{kind=link}
[ad_1]
Timestone: Netflix’s Excessive-Throughput, Low-Latency Precedence Queueing System with Constructed-in Assist for Non-Parallelizable Workloads
Introduction
Timestone is a high-throughput, low-latency precedence queueing system we constructed in-house to help the wants of our media encoding platform, Cosmos. Over the previous 2.5 years, its utilization has elevated, and Timestone is now additionally the precedence queueing engine backing our general-purpose workflow orchestration engine (Conductor), and the scheduler for large-scale knowledge pipelines (BDP Scheduler). All in all, hundreds of thousands of crucial workflows inside Netflix now circulate by way of Timestone on a every day foundation.
Timestone purchasers can create queues, enqueue messages with user-defined deadlines and metadata, then dequeue these messages in an earliest-deadline-first (EDF) vogue. Filtering for EDF messages with standards (e.g. “messages that belong to queue X and have metadata Y”) can also be supported.
One of many issues that make Timestone totally different from different precedence queues is its help for a assemble we name unique queues — this can be a means to mark chunks of labor as non-parallelizable, with out requiring any locking or coordination on the patron facet; every part is taken care of by the unique queue within the background. We clarify the idea intimately within the sections that observe.
Why Timestone
When designing the successor to Reloaded — our media encoding system — again in 2018 (see “Background” part in The Netflix Cosmos Platform), we would have liked a precedence queueing system that would supply queues between the three parts in Cosmos (Determine 1):
- the API framework (Optimus),
- the ahead chaining rule engine (Plato), and
- the serverless computing layer (Stratum)
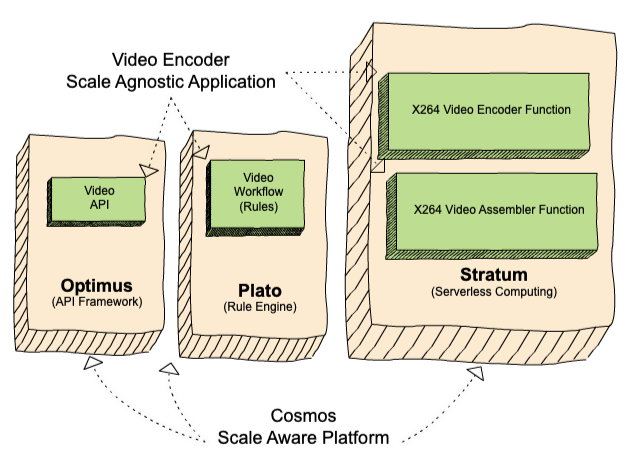
A number of the key necessities this precedence queueing system would wish to fulfill:
1. A message can solely be assigned to 1 employee at any given time. The work that tends to occur in Cosmos is resource-intensive, and might fan out to 1000’s of actions. Assume then, that there’s replication lag between the replicas in our knowledge retailer, and we current as dequeueable to employee B the message that was simply dequeued by employee A by way of a special node. Once we do this, we waste vital compute cycles. This requirement then throws finally constant options out of the window, and means we would like linearizable consistency on the queue stage.
2. Enable for non-parallelizable work.
Given that Plato is constantly polling all workflow queues for extra work to execute —
Whereas Plato is executing a workflow for a given mission (a request for work on a given service) —
Then Plato shouldn’t be in a position to dequeue further requests for work for that mission on that workflow. In any other case Plato’s inference engine will consider the workflow prematurely, and will transfer the workflow to an incorrect state.
There exists then, a sure sort of labor in Cosmos that shouldn’t be parallelizable, and the ask is for the queueing system to help the sort of entry sample natively. This requirement gave delivery to the unique queue idea. We clarify how unique queues work in Timestone within the“Key Ideas” part.
3. Enable for dequeueing and queue depth querying utilizing filters (metadata key-value pairs)
4. Enable for the automated creation of a queue upon message ingestion
5. Render a message dequeueable inside a second of ingestion
We constructed Timestone as a result of we couldn’t discover an off-the-shelf answer that meets these necessities.
System Structure
Timestone is a gRPC-based service. We use protocol buffers to outline the interface of our service and the construction of our request and response messages. The system diagram for the appliance is proven in Determine 2.
