{kind=link}
[ad_1]
November 17, 2023 Published by Brian Regan, Desislava Hristova, Mariano Beguerisse-Díaz

TL;DR
We developed a Named Entity Disambiguation (NED) technique to help human curators find and correcting rare errors in a music catalog. This system can detect misattribution, when releases which might be incorrectly attributed to an artist discography and predict appropriate relocations, and duplication, when the discography of an artist is incorrectly cut up.
To do that, the system combines audio vector representations with metadata-based options in a machine studying (ML) system. Combining audio and metadata fashions outperforms fashions based mostly on audio or metadata alone. Through a set of “in-the-wild” experiments with Subject Matter Experts (SMEs), we exhibit the potential of such proactive curation programs to save lots of effort and time by directing consideration the place it’s most wanted to make sure that our catalog is free from errors.
Named Entity Disambiguation at scale
Named Entity Disambiguation offers with the issue of mapping ambiguously named entities, corresponding to homonym music artists, to their right identifiers. For instance, on Spotify there are 11 artists named Witch (plus many others with Witch within the identify). When a brand new launch by a Witch is submitted and not using a distinctive artist identifier, we should decide of the place to put it: Is it by the Zambian psychedelic band, the US doom steel band, one of many different Witches, or a brand new Witch? Given the extraordinarily giant volumes of music content material delivered to Spotify daily by suppliers that adjust from DIY artists by way of aggregators, all the best way to megastars by way of main labels, it’s inevitable that often a launch is incorrectly attributed.
In Music Information Retrieval (MIR), NED is often formulated as a multi-class classification downside with identified artist lessons. This formulation, which depends totally on audio characteristic representations, can’t be utilized to Spotify-scale catalogs with a big and even unknown variety of artists; a quantity that grows daily. State-of-the-art NED analysis has centered just lately on automation; nevertheless, a human-in-the-loop (HITL) paradigm is commonly essential to resolve extremely ambiguous circumstances, right automated choices, and guarantee high quality.
