{kind=link}
[ad_1]
April 13, 2023

As of March 8, 2023, Spotify has began serving brief previews for music, podcasts, and audiobooks on the house feed. (You can see the announcement at Stream On on YouTube, beginning at 19:15.) This is a big elevate for in-app content material discovery — a transfer away from making listening choices primarily based on static content material, resembling cowl artwork, to utilizing the audio content material itself as a teaser. It has been an effort throughout many groups on the firm. The path to producing the house feed podcast previews for tens of millions of episodes on Google Dataflow, making use of the Apache Beam Python SDK, has been an advanced one.
In 2021, Spotify acquired Podz to speed up audio discovery. Podz had been engaged on approaches to producing 60-second podcast previews, leveraging the most recent developments in pure language processing (NLP) and audio machine studying (ML), together with transformers. At the time of the acquisition, the Podz stack was composed of a variety of microservices, every internet hosting a person mannequin. It additionally counted on a central API that will ingest and transcribe new episode content material, course of every episode by calling the ML companies utilizing directed acyclic graph (DAG) logic and surfacing the previews to a cell app UI primarily based on user-preview affinity. The ML companies have been adequate to generate preview offsets for a number of thousand podcast episodes per day. However, we discovered that the Spotify podcast catalog was rising at a fee of a whole bunch of 1000’s of episodes a day!
To scale as much as Spotify’s wants, we needed to undertake a completely managed pipeline system that would function at scale, robustly, and with a decrease latency per podcast episode. We might have managed our personal Kubernetes service, however that will have been quite a lot of work: updates, scaling, safety, and reliability of the assets, amongst different issues. Instead we selected Google Dataflow, a managed pipeline execution engine constructed on prime of open supply Apache Beam. Dataflow manages Dockerized computational graphs / DAGs over units of inputs in batch or streaming, it’s optimized for low latency, and it autoscales relying on demand. Beam constructing blocks embody operations like ParDo and Map, which the Dataflow engine optimizes by fusing into pipeline levels in Dataflow and enabling distributed parallel processing of the enter knowledge.
Determining our technique for producing podcast previews was an attention-grabbing problem.
Raw audio supply knowledge
The supply of the content material is uncooked audio and transcription knowledge, which must run via numerous preprocessing duties to arrange it for enter into the fashions. We used supply transforms to learn and course of this knowledge from our storage system, which included steps to deduplicate content material to keep away from pointless work, adopted by the ML steps and, lastly, the handoff to downstream storage.
Many fashions and frameworks
There are over a half dozen fashions inside the pipeline that must be constructed as an ensemble, together with fine-tuned language fashions and sound occasion detection. The fashions are educated with totally different ML frameworks, together with Tensorflow, PyTorch, Scikit-learn, and Gensim. Most of the frameworks on the market! This launched three challenges:
- Finding one of the best path to assemble these fashions within the pipeline form. For instance, as totally different nodes in a single Apache Beam rework or as separate transforms inside the Apache Beam DAG.
- Choosing the appropriate {hardware} (machine dimension and GPUs) to realize our latency and throughput objectives.
- Deciding on the easiest way to take care of library dependencies when utilizing all these frameworks collectively.
Addressing challenges
For challenges 1 and a couple of, we factored within the dimension of the fashions and determined to create a number of transforms, every with its personal ensemble. We determined to make use of NVIDIA T4 GPUs, so we had 16 GB of reminiscence to work with and one rework containing the majority of the fashions. This mitigated the code complexity of the pipeline in addition to knowledge switch throughout fashions. However, it additionally implied quite a lot of swapping fashions out and in of GPU reminiscence and compromising on pipeline visibility, as errors and logs for the majority of our logic can be situated inside the identical very dense ParDo operation. We used fusion breaks in between these transforms to make sure the GPU solely loaded one stage of fashions at a time.
As for problem 3, we made use of Dataflow’s capability to use customized containers to assist remedy for the dependency challenges. Generating Docker photographs to correctly resolve the dependencies throughout all these fashions along with Dataflow was tough. We used Poetry to resolve dependencies forward of Dockerization, and we referred to the Dataflow SDK dependencies web page for steering about which variations of our mannequin frameworks and knowledge processing dependencies can be appropriate with Python SDK variations for Dataflow. However, regionally resolved and Dockerized dependencies would nonetheless run into runtime decision errors, the answer for which we focus on intimately later.
Generalization of the pipeline
Our outcome was an hourly scheduled, customized container Dockerized, batch Beam pipeline. The subsequent problem was to take care of a number of variations of the pipeline. In addition to our current-production pipeline, we wanted a staging (experimental) pipeline for new-candidate variations of the preview era and a light-weight “fallback” pipeline for content material with decrease viewership and content material that the manufacturing pipeline would fail to supply well timed output for. To keep all of those related pipelines collectively, we developed a typical DAG construction with the identical code template for all of them. We additionally added a variety of Dataflow-native timers and failure counters to profile our code and to measure enhancements over numerous sources of latency and errors over time.
