{kind=link}
[ad_1]
May 28, 2024

Check out Data Platform Explained Part I, the place we began sharing the journey of constructing an information platform, its constructing blocks, and the motivation for investing into constructing a platformized resolution at Spotify.
In Data Platform Explained Part I, we shared the primary steps within the journey to construct an information platform, the insights that point out it’s time to start out constructing one, and the way we’re organized to succeed on it. In this text, we’ll take one step additional into the why, what, and the way of our information platform, introduce you to the domains beneath it which might be answerable for the platform’s constructing blocks — right here we’ll discuss scalability, the tooling we use and supply, alongside the worth every constructing block brings to a knowledge platform — and at last our technique to navigate the complexity of an information ecosystem by constructing a powerful group round it.
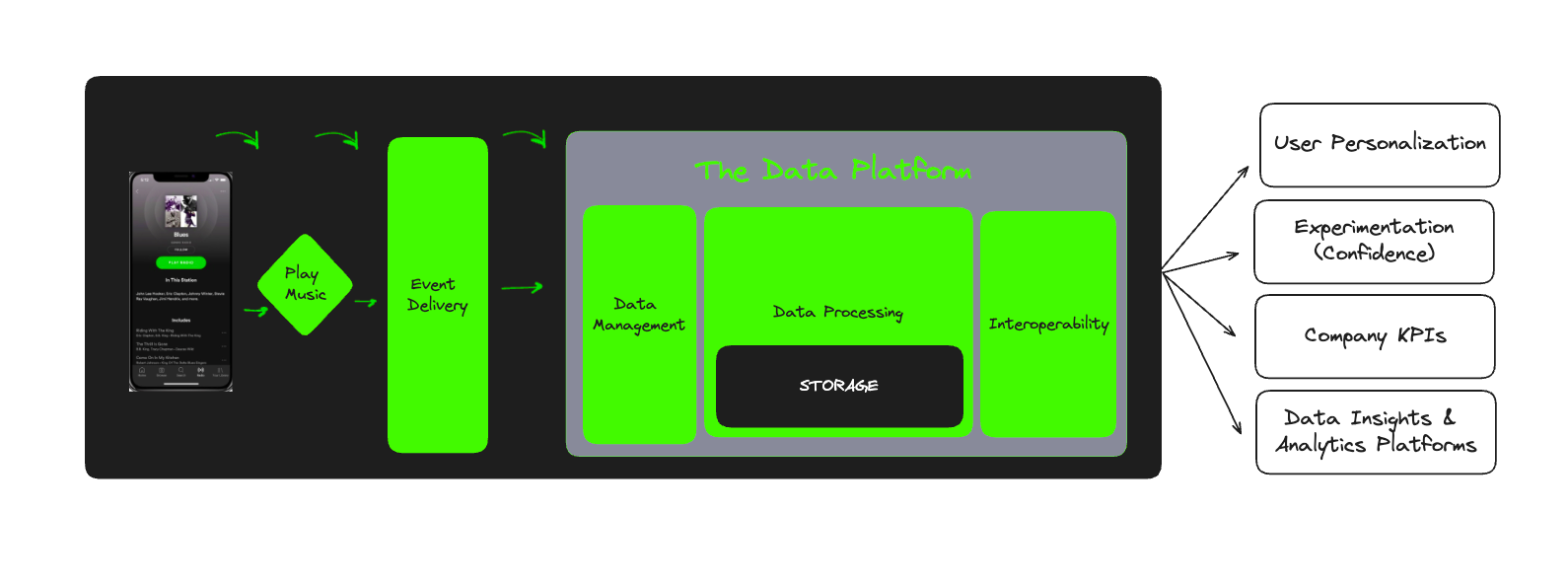
When it involves scalability, Spotify’s Data Collection platform collects greater than 1 trillion occasions per day. Its occasion supply structure is continually evolving by quite a few iterations. To be taught extra about the occasion supply evolution, its inception, and subsequent enhancements, take a look at this weblog submit.
