{kind=link}
[ad_1]
November 7, 2023
Spotify runs paid advertising and marketing campaigns throughout the globe on varied digital advert platforms like Facebook, Google UAC (show banners), TikTookay, and extra. Being environment friendly with our advertising and marketing finances is crucial for maximizing the return on advert spend in order that we will proceed to develop adverts that talk the worth of Spotify to customers and non-users alike. Running and managing paid advertising and marketing campaigns at a world scale will not be a straightforward job — as people and entrepreneurs, it’s extremely troublesome to catch all of the attainable edge instances. And so we requested ourselves, How can we mix a scalable method — utilizing instruments like automated artistic era, machine studying, and advert interplay information — with Spotify’s unmatched content material library? That mixture might permit us to:
- Better convey Spotify’s values
- Make our efficiency advertising and marketing extra environment friendly
- Handle the dimensions of the tens of hundreds of adverts we run globally
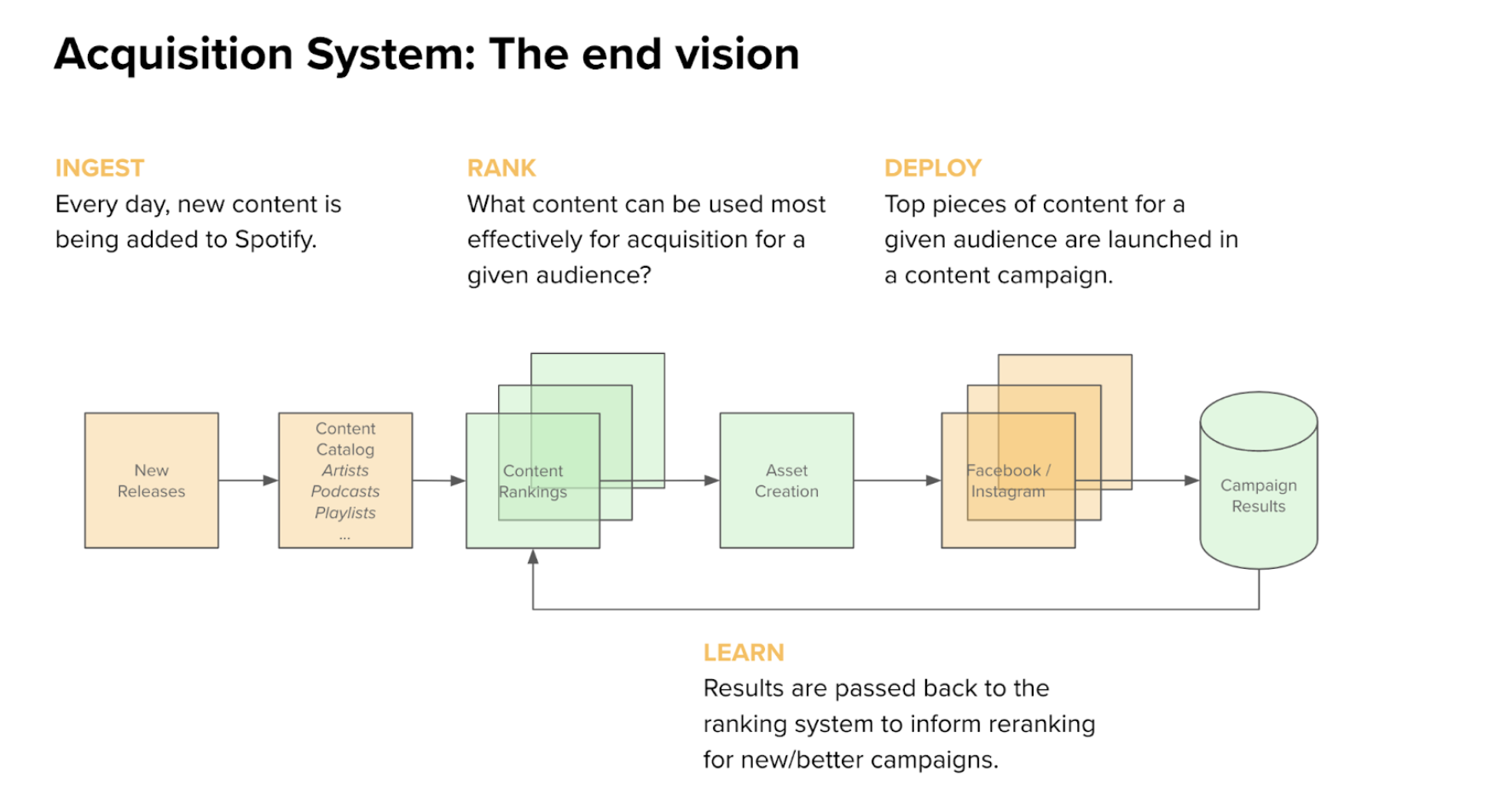
Prior to 2019, we performed just a few exams of an off-platform content material advertising and marketing speculation that resulted in various ranges of success. A guide check in H1 2019 once more demonstrated the potential of bringing in incremental customers utilizing content material adverts; the following step was to concentrate on scalability. Could we construct a system that robotically generated content-based adverts, load it to our digital advertising and marketing channels, and observe the way it performs and make modifications on the fly? At the time, off-the-shelf parts might get us partway there, however we nonetheless lacked capabilities like artistic asset era at scale and a way for reliably estimating and fine-tuning our goal metric — value per registration (CPR) per market (mainly, the typical amount of cash we need to spend to accumulate a brand new person). So we started to brainstorm. First, we thought concerning the system habits we sought and conceived a fundamental loop of 5 levels:
- Ingest
- Rank
- Deploy
- Learn
- Repeat
The technical method to automated content material advert era
With this in thoughts, we set about automating every step of the Acquisition System one by one. We first centered on the content material era factor; for any given advertising and marketing alternative on, say, Facebook, there are dozens of mixtures of side ratios and sizes for advert slots. When you consider styling and graphical parts like cowl artwork, you could find your self taking a look at a whole bunch of particular person artistic advert property for a single marketing campaign in a single language or area, and that’s even earlier than you sort out points like internationalization. We knew from the beginning that if we couldn’t scale content material era, the off-platform aspect of the hassle would stall within the beginning gate.