The price of operating numerous GPU machines year-round is elevated, so we utilized some tips to mitigate this price whereas additionally bettering on latency. We initially disabled autoscaling as a result of we rendered it pointless for batch jobs with fixed-size hourly enter partitions. We might simply estimate the variety of employees wanted to finish every enter in an hour and optimize by spinning up and tearing down precisely that variety of employees.
However, latency from queueing up inputs hourly in addition to from machine spin-up and teardown meant we needed to optimize additional. A nicety of Apache Beam is that as a result of it helps each batch and streaming with the identical API, there may be little code change wanted to modify between the 2. Therefore, we moved to a streaming system, which was a bigger enchancment in price and latency, and a reversal on a few of our earlier choices. In streaming mode, autoscaling is perfect and is reenabled. The job can decide what number of assets it wants dynamically primarily based on enter visitors. This additionally reduces the time and value of spinning up and tearing down machines between hourly partitions.
With batch pipelines, we have been in a position to produce a preview two hours after the episode had been ingested. We wished to carry this latency right down to minutes for 2 causes:
1. Some episodes are time delicate, resembling day by day information.
2. Listeners of extremely popular reveals count on the discharge of a model new episode at a specific time, on a specific day of the week.
We determined to discover Apache Beam and Dataflow additional by making use of a library, Klio. Klio is an open supply venture by Spotify designed to course of audio recordsdata simply, and it has a monitor document of efficiently processing music audio at scale. Moreover, Klio is a framework to construct each streaming and batch knowledge pipelines, and we knew that producing podcast previews in a streaming trend would scale back the era latency.
In a matter of 1 week, we had the primary model of our streaming podcast preview pipeline up and operating. Next, we labored on monitoring and observability. We began logging profitable and failing inputs right into a BigQuery desk, and within the latter case, we additionally logged exception messages. With Google Cloud Dashboards and Google Metrics Explorer, we have been in a position to shortly construct dashboards to inform us the scale of the backlog in our Pub/Sub queues and to arrange alerts in case the backlog grew too giant.
To measure the influence of this transformation, we used the median preview latency, that’s, the time between the episode ingestion and the completion of the podcast preview era. We in contrast two distinct weeks: one the place solely the batch pipeline was producing previews and one other when solely the Klio streaming pipeline was producing previews. The Klio streaming pipeline lowered the median preview latency from 111.7 minutes to three.7 minutes. That means the brand new pipeline generates previews 30 instances quicker than the batch pipeline. Quite an enchancment!
Below, you’ll be able to see preview latency distribution for each the Klio streaming and the batch pipeline. Because there may be fairly an extended tail, we have now plotted simply the leftmost 80% of episodes processed.
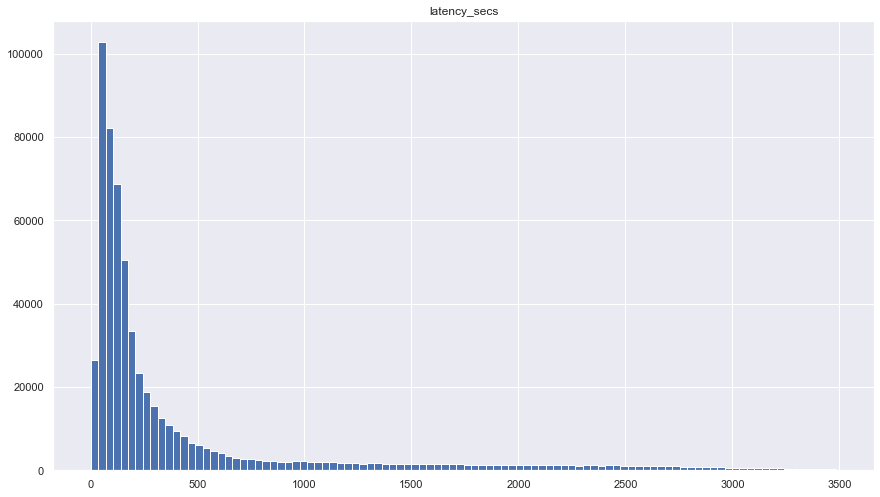
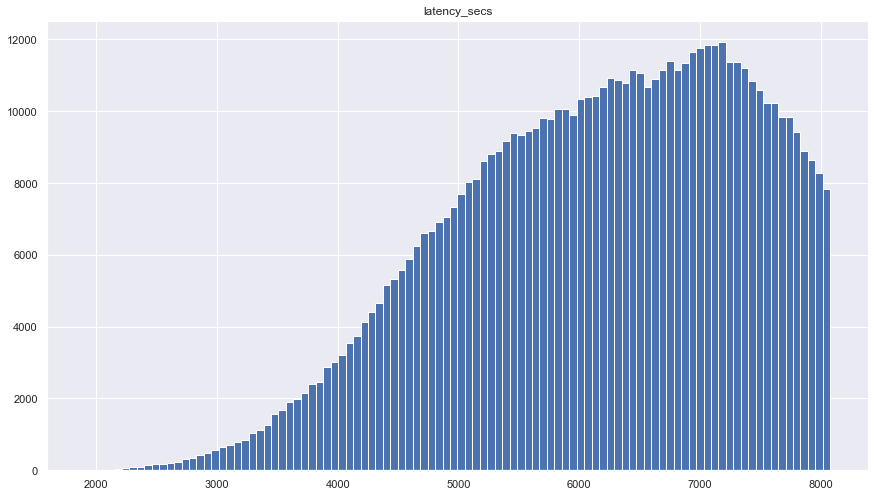
Common challenges
Whether utilizing batch or streaming pipelines, we needed to sort out some issues when operating pipelines on Dataflow. One was the pipeline dependency administration points encountered when utilizing a customized Docker container (by way of the --sdk_container_image flag) or when operating the job inside a VPN, a typical follow at many giant firms, together with Spotify. Debugging such errors is tough as a result of logging is commonly inadequate for monitoring down the error, and cloud employees might shut down or restart instantly after an error.
