain Graph Service) that built-in with the federated gateway. The search APIs (moreover search, now we have different APIs to assist faceted search, typeahead options, and many others) are uncovered as GraphQL queries inside the federated graph.
This integration with the federation gateway permits the search DGS to only return the matching entity keys from the search index as an alternative of the entire matching doc(s). Through the facility of federation, customers are then in a position to hydrate the search outcomes with any information obtainable within the federated graph. This permits the search indices to be lean by indexing solely the fields vital for the search expertise and on the similar time supplies full flexibility for the customers to fetch any information obtainable within the federated graph as an alternative of being restricted to only the info obtainable within the search index.
Example
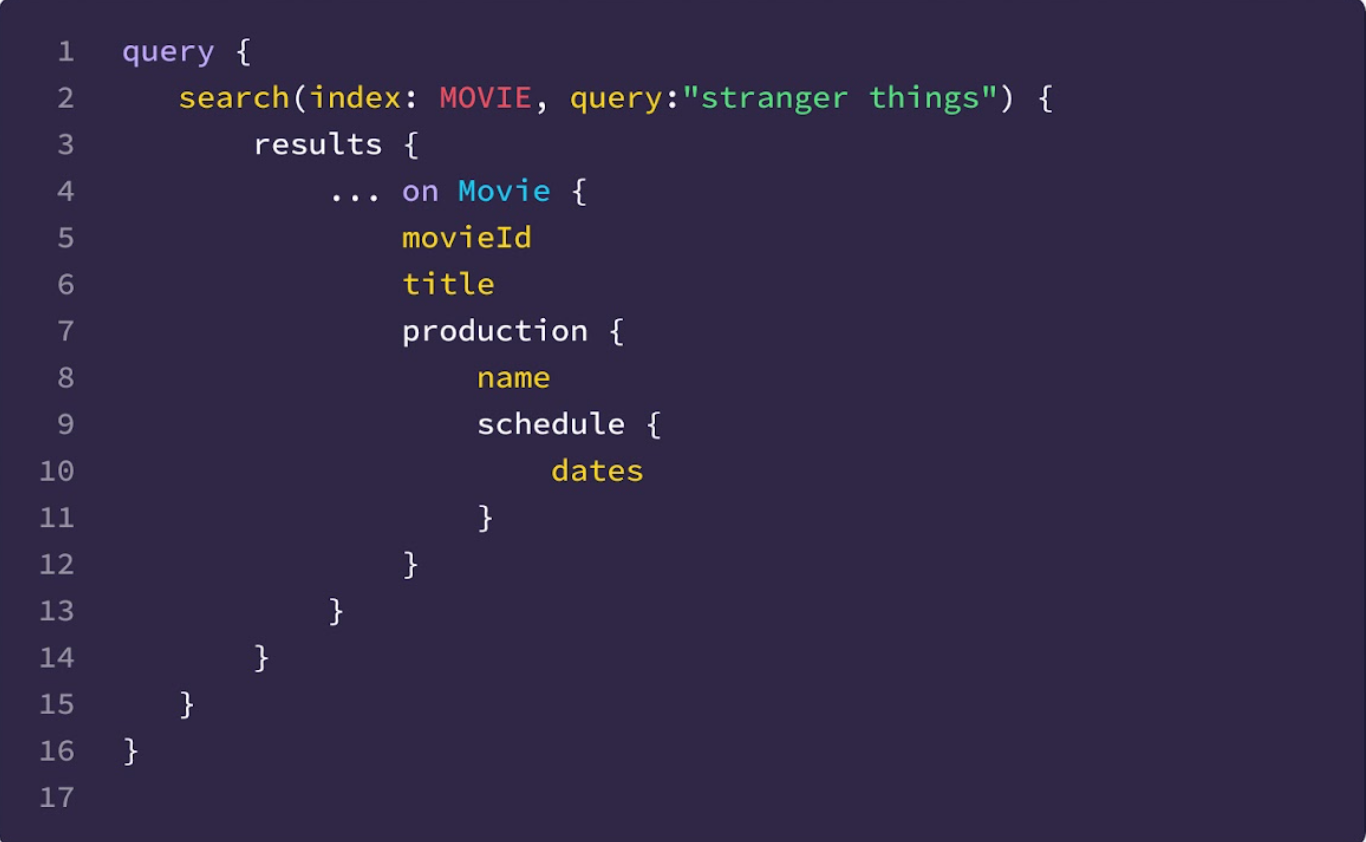
In the above instance, customers are in a position to fetch the manufacturing schedule as a part of the search outcomes despite the fact that the search index doesn’t maintain that information.