Initially, we used some slightly fundamental templating, constructing a Java-based backend service that may retrieve content material parts from our metadata companies and layer them right into a static picture with fundamental styling utilizing our shade picker, to generate static imagery:

This service was capable of generate the photographs as proven above, nevertheless it restricted us to very simplistic static templates.
What about animation?
Static adverts could be helpful in sure eventualities — e.g., when the tip person’s bandwidth is at a premium — however generally, we wish movement to assist have interaction the person. Simple animations could be generated with data of translation routines and Bezier curves. But extra complicated artistic therapies, which must be referenced by JSON recordsdata, had been past the easy system constructed for hardcoded templates. Additionally, we encountered points with right-to-left scanning for languages like Arabic, and there have been artistic limitations for our designers. We thought-about a number of off-the-shelf options already in use at Spotify, like Lottie and Blender. However, on the time, Lottie couldn’t assist our templating wants at scale, and Blender was an unfamiliar instrument for our artistic groups seeking to push the bounds of compelling content material, rapidly.
Adobe After Effects — the movement graphics instrument — appeared like a pure selection, given its familiarity to our groups and its skill to supply the artistic freedom our designers wanted to generate work that would actually catch somebody’s consideration. Most importantly, it offered us a mechanism to create templates that would then be used to generate the handfuls of side ratios and sizes we wanted. There was only one drawback: After Effects is a desktop instrument, and we had been unable to fireplace up a desktop software in a GCP compute occasion anytime we wished.
Or might we?
Adobe supplies a useful helper executable that lets customers hearth up the render pipeline with a command line, for instance:
aerender -project c:projectsproject_1.aep -comp "Composition_1" -s 1 -e 10
-RStemplate "Multi-Machine Settings" -OMtemplate "Multi-Machine Sequence"
-output c:outputproject_1frames[####].psdIt felt like we had been getting someplace!