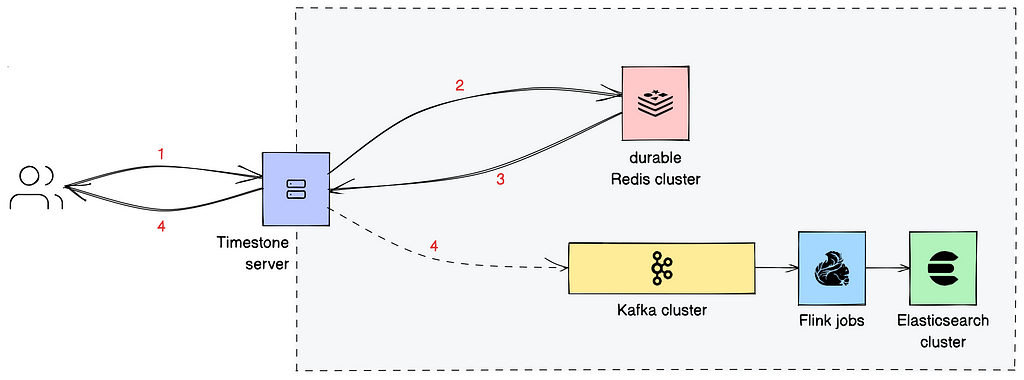
System of document
The system of document is a sturdy Redis cluster. Each write request (see Step 1 — be aware that this consists of dequeue requests since they alter the state of the queue) that reaches the cluster (Step 2) is endured to a transaction log earlier than a response is shipped again to the server (Step 3).
Contained in the database, we signify every queue with a sorted set the place we rank message IDs (see “Message” part) in response to precedence. We persist messages and queue configurations (see “Queues” part) in Redis as hashes. All knowledge constructions associated to a queue — from the messages it comprises to the in-memory secondary indexes wanted to help dequeue-by-filter — are positioned in the identical Redis shard. We obtain this by having them share a standard prefix, particular to the queue in query. We then codify this prefix as a Redis hash tag. Every message carries a payload (see “Message” part) that may weigh as much as 32 KiB.
Virtually all the interactions between Timestone and Redis (see “Message States” part) are codified as Lua scripts. In most of those Lua scripts, we are inclined to replace numerous knowledge constructions. Since Redis ensures that every script is executed atomically, a profitable script execution is assured to depart the system in a constant (within the ACID sense) state.
All API operations are queue-scoped. All API operations that modify state are idempotent.
Secondary indexes
For observability functions, we seize details about incoming messages and their transition between states in two secondary indexes maintained in Elasticsearch. Once we get a write response from Redis, we concurrently (a) return the response to the consumer, and (b) convert this response into an occasion that we publish to a Kafka cluster, as proven in Step 4. Two Flink jobs — one for every sort of index we keep — devour the occasions from the corresponding Kafka subjects, and replace the indexes in Elasticsearch.
One index (“present”) provides customers a best-effort view into the present state of the system, whereas the opposite index (“historic”) provides customers a finest effort longitudinal view for messages, permitting them to hint the messages as they circulate by way of Timestone, and reply questions equivalent to time spent in a state, and variety of processing errors. We keep a model counter for every message; each write operation increments that counter. We depend on that model counter to order the occasions within the historic index. Occasions are saved within the Elasticsearch cluster for a finite variety of days.
Present Utilization at Netflix
The system is dequeue heavy. We see 30K dequeue requests per second (RPS) with a P99 latency of 45ms. Compared, we see 1.2K enqueue RPS at 25ms P99 latency. We usually see 5K RPS enqueue bursts at 85ms P99 latency. 15B messages have been enqueued to Timestone because the starting of the yr; these messages have been dequeued 400B instances. Pending messages usually attain 10M. Utilization is anticipated to double subsequent yr, as we migrate the remainder of Reloaded, our legacy media encoding system, to Cosmos.
Key Ideas
Message
A message carries an opaque payload, a user-defined precedence (see “Precedence” part), an elective (obligatory for unique queues) set of metadata key-value pairs that can be utilized for filter-based dequeueing, and an elective invisibility length. Any message that’s positioned right into a queue will be dequeued a finite variety of instances. We name these makes an attempt; every dequeue invocation on a message decreases the makes an attempt left on it.