Our answer
In this paper, we current an ML-based semi-automated proactive curation system to detect and proper attribution errors in giant music catalogs. The system consists of two sub-models (which may be standalone programs): detects misattribution by splitting discographies with releases from a number of artists into single-artist discographies (Figure 1a), and one other detects duplication by deciding whether or not two discographies belong to the identical artist and must be merged (Figure 1b). Both programs depend on the music’s metadata and the acoustic similarity between releases, utilizing deep convolutional community embeddings of their mel-spectrograms and random forests.
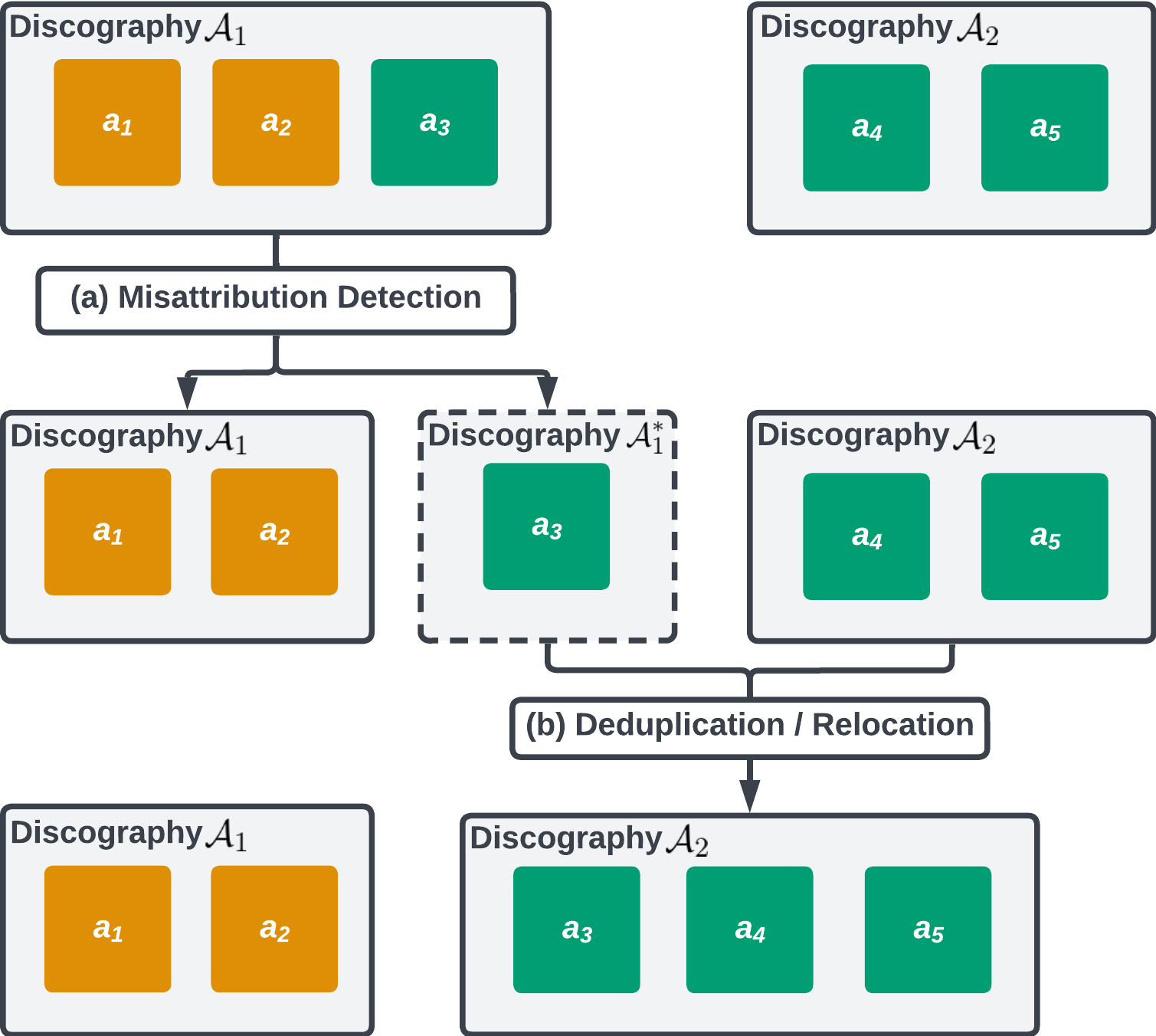
Figure 1: (a) We detect misattribution on every discography A. A misattributed launch a3 is cut up out from A1 into sub-discography A*1. (b) We contemplate all (sub-)discographies for deduplication; we merge A*1 into A2, which relocates any misattributed releases into the proper discography.
The system’s targets are to Ensure:
- Correct discographies, the place each launch inside a discography ought to credit score the identical artist.
- Complete discographies, the place artist’s releases shouldn’t be cut up throughout a number of discographies.
Misattribution detection
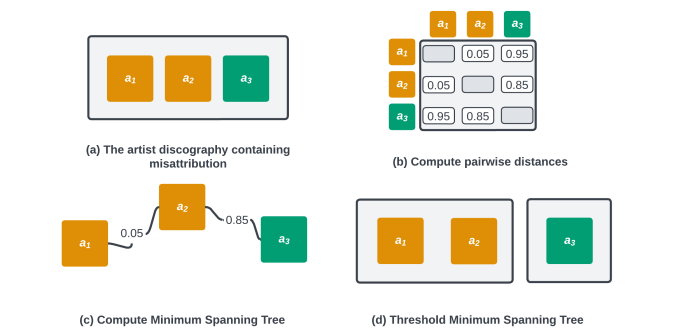
Figure 2: Steps to detect misattribution in an artist’s discography.
We educated a random forest utilizing historic corrections of artist misattributions to find out whether or not two releases attributed to the identical artist are actually by completely different artists. We can consider the output of this mannequin as a pairwise distance between all releases attributed to an artist (Figure 2b). To forestall false positives that may come up, for instance, when an artist’s sound adjustments over time, we assemble a Minimum Spanning Tree (MST) between all releases (Figure 2c). Applying a threshold to the MST to chop edges with lengthy distances splits the discography into elements that correspond to the completely different artists current within the discography (Figure 2nd). If we’re unable to chop the MST as a result of there aren’t any lengthy edges, we assume that the discography comprises no misattributions.