Unfortunately, it nonetheless required issues like a number node with After Effects put in, compositing property out there regionally to the OS picture, and so forth. So whereas it was shut, After Effects nonetheless wasn’t fairly what we wished.
Our subsequent choice? Enter nexrender, an open supply venture that extends aerender right into a first-class batchable system. Here, we will script file actions from community places, specify a number of output codecs abruptly, and handle headless aerender nodes to slice up our batch jobs effectively.
With nexrender, we had been lastly capable of mix all of the items that we wished to automate the creation of visuals.
Now that we had the artistic parts, what content material would we embrace? And the place? And what advert will we play for, say, a Gen Z viewers within the EMEA area? How will we determine all this out?
Content rating
Content rating is the place the magic of information and machine studying (ML) comes into image. We leveraged the facility of machine studying mixed with the precious information sources out there to us to rank the content material each day. We then fed the ranked content material to the advert artistic era system to draw particular goal audiences on completely different advertising and marketing channels, encouraging them to hitch Spotify and revel in what we have now to supply.
It’s customary trade apply to gather information factors on key advert efficiency metrics together with clicks, impressions, app installs, registrations, subscriptions, and so forth., in order that advertising and marketing campaigns could be optimized to earn the perfect return on spend attainable. We began designing and implementing information pipeline parts that may question from completely different advert platform APIs in addition to cell measurement companion (MMP) APIs to fetch these advert efficiency metrics and attribution information, permitting us to arrange a top quality dataset. As alluded to above, one of many distinctive promoting propositions (USPs) of this venture was to leverage the huge Spotify content material catalog information about all of the artists on our platform around the globe. Therefore, combining the native recognition of the artists per nation from this content material catalog with the collected efficiency metrics of the marketing campaign adverts would give the content material rating mannequin stable information to be educated with to churn high quality rankings.
But these content material rankings, that’s, which artist to characteristic through which nation’s advertising and marketing marketing campaign advert, additionally had one other dimension — advert artistic template. Having a system for combining artists with templates was simply the primary a part of the problem. Knowing which of the a whole bunch of hundreds of artists to characteristic together with choosing a template from a myriad of design selections was the opposite a part of the problem.
Now, you is perhaps asking, Couldn’t we create all the probabilities after which let the already subtle audience-targeting algorithms constructed into social media and search platforms optimize that choice for us primarily based on the best-performing generated advert creatives?
While these algorithms may match when you will have a human-scale variety of 4 to eight adverts to optimize throughout, they aren’t essentially designed for orders of magnitude with extra choices (probably limitless!) that we’d need to think about. As a outcome, a preranking step is required to establish the perfect advert creatives for trafficking after which measuring the efficiency thereafter to optimize the marketing campaign efficiency.
Content rating, the heuristic means
So how will we truly go about preranking? Let’s first simplify the issue, solely selecting a specific set of artists to characteristic (it’s illustrative, and there’s loads of complexity right here already). For any advert marketing campaign, we want the set of artists we select to maximise the attain, conversion, and value effectivity of the marketing campaign that they’re featured in. At Spotify, we all know so much about our artists — as an example, their recognition amongst our customers. However, we don’t understand how nicely they attain, convert, or value inside a third-party platform. We additionally don’t know which customers are being proven our adverts straight, so the conversion charge or value per impression on at some point won’t imply the identical factor on a unique day. Finally, value from at some point to a different might fluctuate primarily based on market forces like demand or music-streaming rivals.
With these points in thoughts, we wanted to discover a method to estimate the mixture of attain, conversion, and price effectivity of the completely different artists in every marketing campaign, with out truly having interpretable numbers from every.
Our first perception was to leverage the knowledge from the advert platforms themselves, since these calculations weren’t straight out there to us. Specifically, we had been keen on every platform’s specific ad-placement algorithms and the way they rebalance adverts for every of their customers. We used the share of registrations coming from every artist as a top quality rating for that artist.