Precedence
The precedence of a message is expressed as an integer worth; the decrease the worth, the upper the precedence. Whereas an software is free to make use of no matter vary they see match, the norm is to make use of Unix timestamps in milliseconds (e.g. 1661990400000 for 9/1/2022 midnight UTC).
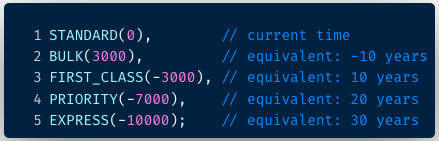
It is usually totally as much as the appliance to outline its personal precedence ranges. As an illustration a streaming encoding pipeline inside Cosmos makes use of mail precedence lessons, as proven in Determine 3. Messages belonging to the usual class use the time of enqueue as their precedence, whereas all different lessons have their precedence values adjusted in multiples of ∼10 years. The precedence is about on the workflow rule stage, however will be overridden if the request carries a studio tag, equivalent to DAY_OF_BROADCAST.
Message States
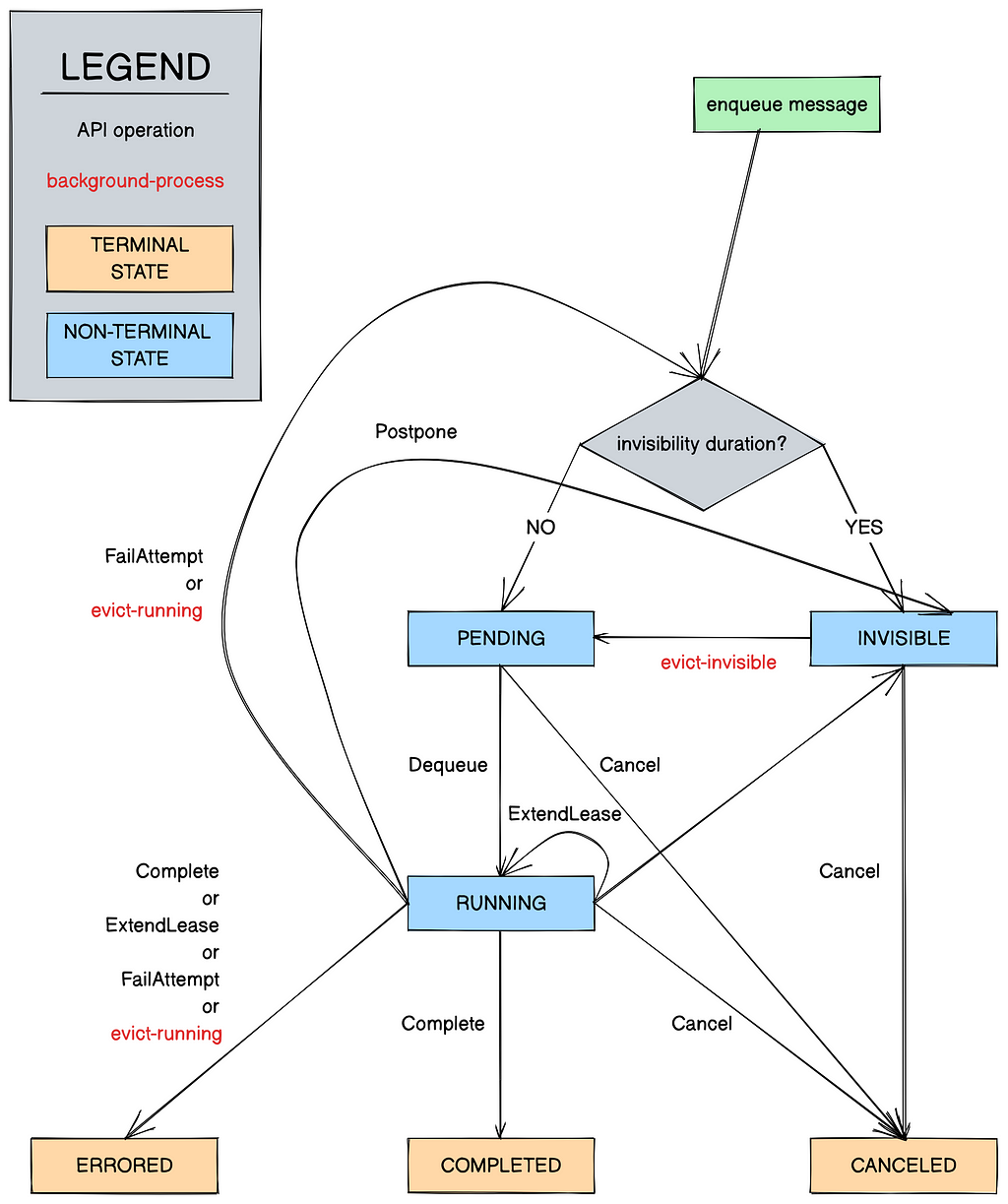
Inside a queue, a Timestone message belongs to one among six states (Determine 4):
- invisible
- pending
- operating
- accomplished
- canceled
- errored
Generally, a message will be enqueued with or with out invisibility, which makes the message invisible or pending respectively. Invisible messages turn into pending when their invisibility window elapses. A employee can dequeue a pending earliest-deadline-first message from a queue by specifying the period of time (lease length) they are going to be processing it for. Dequeueing messages in batch can also be supported. This strikes the message to the operating state. The identical employee can then difficulty a whole name to Timestone inside the allotted lease window to maneuver the message to the accomplished state, or difficulty a lease extension name in the event that they wish to keep management of the message. (A employee may transfer a usually operating message to the canceled state to sign it’s not want for processing.) If none of those calls are issued on time, the message turns into dequeueable once more, and this try on the message is spent. If there aren’t any makes an attempt left on the message, it’s moved routinely to the errored state. The terminal states (accomplished, errored, and canceled) are garbage-collected periodically by a background course of.