In one case, after upgrading the Apache Beam SDK from model 2.35.0 to 2.40.0, the pipeline began to fail inside 5 minutes of beginning the roles, with the error SDK harness disconnected. There have been no error logs stating the underlying concern. The SDK harness disconnected error implies that the method operating the pipeline code has crashed, and the reason for a crash is perhaps buried in a stream of information logs.
The upgraded pipeline did succeed at operating on small enter sizes (BigQuery enter supply), however began to fail with bigger enter sizes, for instance, better than 10,000 rows from the identical BigQuery enter supply. Because each jobs ran on the very same configuration, we initially suspected an out of reminiscence (OOM) error. That was dominated out primarily based on the historic proof that the identical pipeline had dealt with a a lot bigger throughput earlier than upgrading.
Upon additional debugging, we observed the bug occurred provided that a package deal grpcio==1.34.1 was put in along with google-cloud-pubsublite==1.4.2, and the bug didn’t manifest when both of the packages was up to date to their newest model. Given that we didn’t use Pub/Sub performance in our pipeline, the answer was to uninstall google-cloud-pubsublite within the Docker picture in spite of everything different dependencies had been put in.
To summarize, when upgrading to new variations of the Apache Beam SDK, the pipeline utilizing customized containers in a VPN may fail because of delicate adjustments in transitive dependency decision. Debugging such points is tough as a result of not all errors are logged contained in the Dataflow employees. It is vital to have visibility into model adjustments for all put in packages, together with transitive dependencies, and handbook inspection of prebuilt customized containers is required to establish the distinction. A future enchancment can be offering extra logging, tooling, and steering for dependency administration, particularly for customized containers. Another mitigating follow can be to utilize the GPU growth workflow described within the Dataflow documentation. The concept is to recreate an area surroundings that emulates the managed service as intently as potential.
Our future with Dataflow
Now that the Podcast Previews function has launched, we’re intently monitoring the conduct of our pipelines and adjusting our preview era to match noticed consumer engagement. We are additionally excited to check out two new Dataflow options. For instance, Dataflow Prime Right Fitting would permit us to specify useful resource necessities for every Dataflow step or ParDo, as an alternative of getting a single set of necessities for the complete pipeline. This would enhance useful resource utilization by allocating fewer assets to steps which are much less computationally costly, resembling studying inputs and writing outputs.
We are additionally excited in regards to the new RunInference API, which might permit us to interrupt down our dense ParDo into smaller steps. It would run components of the code that contain ML fashions continuously swapping out and in of reminiscence in machines devoted to particular person fashions over the period of the job. This function would additionally standardize our mannequin inference metrics and supply a method to additional improve pipeline throughput by intelligently batching our inputs.
It has been an extended journey to construct an efficient, versatile, and scalable system to generate podcast previews at Spotify for tens of millions of customers, and alongside the way in which, we’ve discovered many helpful classes. Using managed knowledge pipeline instruments, resembling Google Dataflow, provides worth by reducing the bar to construct and keep infrastructure, permitting us to give attention to the algorithms and the pipeline. Streaming has been proven to be a far superior system, regardless of requiring a little bit additional work. Finally, the job isn’t executed, and we need to proceed to push the boundaries of what’s potential each with knowledge engineering and knowledge science — enhancing the companies that we offer for our customers and creators.
We’d wish to thank everybody at Spotify and Google who helped us with this effort, together with Tim Chagnon (Senior Machine Learning Engineer, Spotify), Seye Ojumu (Senior Engineering Manager, Spotify), Matthew Solomon (Senior Engineer, Spotify), Ian Lozinski (Senior Engineer, Spotify), Jackson Deane (PM, Spotify), and Valentyn Tymofieiev (Software Engineer, Google).
Apache Beam, the Beam brand, and the Apache feather brand are both registered logos or logos of The Apache Software Foundation.
Tags: engineering management
[ad_2]