From there, we might apply the algorithms we constructed to unravel the preranking drawback, however earlier than we had been capable of dive into it, we wanted to take two elements into consideration:
- How will we mix the form of high quality rating we described with different data we have now concerning the artist, e.g., recognition?
- How will we estimate what the standard scores of various artists are if we haven’t but noticed them?
To reply these questions, we glance to our first heuristic.
Our first heuristic took three calculations or information factors and mixed them to robotically resolve which artists to characteristic in campaigns — recognition, share of registrations, and range. The first information level was to make use of recognition to construct up a set of eight artists to position right into a marketing campaign. We then noticed how these artists carried out utilizing the share-of-registrations metric we described above. Once we had these, we used our data graph of artist similarity to assist predict the standard rating comparable artists may need. Finally, we evaluated the efficiency and optimized our selections primarily based on each recognition and differentiation from the opposite artists and adverts that remained. This allowed the heuristic a managed method to discover a various pool of adverts and artists.
Content rating, the ML means
While the primary heuristic used a easy, fastened means of weighing these three elements (i.e., one-third every), we began questioning if there was a greater means for every issue to contribute in predicting the standard of artists used within the adverts? So we remodeled this query right into a supervised ML drawback, the place options of every artist had been used to foretell the share of registrations, and recognition was now added as one of many options to be taught from. This additionally gave us a means so as to add options we didn’t think about earlier than within the heuristic mannequin, comparable to these of the marketing campaign itself — metadata like marketing campaign market, advert artistic dimension, working system, template theme and variation, and so forth.
The heuristic allowed us to get off the bottom with a operating begin, however the ML resolution allowed us to mix the covariates of the issue right into a extra highly effective algorithm that netted us 9% extra month-to-month lively customers (MAUs) over the heuristic through the lifetime of its operation.
We used the XGBoost library (through the Spotify Kubeflow managed service provided by the Platform mission), which makes use of gradient boosting framework internally to implement the ML algorithm. The mannequin was educated with the information factors of assorted options associated to campaign-level data, artist metadata, and the advert artistic template information. Each day, the mannequin educated with the historic information of those options over a sure lookback window and predicted two primary goal variables.
In the case of the predictive mannequin for Spotify free-tier adverts:
- reg_percentage: Percentage of Spotify person registrations that the ranked artist will contribute to
- relative_cpr_ratio: Ratio/share of the ranked artist within the general CPR of a advertising and marketing marketing campaign
In the case of the predictive mannequin for Spotify premium-tier adverts:
- sub_percentage: Percentage of Spotify premium person subscriptions that the ranked artist will contribute to
- relative_cps_ratio: Ratio/share of the ranked artist within the general value per subscription (CPS) of a advertising and marketing marketing campaign
We determined to make use of relative metrics as a substitute of absolute metrics as a result of uncooked metrics — comparable to variety of registration or subscription occasions and their unit prices — depend upon exterior market elements (comparable to provide and demand for adverts on platforms) which might be arduous to mannequin.
Once the mannequin was prepared, we proved our speculation that an ML mannequin would outperform the heuristic mannequin by operating an A/B check with the heuristic mannequin set because the management and the ML mannequin set because the therapy in two areas for a length of three weeks. The outcomes had been clear, with the ML mannequin reaching a 4% and 14% cheaper CPR than the heuristic mannequin within the two areas. This was primarily on account of the truth that the adverts generated from the expected rankings from the ML mannequin had an 11% to 12% increased click-through charge (CTR) than the heuristic mannequin, for the reason that ML mannequin was educated with richer coaching information with the next variety of options.
With the check outcomes this clear, the pure selection was for us to productionize the ML mannequin to care for content material rating throughout all lively areas the place we ran advertising and marketing campaigns.
