{kind=link}
[ad_1]
October 24, 2024 Published by Azin Ghazimatin and Ekaterina Garmash, Gustavo Penha, Kristen Sheets, Martin Achenbach, Oguz Semerci, Remi Galvez, Divya Narayanan, Ofeliya Kalaydzhyan, Ann Clifton, Paul N. Bennett, Claudia Hauff, Mounia Lalmas
Listeners usually discover it difficult to navigate lengthy podcast episodes on account of their lengthy length. This makes it troublesome for them to know the general construction and find particular sections of curiosity. A useful gizmo to handle this challenge is podcast chapterization, the place the content material is split into segments labeled with titles and timestamps. Although podcast creators can present chapters with their episodes, that is not often accomplished.
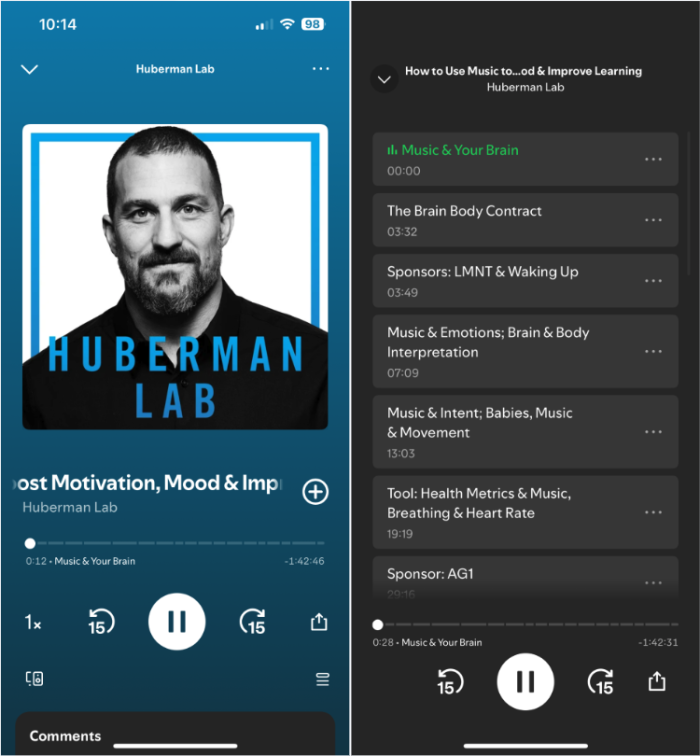
Examples of podcast chapters.
To prolong the advantages of chapterization to extra podcasts in our catalog, we’ve got developed a machine learning-based chapterization mannequin. This mannequin is skilled in a supervised means utilizing creator-provided chapterizations of their podcast episodes. The podcast area presents distinctive analysis challenges in comparison with earlier work on chapterization and semantic segmentation. Podcasts are sometimes conversational and lack a particular construction, with audio system generally diverging from the principle subject for brief durations. Additionally, episode transcripts are usually lengthy, requiring environment friendly processing strategies. In this submit, we describe our answer for automating podcast chapterization that addresses these challenges.

Comparison of typical podcast construction (left) and typical Wikipedia construction (proper).
PODTILE
We make use of giant language fashions and develop PODTILE, an LLM-based mannequin that concurrently generates chapter boundaries and titles for the enter transcript.
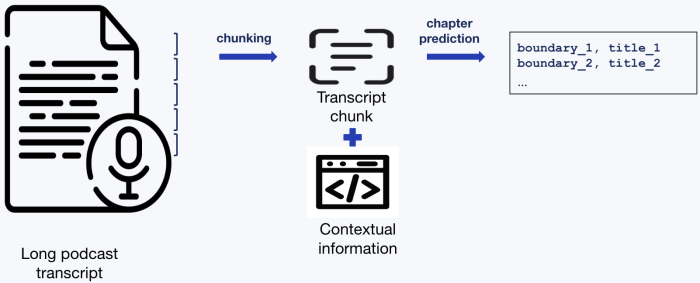
Podcast chapterization with PODTILE.
We use LongT5 with a 16k enter token restrict as our base LLM. This LLM is beneficial for capturing long-distance dependencies in podcast episodes. For transcripts longer than the 16K enter restrict, we break up textual content into smaller chunks and course of them independently, which might result in a lack of world context important to understanding the complete construction.
Predicting chapters based mostly on native chunks can lead to a lack of world context important for correct chapter prediction. To deal with this limitation, we enrich every chunk with world contextual cues to assist protect total coherence. Specifically, we leverage static context, together with metadata like episode titles and descriptions, and dynamic context, which maintains a file of beforehand generated chapter titles. This dynamic context acts as a working reminiscence to tell the era of future chapters. We embrace each sorts of data as textual content into the enter to the PODTILE mannequin.

