{kind=link}
[ad_1]
September 22, 2022 Printed by Maryam Aziz, Jesse Anderton, Kevin Jamieson, Alice Wang, Hugues Bouchard, Javed Aslam
A lot of new podcasts are launched each month on Spotify and different on-line media platforms. On this work, we examine methods to establish new podcasts which can be more likely to enchantment to giant audiences. These podcasts may then be fast-tracked for editorial curation and suggestion to customers.
A standard strategy to figuring out promising new podcasts is to coach a supervised mannequin to foretell the viewers dimension of a podcast primarily based on the efficiency of extra established podcasts. We explored such a mannequin and ran right into a limitation: though we have been capable of predict the long run reputation of recent podcasts pretty reliably, the podcasts we recognized have been usually from creators who have already got a big viewers exterior of podcasting or a big social media following. These elements can assist a podcast to develop, however don’t straight correspond to how a lot listeners will get pleasure from them. That’s, reputation for brand new podcasts is commonly a measure of the viewers already established by the creator or current social media followings on different platforms moderately than a direct measure of listener desire. As proven beforehand within the literature [1], common gadgets are inclined to develop into extra common impartial of their “high quality.” To account for this, we outlined an idea we name “common enchantment,” which is the variety of customers who would stream a podcast in the event that they have been uncovered to it in a managed randomized trial.
We discover that predicting reputation and viewers development potential usually are not the identical factor and that some machine studying options will be sub-optimal. To resolve this, we suggest a novel non-contextual bandit algorithm notably well-suited to the duty of figuring out podcasts with excessive common enchantment. We confirmed that its efficiency is aggressive with the best-known algorithms for this job, and that it’s higher suited when the person’s response to a suggestion takes a while to measure.
Our Supervised Method
We first look at methods to predict a podcast’s future viewers dimension utilizing a supervised mannequin. We in contrast a number of off-the-shelf machine studying fashions with three units of options. The options have been used to foretell the variety of streams on day 60-90. We use two classes of options:
- consumption options: we included the variety of streams of a podcast and its whole variety of hours streamed in addition to the variety of customers who streamed and who adopted the podcast. The options have been computed over varied 30 day home windows, utilizing statistics for the primary 30 days and days 31-60. We additionally used statistics as of the podcast’s launch day.
- content material options: we embrace the podcast’s matter, details about the size and readability of its description, whether or not any social media accounts are listed in its description, and statistics about its quantity and frequency of episode publication.
We skilled our fashions utilizing the next three units of options: simply consumption options, simply content material options, and each consumption and content material options. Our SortByPopularity baseline picks the highest ok podcasts as sorted by the variety of streams within the prior 30 days. To judge, we predict the variety of streams at 60-90 days for every podcast in our check set and choose the highest ok predicted to have essentially the most streams. We report precision@ok for every methodology within the desk under.
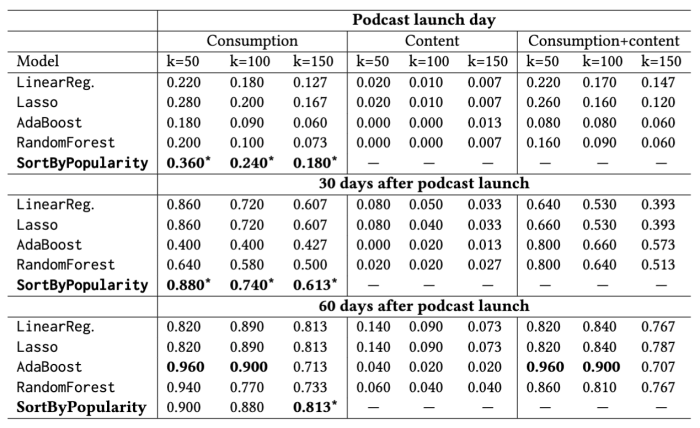
We discovered a number of fascinating outcomes. Within the first place, the content material options produce better-than-random predictions, so that they do include some predictive energy, however they don’t carry out in addition to the consumption options. Combining the content material and consumption options tends to provide a worse consequence than utilizing the consumption options alone. Though content material options didn’t assist with predicting potential viewers sizes, we count on them to be extra necessary for different duties corresponding to suggestion duties. When recommending content material to a selected person, we might wish to leverage content material options to match content material particular to an individual’s preferences. The forms of content material options we’d count on to be most necessary for predicting viewers dimension are essentially the most troublesome to provide, e.g. the host’s charisma and novel points of the podcast. Our second foremost discovering is that SortByPopularity outperforms all our supervised fashions aside from AdaBoost 60 days after launch. In our work, we look at AdaBoost extra intently and discover that the extra indicators it makes use of to enhance on SortByPopularity are primarily the opposite consumption options.