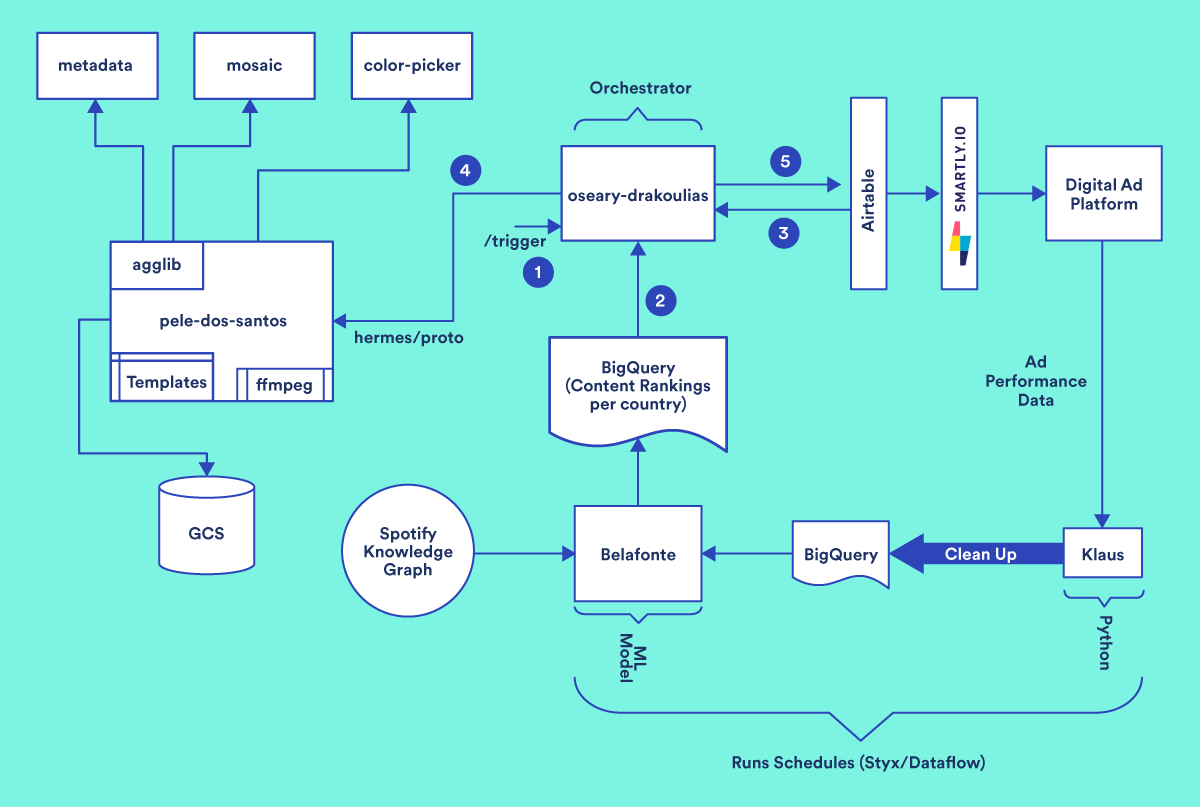
This is the end-to-end structure of the answer we productionized:
Technical challenges & takeaways
Throughout our collective effort on this venture, we discovered successes and difficulties. Here are a few of our most noteworthy challenges and takeaways:
Challenge 1: Orchestrating the era of property.
Moving from Java templates to After Effects turned asset era from one thing that may very well be finished inline in an API name to one thing that wanted rendering asynchronously. Scaling the render staff up and down in response to the amount of property to be generated was additionally a problem.
Takeaway 1: Changes affecting the structure can and can occur.
Systems are initially designed with sure assumptions primarily based on the knowledge we have now on the time. When new data inevitably comes alongside, it’s a good suggestion to evaluate how you can incorporate the brand new necessities into the design as nonintrusively as attainable and to maneuver incrementally towards that. Systems constructed with modular parts could make issues simpler, although it’ll by no means be attainable to foretell all of the eventualities that may put stress on the design.
Challenge 2: Dependency on advert platform APIs for ingesting advert efficiency metrics.
To feed the ML content material rating mannequin with good-quality coaching information, the information pipelines need to fetch advert efficiency metrics from platform APIs each day. If there’s a problem retrieving information from these platform APIs, our rating flows may break, or in the end recommend content material that’s not ideally suited.