PODTILE’s enter and output format. The static context comprises the episode’s title and outline, and the dynamic context consists of the sooner chapter titles.
Evaluation and Findings
We evaluated PODTILE on an inner podcast dataset utilizing title and boundary accuracy metrics generally utilized in textual content segmentation duties. Specifically, PODTILE demonstrated an 11% enchancment in title accuracy in comparison with the strongest baseline. Moreover, we discovered that for very lengthy podcasts, which required chunking as a result of mannequin’s enter size restrictions, the metric enhancements have been almost double these of shorter podcasts that didn’t want chunking. This discovering underscores the effectiveness of our modeling in capturing world (static and dynamic) context.

Comparison of the quantity of enchancment in lengthy transcripts vs. shorter ones that don’t want chunking.
We additionally carried out a qualitative comparability of chapter titles generated by PODTILE with these from the baseline. We discovered that, by leveraging static and dynamic context, PODTILE’s titles are extra informative.
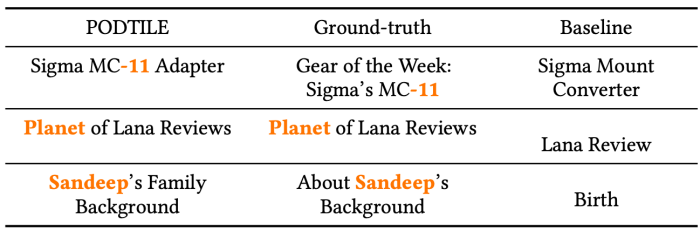
Comparison of chapter titles generated by PODTILE in opposition to these from the baseline. PODTILE’s chapter titles are extra informative.
In April 2024, we started a restricted roll-out of our chapterization mannequin.
We anticipated that by broadening the supply of chapters, high-quality auto-generated chapters will result in a rise in engagement. In truth, we noticed an 88.12% improve in chapter-initiated performs within the first month of the roll-out.
We additionally carried out an experiment to evaluate the influence of indexing chapter titles on search effectiveness. Using the TREC podcast dataset, designed for brief section retrieval and summarization, and using BM25 because the sparse retrieval methodology, we in contrast the efficiency of indexing episode descriptions alone in opposition to descriptions enriched with chapter titles. The outcomes confirmed a 24% improve in R@50 when chapter titles have been included within the episode description, demonstrating that chapter titles successfully summarize transcripts, which then enhances retrieval effectiveness.
Conclusions
We launched PODTILE, an answer for supervised podcast chapterization that successfully fashions the worldwide context of the episode. PODTILE addresses the challenges of maximum size, long-distance dependencies, and low structuredness. PODTILE outperforms state-of-the-art baselines in offline analysis, with notably notable enchancment for terribly lengthy podcasts. The deployed answer has considerably elevated our catalog protection, and evaluation of consumer interplay knowledge highlighted its worth for much less reputation reveals. Additionally, we evaluated PODTILE’s usefulness in different downstream duties: in offline analysis, we confirmed that including chapters to episode descriptions will increase episode search high quality.
For extra data, please discuss with our paper:
PODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Azin Ghazimatin and Ekaterina Garmash, Gustavo Penha, Kristen Sheets, Martin Achenbach, Oguz Semerci, Remi Galvez, Divya Narayanan, Ofeliya Kalaydzhyan, Ann Clifton, Paul N. Bennett, Claudia Hauff, Mounia Lalmas
CIKM 2024
[ad_2]