With the API to question the info within the search indices in place, the subsequent factor we would have liked to deal with was determining the best way to safe entry to the info within the indices. With a number of of the indices together with delicate information, and the supply groups already having restrictive entry insurance policies in place to safe the info they personal, the search indices which hosted a secondary copy of the supply information wanted to be secured as effectively.
We selected to use “late binding” (or “query time”) safety — on each incoming search question, we make an API name to the centralized entry coverage server with context together with the id of the caller making the request and the search index they’re attempting to entry. The coverage server evaluates the entry insurance policies outlined by the supply groups and returns a set of constraints. Ex. The caller has entry to Movies the place the sort is ‘licensed’ (The caller doesn’t have entry to Netflix-produced content material, however simply the licensed content material). The constraints are then translated to a set of filter expressions within the search question DSL format (Ex. film.sort == ‘licensed’) and mixed with the user-specified search filter with a logical AND operator to type a brand new search question that then will get executed towards the index.
By including on the entry constraints as further filters earlier than executing the question, we make sure that the person will get again solely the info they’ve entry to from the underlying search index. This additionally permits supply groups to evolve their entry insurance policies independently understanding that the proper constraints might be utilized at question time.
With the choice to construct Studio Search as a GraphQL service utilizing the DGS framework and counting on federation for hydrating outcomes, onboarding new search indices required updating numerous parts of the GraphQL schema (the enum of obtainable indices, the union of all federated consequence sorts, and many others.) manually and registering the up to date schema with the federated gateway schema registry earlier than the brand new index was obtainable for querying by way of the GraphQL API.
Additionally, there are further configurations that customers can present whereas onboarding a brand new index to customise the search habits for his or her functions — together with scripts to tune the relevance scoring algorithm, configuring fields for faceted search, and configuration to manage the habits of typeahead options, and many others. These configurations have been initially saved in our supply management repository which meant any adjustments to the configuration of any index required a deployment for the adjustments to take impact.