For instance, in a few cases, a Facebook API outage brought about disruptions in our information pipelines, which resulted within the ML mannequin not with the ability to prepare and churn out content material rankings till Facebook’s advertising and marketing API was again to regular.
Takeaway 2: Always discover a backup resolution when exterior dependencies break.
It’s essential to have a backup resolution in case of an unexpected scenario, particularly when it’s about an exterior dependency. As a workaround for such a situation, we determined to proceed preserving the artist rankings from the day gone by, because the ML mannequin wouldn’t have perception into the newest day’s advert efficiency to make modifications to the rankings.
Challenge 3: Identifier for Advertisers (IDFA) implications from iOS model 14.5 onward.
In the summer season of 2021, Apple unveiled IDFA, which modified the panorama of the advert tech trade perpetually when it comes to which information factors advertisers can gather and use. For us, this meant we’d now not rely blindly on getting user-level/log-level advert efficiency information to optimize the marketing campaign. But as a result of our ML mannequin educated on the aggregated information over a lookback window, the change didn’t have an effect on us adversely.
Takeaway 3: Anticipate modifications within the trade and assess the system accordingly.
The second we had been made conscious that IDFA can be activated for iOS model 14.5 onward, we evaluated our ML mannequin output through offline analyses for any detrimental influence on mannequin efficiency. It turned out in our favor: the mannequin efficiency wouldn’t be impacted negatively. So it’s at all times a good suggestion to arrange methods to evaluate the system in case of disruptions and to consider different options. .
Challenge 4: MMP migration from Adjust to Branch.
Spotify determined emigrate from Adjust to Branch for the popular deep linking and attribution companion as described intimately in this Spotify Engineering weblog put up. This meant updating all our information pipelines and our ML mannequin to eat Branch-powered advert metrics after which calibrating the system for content material rating in the very best method.
Takeaway 4: Design a system that permits for updates on the fly and ensures the identical efficiency.
We carved out time to confirm that consuming advert efficiency attribution information from Branch as a substitute of Adjust didn’t lead to efficiency implication of the ML rating mannequin, and we got here up with detailed technical specs of the duties concerned. Once we confirmed with our stakeholders (Performance Marketing and Marketing Analytics) that it was OK to cutover from Adjust to Branch and that the advert metrics had been flowing accurately from Branch, we made the mandatory modifications in our information pipelines and ML mannequin to finish the migration effort. As anticipated, the efficiency of the ML mannequin remained as sturdy as earlier than.
Challenge 5: Incorporating range of artists within the ML mannequin.
It turned out that naive methods to encode the range of the group of artists within the marketing campaign into our supervised studying algorithm didn’t assist — however this drawback, generally known as slate suggestion, is troublesome. It’s a really attention-grabbing problem with broad software, and we’re at all times searching for new drawback solvers!
Takeaway 5: In ML, with the ability to iterate from less complicated to extra complicated is a superpower.
We now not dwell in a world the place the groups that write ML algorithms can wait till the core performance of the platforms and a number of methods round it stabilize. Backends, pipelines, processes, and even insurance policies of complete industries (cue IDFA) evolve and alter. At the identical time, essentially the most impactful methods nonetheless have to react to information. So creating ML methods is a ballet, generally requiring quiet heuristic strategies with few shifting components, different instances bringing the entire orchestra of cross-platform tech, like artist embedding vectors. The move supporting this vary of growth is crucial.
Conclusion & acknowledgements
Our journey to constructing a posh automated content material administration system began with a tiny speculation: “We can make Spotify’s Performance Marketing more efficient by leveraging the power of engineering and content.” This product was notably complicated, requiring cross-functional efforts between Engineering and Marketing to unravel complicated actual issues. In the tip, we developed an end-to-end automated system that would generate content material adverts and optimize them constantly. We are very proud to say that solely a handful of tech firms absolutely automated the Performance Marketing cycle globally. We thank all crew members who labored arduous to carry this product to the world.
[ad_2]