Duplicate detection
The aim of de-duplication is to merge current discographies or sub-discographies that belong to the identical artist (e.g. launch a3 in Figure 1). This course of consists of two steps: (1) producing deduplication candidates by way of a blocking technique, and (2) figuring out whether or not pairs of discographies belong to the identical artist.
We use Elasticsearch to generate candidates; these are sometimes homonyms, or have comparable names (e.g. Prince, Princess and Prince of Funk). We use a random forest educated on historic corrections of duplicate discographies to find out whether or not two discographies within the block are prone to belong to the identical artist.
Experiments and evaluations
Audio and metadata characteristic ablations
Both the misattribution and the duplicate detection fashions use a mixture of metadata options (corresponding to overlap of collaborators, language of efficiency or music label) and audio vector representations. Our experiments present {that a} mixture of each performs finest; audio options dominate the pairwise misattribution mannequin, and including metadata will increase common precision by 2% (Figure 3a). Interestingly, this sample is reversed within the duplicate detection system, during which metadata options drive the efficiency of the system, and including audio options will increase common precision by 6% (Figure 3b).
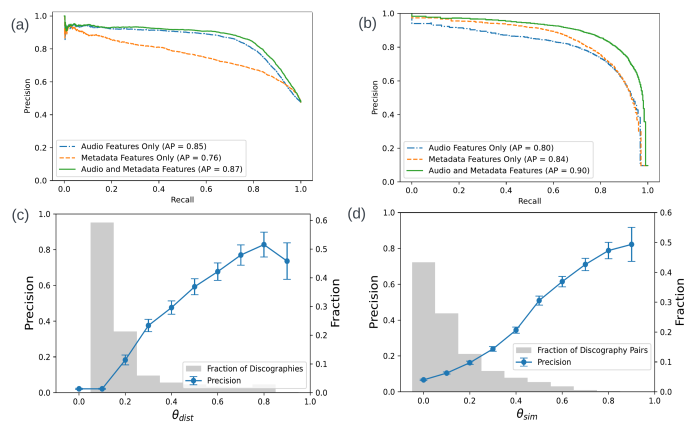
Figure 3 Evaluation: (a) – (b): Precision-Recall curves in offline experiments with combos of audio and metadata options for misattribution detection (a) and deduplication (b). Average precision (AP) is reported within the legend for every set of options. (c) – (d): Annotation experiment outcomes for misattribution detection (c) and deduplication (d). Precision is calculated for every threshold bucket and reweighed by the distribution of predictions proven on the second y axis.
Test driving our system with Subject Matter Experts (SMEs)
We teamed up with our annotations staff and sampled ~1K examples every for misattribution and deduplication duties. We requested SMEs to annotate examples of misattribution and duplicate discographies as by the identical artist or by completely different artists. Figure 3 c and d reveals the precision at completely different thresholds of the fashions; as the brink goes up, the fraction of samples (and potential error detections) decreases whereas the precision will increase. This trade-off permits SMEs to discover a sweet-spot that balances precision and recall for catalog curation.
Then we ran our detection duties in sequence (as described in Figure 1) to robotically predict appropriate relocations of misattributed contect utilizing the deduplication mannequin. We obtain a most precision of 45% when each the misattribution step and deduplication (relocation) step have a excessive threshold (representing 17% of the pattern). This signifies that roughly half the time, catalog curation specialists don’t should spend time on the lookout for the fitting place to put a mismatched launch, main to very large time financial savings. The relocation activity is notoriously tougher as a result of it inherits the uncertainty and efficiency of every sub-system. Additionally, numerous misattributed releases won’t belong anyplace, and can turn out to be standalone discographies as a result of they belong to artists which might be new to the catalog.
Conclusion
Although discography errors are uncommon, you will need to reduce them as a lot as attainable. Systems such because the one we current in our paper that depend on ML and cautious information modeling are one device amongst many who platforms can use to make sure their catalog is right, and to safeguard the expertise of customers and artists. The energy of this method is that it could possibly scan a big catalog effectively, direct the eye of human reviewers to the place it’s most wanted, and counsel corrections. These benefits make our system a key a part of efficient proactive catalog curation methods.
For extra element, please verify our paper:
Semi-automated Music Catalog Curation Using Audio and Metadata
Brian Regan, Desi Hristova, Mariano Beguerisse Díaz
ISMIR 2023
[ad_2]