To summarize, one of the simplest ways to select the most-streamed podcasts in days 60-90 after launch is to select the most-streamed podcasts earlier of their lifecycle. A podcast’s efficiency relative to different podcasts of its age is strongly predictive of future efficiency, so podcast streaming seems to strongly exhibit “rich-get-richer” dynamics.
Issues with a Supervised Method
Now we have discovered that early streaming is predictive of future streaming, which may doubtlessly be defined in some ways. It might be that some podcasts succeed each early on and within the coming months, during which case reputation could be a dependable indicator of a podcast’s potential viewers dimension. Nonetheless, a big physique of analysis means that this isn’t more likely to be the case: many elements aside from listener desire can drive streaming. We offer two items of proof in our paper that such elements contribute to the variety of streams between days 60 and 90 put up podcast launch, suggesting that podcasts which have the potential to be highly regarded however that don’t naturally receive the identical degree of streaming could also be neglected.
The primary signal that reputation shouldn’t be a dependable indicator of listener desire was primarily based on a handbook inspection of the highest 100 podcasts sorted by streams between days 60 and 90 post-launch. A lot of the prime streamed podcasts have been created by individuals who have already got a big viewers exterior of podcasting and/or have current social media followings on different platforms. Estimators of a podcast’s potential viewers dimension which can be impartial of a podcast’s present reputation permit us to floor extra podcasts whose creators might not but be well-known.
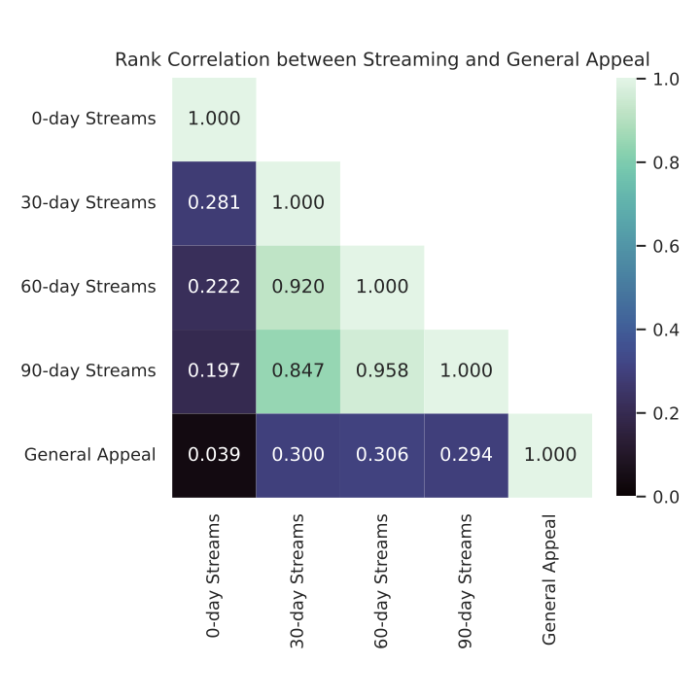
For our second piece of proof that reputation shouldn’t be equivalent to potential viewers dimension, we straight measured the final enchantment of a set of podcasts. We outline “common enchantment” because the variety of customers who would stream a podcast if proven it in a managed random trial. This worth corresponds to the podcast’s potential viewers dimension if sufficient folks knew in regards to the podcast. We carried out such a trial for a inhabitants of 700 podcasts and measured their common enchantment. Once we regarded on the correlation between their common enchantment and their stream counts (under), we discovered that the numbers are solely barely correlated. On this trial, reputation and common enchantment had a rank correlation of solely round 0.3, which means that a few of the most-streamed podcasts had comparatively low common enchantment and that a few of the most interesting podcasts had comparatively few streams.
Put collectively, these items of proof recommend {that a} supervised strategy to figuring out new podcasts with giant development potential has limitations. We subsequent focus on another strategy.
Our Bandit Method
Ideally, we might have the ability to straight measure the final enchantment of all podcasts and use that info for suggestion. That may include frequently working a random experiment during which every podcast could be proven to many customers chosen at random. Given the big variety of podcasts being created every month, this could imply we might be continually exhibiting many customers podcasts that they’re usually bored with, which creates a poor expertise for these customers. As a substitute, we wish to be extra strategic: we wish to use as few customers as potential to establish the perfect new 100 or 1,000 podcasts, with out exactly measuring the final enchantment of all podcasts within the course of.