Recently, we automated this course of as effectively by shifting all of the configurations to a persistence retailer and leveraging the facility of dynamic schemas within the DGS framework. Users can now use an API to create/replace search index configuration and we’re in a position to validate the offered configuration, generate the up to date DGS schema dynamically and register the up to date schema with the federated gateway schema registry instantly. All configuration adjustments are mirrored instantly in subsequent search queries.
Example configuration:
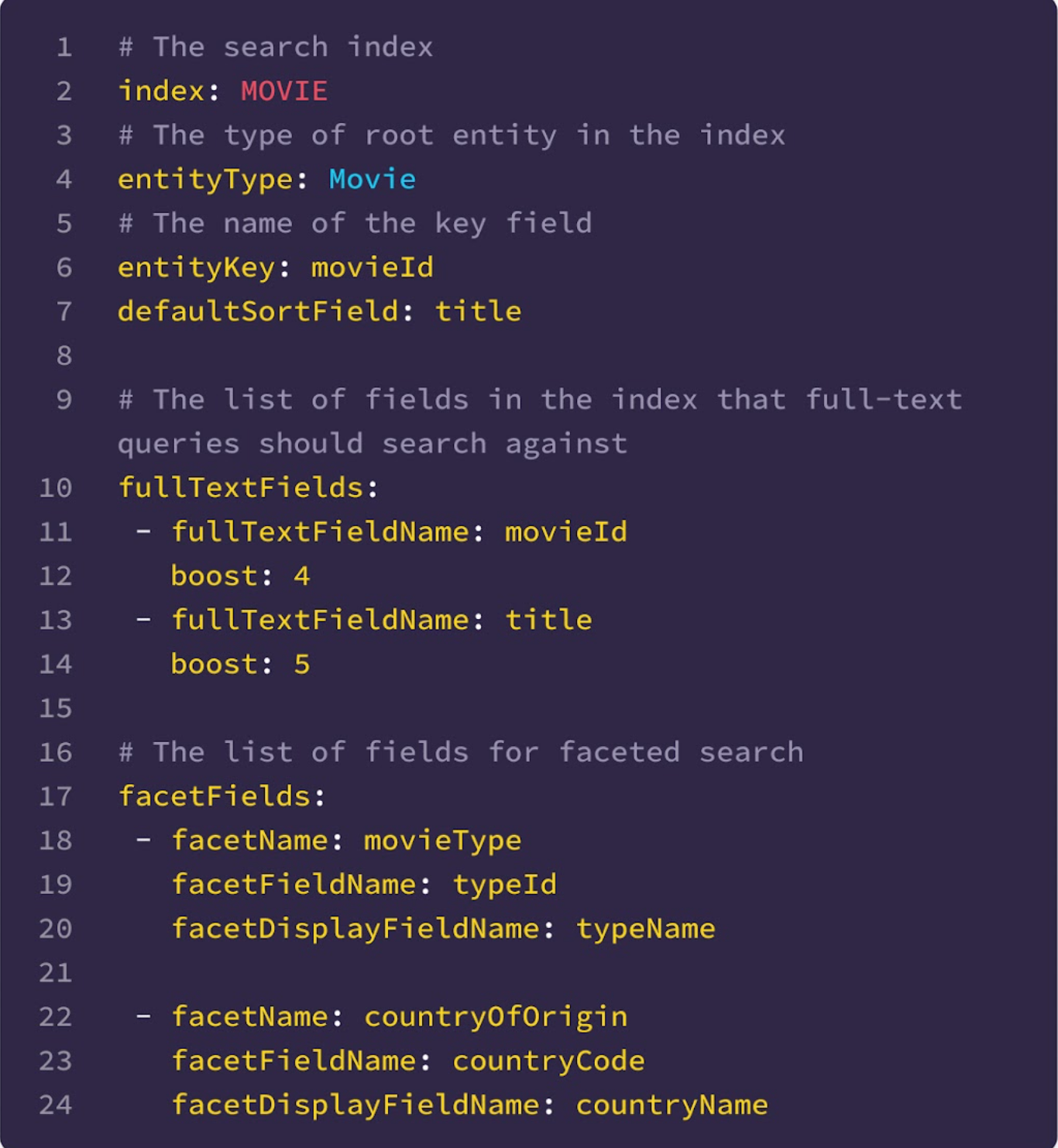
While the first aim of Studio Search was to construct an easy-to-use self-service platform to allow looking towards the federated graph, one other vital aim was to assist the Content Engineering groups ship a visually constant search expertise to the customers of their instruments and workflows. To that finish, we partnered with our UI/UX groups to construct a strong set of opinionated presentational elements. Studio Search’s providing of drop-in UI elements primarily based on our Hawkins design system for typeahead suggestion, faceted search, and intensive filtering guarantee visible and behavioral consistency throughout the suite of functions inside Content Engineering. Below are a few examples.
Typeahead Search Component
Faceted Search Component
As a config-driven, self-serve platform, Studio Search has already been in a position to empower Content Engineering groups to shortly allow the performance to go looking towards the Content federated graph inside their suite of functions. But, we aren’t fairly achieved but! There are a number of upcoming options which might be in numerous phases of improvement together with
- Leveraging the percolate question performance in Elasticsearch to assist a notifications function (customers save their search standards and are notified when paperwork are up to date within the index that matches their search standards)
- Add assist for metrics aggregation in our APIs
- Leverage the managed supply performance in Spinnaker to maneuver to a declarative mannequin for onboarding the search indices
- And, loads extra
If this sounds fascinating to you, join with us on LinkedIn.
Thanks to Anoop Panicker, Bo Lei, Charles Zhao, Chris Dhanaraj, Hemamalini Kannan, Jim Isaacs, Johnny Chang, Kasturi Chatterjee, Kishore Banala, Kevin Zhu, Tom Lee, Tongliang Liu, Utkarsh Shrivastava, Vince Bello, Vinod Viswanathan, Yucheng Zeng
[ad_2]