Data Collection is required, so we are able to:
- Understand what content material is related to Spotify customers
- Directly reply to consumer suggestions
- Have a deeper understanding of consumer interactions to boost their expertise
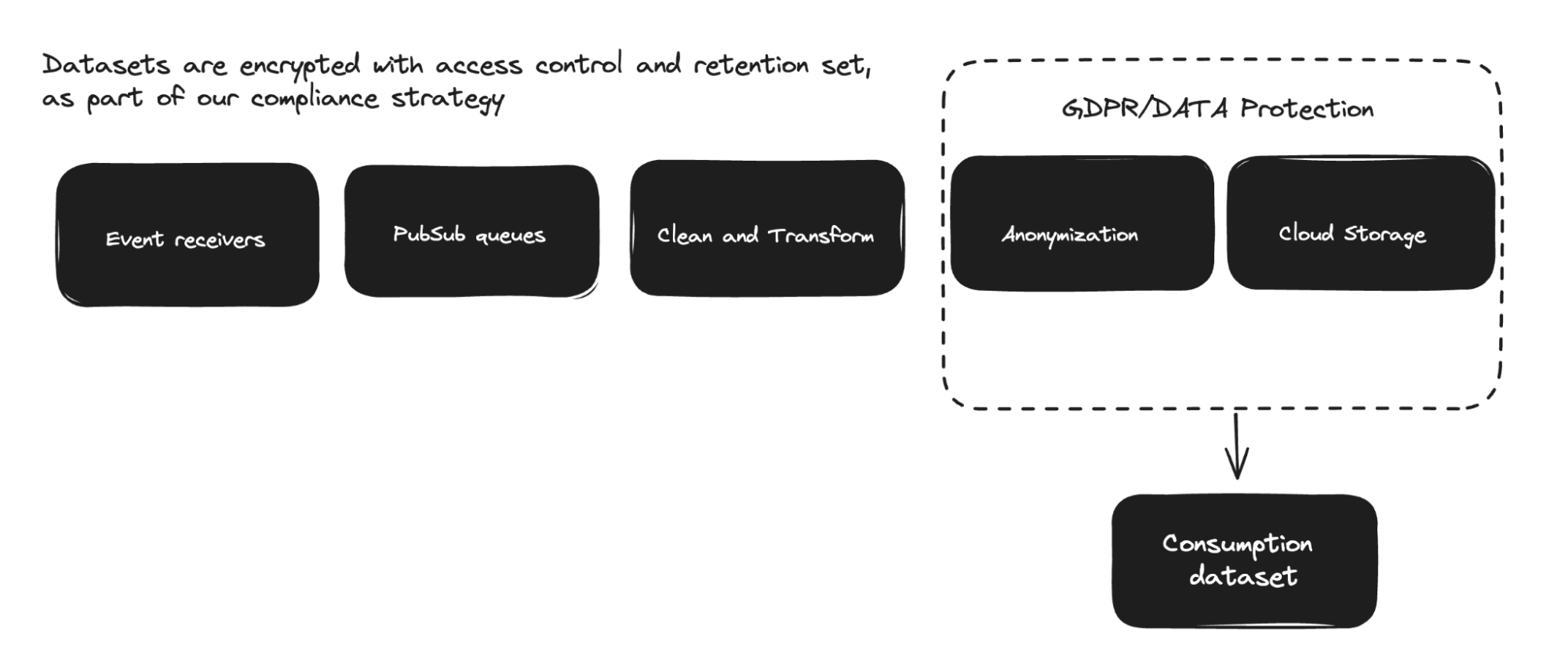
When a group at Spotify decides to instrument their performance with occasion supply, apart from writing code utilizing our SDs, they solely have to outline the occasion schemas. The infrastructure then robotically deploys a brand new set of event-specific elements (similar to PubSub queues, anonymization pipelines, and streaming jobs) utilizing K8 operators. Any modifications to the occasion schema triggers the deployment of corresponding sources. Anonymization options, together with inner key-handling techniques, are coated intimately in this text.
The stability between centralized and distributed possession permits most updates to be managed by customers of the consumption dataset, with out requiring intervention from the infrastructure group.