Messages can transfer states both when a employee invokes an API operation, or when Timestone runs its background processes (Determine 4, marked in crimson — these run periodically). Determine 4 reveals the whole state transition diagram.
Queues
All incoming messages are saved in queues. Inside a queue, messages are sorted by their precedence date. Timestone can host an arbitrary variety of user-created queues, and provides a set of API operations for queue administration, all revolving round a queue configuration object. Knowledge we retailer on this object consists of the queue’s sort (see remainder of part), the lease length that applies to dequeued messages, or the invisibility length that applies to enqueued messages, the variety of instances a message will be dequeued, and whether or not enqueueing or dequeueing is briefly blocked. Be aware {that a} message producer can override the default lease or invisibility length by setting it on the message stage throughout enqueue.
All queues in Timestone fall into two varieties, easy, and unique.
When an unique queue is created, it’s related to a user-defined exclusivity key — for instance mission. All messages posted to that queue should carry this key of their metadata. As an illustration, a message with mission=foo can be accepted into the queue; a message with out the mission key is not going to be. On this instance, we name foo, the worth that corresponds to the exclusivity key, the message’s exclusivity worth. The contract for unique queues is that at any time limit, there will be solely as much as one shopper per exclusivity worth. Due to this fact, if the project-based unique queue in our instance has two messages with the key-value pair mission=foo in it, and one among them is already leased out to a employee, the opposite one just isn’t dequeueable. That is depicted in Determine 5.