This job, choosing the highest ok gadgets from a really giant pool, is known as the Mounted-Finances Infinitely-Armed Pure-Exploration Non-contextual Bandit downside. It’s “fixed-budget” as a result of we wish to suggest podcasts to a small variety of customers, i.e. the person finances we use is fastened forward of time; it’s “infinitely-armed” as a result of we’ve got too many “arms” (podcasts) to have the ability to measure all of them exactly; it’s “pure-exploration” as a result of we wish to deal with effectively figuring out the perfect podcasts; it’s “non-contextual” as a result of we aren’t utilizing any options for the duty.
Now we have created an algorithm, which we name ISHA, to effectively resolve this downside. A selected problem for this job is that we’ve got delayed rewards: it takes a considerable period of time for customers to reply to suggestions, so the algorithm can’t assume it’ll obtain suggestions instantaneously. The variant of our algorithm known as Unforgetful ISHA has aggressive efficiency with the perfect algorithms for this downside by way of precisely discovering the perfect podcasts, and on the similar time, it’s dramatically sooner than its rivals in a delayed reward setting.
We measure how precisely the algorithm is ready to establish the perfect podcast given a set variety of customers (its “finances”) utilizing a measure known as easy remorse, which is the distinction between the final enchantment of the podcast the algorithm selected and the final enchantment of the perfect accessible podcast. The graph under compares the efficiency of Unforgetful ISHA with a number of baseline algorithms. The three greatest algorithms by way of easy remorse are Unforgetful ISHA, Successive Rejects, and Empirical CBT. These algorithms are essentially the most environment friendly at figuring out the perfect podcasts with the fewest variety of customers.
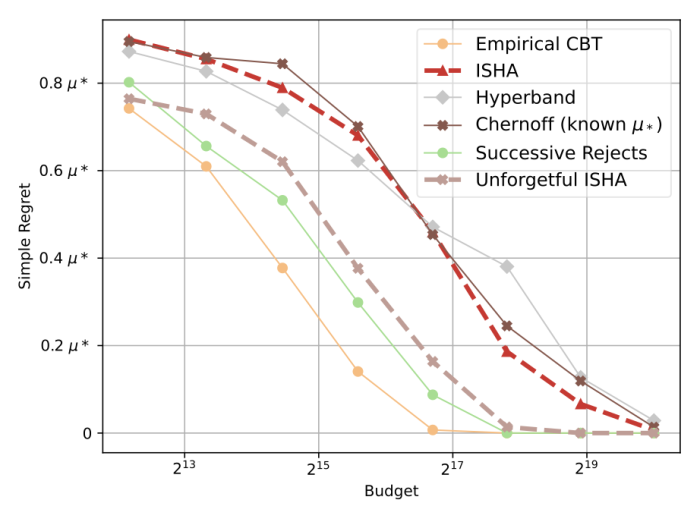
Nonetheless, it is usually necessary that the algorithm have the ability to full in an affordable period of time. Most bandit algorithms assume instantaneous rewards, however in follow, every arm pull (podcast suggestion) is determined by human suggestions and so it could possibly take an considerable period of time to measure the reward. For instance, was the podcast streamed inside 24 hours of the advice? This length constrains the length of every spherical of the algorithm. Say if we have been fascinated about discovering the perfect of 32,000 new podcasts every month and the suggestions took 24 hours. Unforgetful ISHA would solely take two weeks to finish, which is asymptotically sooner than Successive Rejects and Empirical CBT. Solely Unforgetful ISHA is ready to full in an affordable period of time on this delayed reward setting.
Closing Ideas
Figuring out essentially the most promising new podcasts with a minimal influence on podcast listeners is essential. While we will simply establish podcasts that, on their very own, will receive essentially the most person streaming, it’s tougher to establish podcasts that customers truly get pleasure from essentially the most. Our algorithm, Unforgetful ISHA, makes it potential to establish such podcasts as they’re launched, with a sufficiently small variety of required customers and a quick sufficient runtime in a delayed suggestions setting to maintain up with the speed at which podcasts are launched.
Figuring out New Podcasts with Excessive Basic Attraction Utilizing a Pure Exploration Infinitely-Armed Bandit Technique
Maryam Aziz, Jesse Anderton, Kevin Jamieson, Alice Wang, Hugues Bouchard, Javed Aslam
RecSys 2022
References
[1] Experimental Examine of Inequality and Unpredictability in an Synthetic Cultural Market
Matthew J. Salganik, Peter Sheridan Dodds & Duncan J. Watts.
[ad_2]