Today, over 1800 totally different occasion varieties — or indicators representing interactions from Spotify customers — are being revealed. In phrases of group construction, the info assortment space is organized to give attention to the occasion supply infrastructure, supporting and enhancing consumer SDKs for occasion transmission, and constructing the prime quality datasets that characterize the consumer journey expertise, in addition to the infrastructure wanted behind it.
Our Data Processing efforts give attention to empowering Spotify to make the most of information successfully, whereas Data Management is devoted to making sure information integrity by software creation and collaborative efforts. With greater than 38,000 actively scheduled pipelines dealing with each hourly and every day duties, scalability is a key consideration. Data Management and Data Processing are important for Spotify to successfully handle its in depth information and pipelines. It’s essential to keep up information traceability (lineage), searchability (metadata), and accessibility, whereas implementing entry controls and retention insurance policies to handle storage prices and adjust to laws. These features allow Spotify to extract most worth from its information property whereas upholding operational effectivity and regulatory requirements.
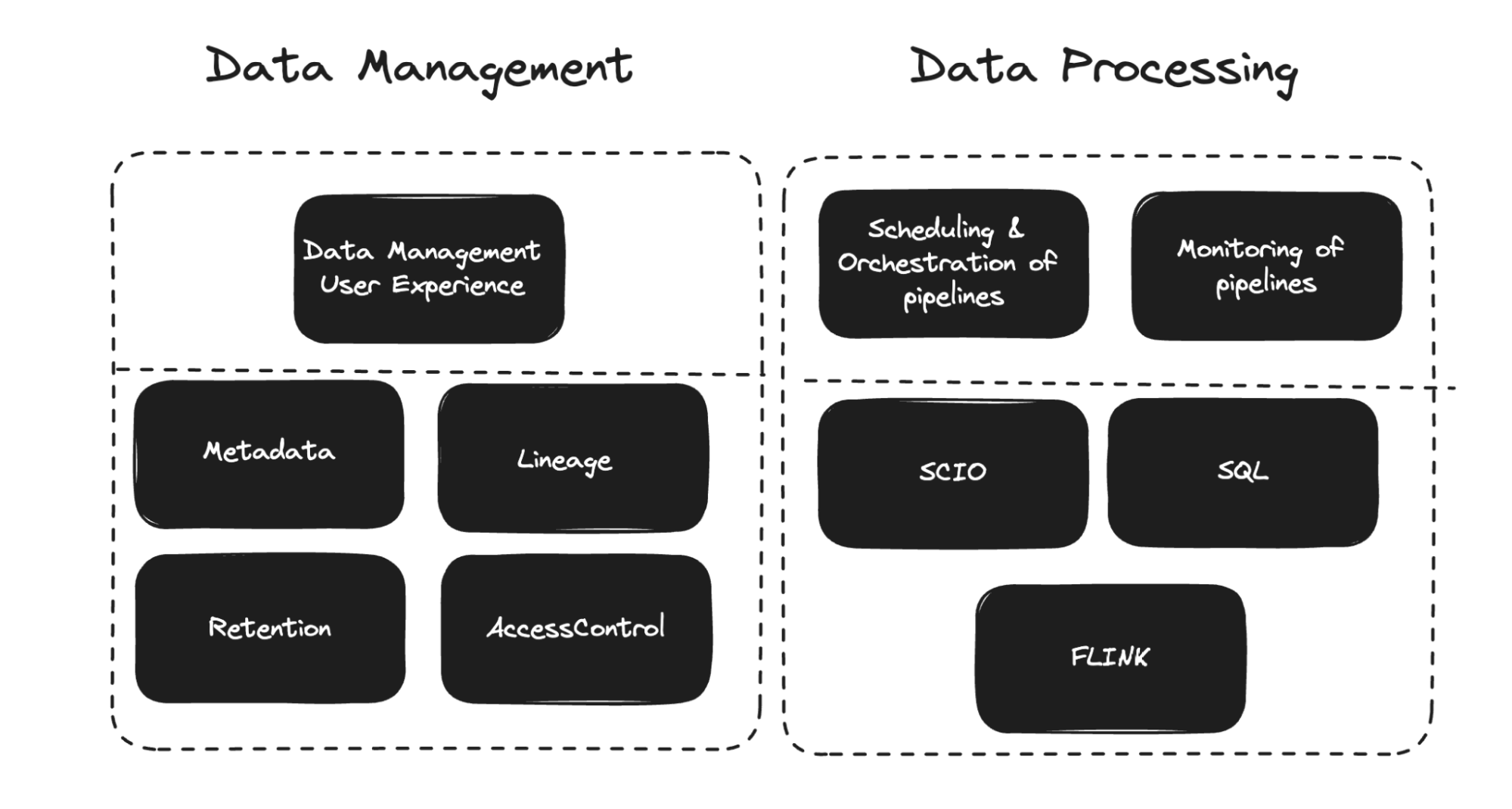
The scheduling and orchestration of workflows are important elements of Data Processing. Once a workflow is picked up by the scheduler, it’s executed on BigQuery, or both Flink or Dataflow clusters. Most pipelines make the most of Scio, a Scala API for Beam.