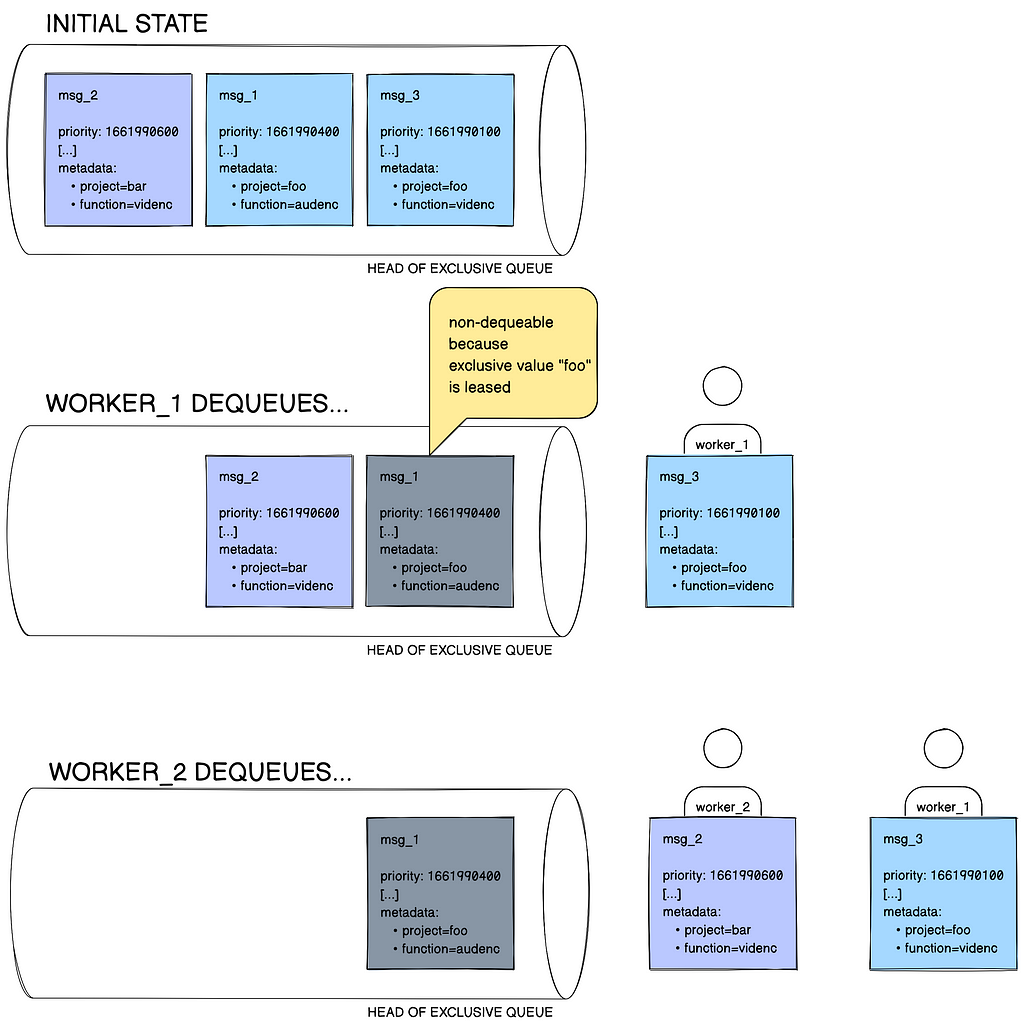
In a easy queue no such contract applies, and there’s no tight coupling with message metadata keys. A easy queue works as your typical precedence queue, merely ordering messages in an earliest-deadline-first vogue.
What We Are Working On
A number of the issues we’re working on:
- Because the the utilization of Timestone inside Cosmos grows, so does the necessity to help a variety of queue depth queries. To resolve this, we’re constructing a devoted question service that makes use of a definite question mannequin.
- As famous above (see “System of document” part), a queue and its contents can solely presently occupy one Redis shard. Scorching queues nonetheless can develop huge, esp. when compute capability is scarce. We wish to help arbitrarily giant queues, which has us constructing help for queue sharding.
- Messages can carry as much as 4 key-value pairs. We presently use all of those key-value pairs to populate the secondary indexes used throughout dequeue-by-filter. This operation is exponentially complicated each by way of time and house (O(2^n)). We’re switching to lexicographical ordering on sorted units to drop the variety of indexes by half, and deal with metadata in a extra cost-efficient method.
We could also be protecting our work on the above in follow-up posts. If these sorts of issues sound attention-grabbing to you, and in case you just like the challenges of constructing distributed methods for the Netflix Content material and Studio ecosystem at scale normally, you need to think about becoming a member of us.
Acknowledgements
Poorna Reddy, Aravindan Ramkumar, Surafel Korse, Jiaofen Xu, Anoop Panicker, and Kishore Banala have contributed to this mission. We thank Charles Zhao, Olof Johansson, Frank San Miguel, Dmitry Vasilyev, Prudhvi Chaganti, and the remainder of the Cosmos workforce for his or her constructive suggestions whereas creating and working Timestone.
Timestone: Netflix’s Excessive-Throughput, Low-Latency Precedence Queueing System with Constructed-in Assist… was initially revealed in Netflix TechBlog on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.
[ad_2]