Data pipelines generate information endpoints, every adhering to a selected schema and presumably containing a number of partitions. These endpoints are geared up with retention insurance policies, entry controls, lineage monitoring, and high quality checks.
Defining a workflow or endpoint includes customized K8 operators, which assist us to simply deploy and keep advanced buildings. In that method, the useful resource definition lives in the identical repo because the pipeline code and will get deployed and maintained by the codeowners.
Monitoring choices embody alerts for information lateness, long-running or failing workflows, and endpoints. Backstage integration facilitates simple useful resource administration, monitoring, price evaluation, and high quality assurance.
Building an information platform is non-trivial — it must be versatile sufficient to fulfill quite a lot of totally different use instances, aligning with price effectiveness and return on funding targets, and on the identical time retaining the developer expertise lean. The information platform must be simple to onboard to and have seamless improve paths (no one likes to be disrupted by platform upgrades and breaking modifications). And the platform must be dependable — if groups have the expectation to construct enterprise essential logic on prime of your platform, we deal with the platform as a essential use case as nicely.
There are a number of methods to raise engagement together with your product:
- Documentation (which is simple to search out). We all have been in conditions the place, “I remember reading about it, but I don’t remember where.” It ought to be simpler to search out documentation than to ask a query (contemplating the ready time).
- Onboard groups. There isn’t any higher approach to study your product than to start out utilizing it your self. Go to customers and embed there. Learn about totally different use instances, guarantee that your product is simple to make use of in all attainable environments, and produce the learnings again to the platform.
- Fleetshift the modifications. People love evolving and making modifications to their infrastructure and having the code being highlighted as deprecated, proper? Not actually. That is why we must always automate all attainable toils and migrations. Plan to take care of dangers. Make time to assist your clients.
- Build a group the place individuals are free to ask questions and the place there are devoted goalies to reply these questions. Answering group questions shouldn’t be left to free will, however ought to as an alternative be inspired and brought significantly. At Spotify we have now a slack channel #data-support, the place all information questions are addressed.
Our Data Platform has come a great distance, and continues to evolve. At the very starting, we have been a number of individuals, a part of one group. We ran the pipelines on-premise, working the largest Hadoop cluster in Europe. We are actually 100+ engineers engaged on constructing the Spotify information platform on GCP, with information assortment, administration, and processing capabilities.
There isn’t any system or script to arrange an information platform. A great way to start out is by aligning your organizational wants together with your investments. These wants grow to be the drivers on your platform’s constructing blocks, and will change over time. Make certain the challenges are clear — outline clear targets and set clear expectations — it can make it easier to to have the fitting assist out of your group and to be on the trail for achievement.
Get nearer to your customers, have a transparent means by which clients and stakeholders can attain out and provide you with direct suggestions — it can set the stage to create a group round your platform. Finally, you would not have to start out massive: simply begin someplace then evolve, iterate, and be taught.
Tags: Data
[ad_2]